
GaussianDreamer:通过桥接 2D 和 3D Diffusion Model,实现从 Text 到 3D 高斯的快速生成
GaussianDreamer: Fast Generation from Text to 3D Gaussians by Bridging 2D and 3D Diffusion models
GaussianDreamer: 通过桥接 2D 和 3D Diffusion Model,实现从 Text-to-3D高斯 的快速生成
[!abstract]
最近,从文本提示(prompt)生成 3D 资产(asset)的技术取得了令人印象深刻的结果。无论是 2D 还是 3D 扩散模型(Diffusion Model) 都可以根据提示生成不错的 3D 对象。
- 3D Diffusion Model 具有良好的 3D 一致性,但由于可训练的 3D 数据昂贵且难以获取,其质量和泛化能力有限。
- 2D Diffusion Model 具有强大的泛化和精细生成能力,但很难保证 3D 一致性。
本文试图通过最近的显式和高效的 3DGS 表示来融合这两种类型的扩散模型的能力。提出了一种快速的 3D 对象生成框架,命名为 GaussianDreamer,其中 3D Diffusion Model 为初始化提供先验 (prior),而 2D Diffusion Model 丰富了几何和外观。引入噪点生长(noisy point growing)和颜色扰动(color perturbation)来增强初始化的高斯模型。
我们的 GaussianDreamer 可以在一个 GPU 上在 15 分钟内生成高质量的 3D 实例或 3D 头像,比以前的方法快得多,而生成的实例可以直接实时渲染。演示和代码可在 https://taoranyi.com/gaussiandreamer/ 上找到。

图 1:我们提出了一个简单而高效的框架,称为 GaussianDreamer。它通过 GS 将 3D 和 2D Diffusion Model 连接起来,具有 3D 一致性和丰富的生成细节。我们的方法可以在单个 GPU 上在 15 分钟内完成训练,并实现实时渲染。
1 引言
在传统的流程中,3D 资产生成一直是一项昂贵且专业的工作。最近, Diffusion Model [57]在创建高质量和逼真的 2D 图像方面取得了巨大成功。许多研究工作[70, 9, 50, 31, 76, 6, 77, 81, 67, 90, 2, 23, 46, 14, 12]尝试将 2D Diffusion Model 的能力转移到 3D 领域,以便简化和辅助 3D 资产创建的过程,例如最常见的文本到 3D 任务。
实现这一目标有两个主要方法:
- 使用3D数据训练新的 Diffusion Model [23, 46, 14, 12](即3D Diffusion Model ),3D Diffusion Model 具有强大的 3D 一致性,但在扩展到大型生成领域时存在困难,因为通常很难且昂贵获取 3D 数据。当前 3D 数据集的规模远小于 2D 数据集,这导致生成的 3D 资产在处理复杂的文本提示和生成复杂/精细的几何和外观方面存在不足。
- 将2D Diffusion Model 提升到3D[70, 9, 50, 31, 76, 6, 77, 81, 67, 90, 2, 57]。受益于 2D Diffusion Model 的大数据领域,可以处理各种文本提示并生成高度详细和复杂的几何和外观。然而,由于 2D Diffusion Model 不知道相机视图,生成的 3D 资产很难形成几何一致性,尤其是对于结构复杂的实例。(这里点出了缺少几何一致性的原因)
本文提出使用最近的 3D GS [24]来桥接上述两种方法,同时具有来自 3D Diffusion Model 的几何一致性和来自 2D Diffusion Model 的丰富细节。
3D 高斯是一种高效且明确的表示方法,由于点云结构的固有特性,它本质上具有几何先验(prior)。具体而言:
- 我们在实现中使用了两种类型的 3D Diffusion Model :Text-to-3D 和 Text-to-motion,例如 Shap-E [23]和 MDM [72],以生成粗糙的 3D 实例。
- 基于粗糙的 3D 实例,初始化了一组 3D 高斯。我们引入了噪点生长和颜色扰动两种操作,以补充初始化的高斯,以进一步丰富 3D 实例。
- 然后,通过得分蒸馏采样[50](Score Distillation Sampling,SDS)损失(loss),3D 高斯可以通过与 2D Diffusion Model 的交互进行改进和优化。由于来自 3D Diffusion Model 和 3D GS 本身的几何先验,训练过程可以在很短的时间内完成。
生成的 3D 资产可以被实时渲染,而无需转化为Mesh等结构。(该方法没有进一步生成Mesh)
我们的贡献可以总结如下:
- 我们提出了一种名为 GaussianDreamer 的 Text-to-3D 的方法,通过高斯分离桥接 3D 和 2D Diffusion Model ,既享受 3D 的一致性又具有丰富的生成细节。
- 为了进一步丰富内容,我们引入了噪点生长和颜色扰动来补充初始化的 3D 高斯模型。(⭐这一步可以迁移到其他工作)
- 整体方法简单而有效。在一个 GPU 上,可以在 15 分钟内生成一个 3D 实例,比以前的方法快得多,并且可以直接实时渲染。
2 相关工作
2.1 3D 预训练 Diffusion Model
3D Pretrained Diffusion Model
最近,使用 Diffusion Model 进行text-to-3D 资产生成取得了巨大的成功。
目前,主要分为将2D Diffusion Model 提升到3D和3D Pretrained Diffusion Model 两种,区别在于所使用的训练数据是2D还是3D。
我们论文中所称的3D Pretrained Diffusion Model [23, 46, 12, 14],简称为3D Diffusion Model ,是在 Text-3D pair上进行预训练的模型。 预训练后,它们可以通过推理生成3D资产,像Point-E [46]和Shape-E [23]这样的模型可以在几分钟内生成3D资产。
除了从文本生成3D资产外,还有一些方法是基于 Text-Motion 数据,通过3D Diffusion Model [72, 89, 53, 88, 7, 25, 91, 10, 1, 63]生成动作序列(motion sequences)。通过在Text-Motion pair上进行预训练,这些模型可以为不同的文本生成合理的动作序列。生成的动作序列可以基于网格表示转换为SMPL(Skinned Multi-Person Linear)模型[38],但不包括纹理信息。在我们的方法中,我们可以使用不同的文本提示来绘制转换后的SMPL模型。
2.2 将 2D Diffusion Model 提升至3D
在 text-to-3D 资产生成方法中[8, 61, 62, 73, 80, 85, 92, 56, 51, 39, 19, 47, 48, 22, 87, 15, 68],除了使用 3D Pretrained Diffusion Model 外,将 2D Diffusion Model 提升到 3D 是一种无需训练的方法。
此外,由于 2D 图像数据丰富,该方法生成的资产具有更高的多样性和保真度。一些单图像到 3D 的方法[71, 33, 34, 52, 65, 32, 66, 59, 35, 37, 83, 79, 82, 78, 17]也采用了类似的思想。DreamFusion[50]首先提出了 SDS(得分蒸馏采样)方法,即使用 2D Diffusion Model 更新 3D 表示模型。[76]提出了 SJC(得分雅可比链)方法将 2D Diffusion Model 提升到 3D。后续方法[31, 6, 77, 30, 69]在 DreamFusion 的基础上进一步提高了 3D 生成的质量。其中,生成的 3D 资产可能存在多面问题。为了解决这个问题,一些方法增强了不同视角的语义[2],并使用多视角信息[90, 67]来缓解这些问题。还有一些模型[58, 21, 42, 28, 44, 75, 81, 16]采用 CLIP[55]来将 3D 表示模型的每个视角与文本对齐。
2.2 3D 表示方法
在最近的时期,神经辐射场(NeRF)[43]在3D表示方面取得了令人印象深刻的成果,许多文本到3D资产生成的方法也采用了NeRF或其变种[3, 45]作为表示方法。一些方法[6, 31, 30, 12]使用了像DMTET [64]这样的显式可优化网格表示方法来降低渲染成本并进一步提高分辨率。除此之外,还有一些生成方法利用点云[46, 40, 74, 51]和网格[36]作为3D表示。
最近,3D GS [24]已被引入作为 3D 场景的表示方法,可以实现与基于 NeRF 的方法相媲美的渲染效果,并实现实时渲染。两个并行工作[70, 9]也使用 3D GS [24]构建了 3D 表示。DreamGaussian [70]使用单个图像作为条件生成 3D 资产,而 GSGEN [9]实现了从text-to-3D 的高质量生成。我们的方法与使用 3D GS 作为表示方法的思想类似,与可优化网格表示方法相比,显著降低了提高分辨率的成本,并实现了更快的优化速度。 我们可以在很短的时间内基于提示文本生成详细的 3D 资产。
3 方法
本节中
- 我们首先回顾了 2D 和 3D Diffusion Model 以及 3D 表示方法-3D GS [24]。
- 在第 3.2 节中概述了整个框架。
- 在第 3.3 节中,我们描述了在 3D Diffusion Model 的帮助下初始化 3D 高斯函数的过程。
- 在第 3.4 节中描述了使用 2D Diffusion Model 进一步优化 3D 高斯函数的过程。
3.1 初步
Preliminaries
3.1.1 DreamFusion
DreamFusion[50]是将2D Diffusion Model 提升到 3D 的最具代表性的方法之一,它提出通过预训练的2D Diffusion Model $\phi$,利用分数蒸馏采样损失(score distillation sampling (SDS) loss)来优化三维表示。
具体来说,它将 MipNeRF[3]作为三维表示方法,并对其参数 $\theta$ 进行优化。称渲染方法为 $g$,渲染后的图像结果为 $x = g (\theta)$。为了使渲染图像 $x$ 与从扩散模型 $\phi$ 中得到的样本相似,DreamFusion 使用了一个评分估计函数(scoring estimation):$\hat{\epsilon}{\phi}(\mathbf{z}{t};y,t)$,它可以预测给定噪声图像 $z_t$、文本嵌入 $y$ 和噪声水平 $t$ 的采样噪声 $\hat{\epsilon}_{\phi}$ 。
通过测量添加到渲染图像 $x$ 中的高斯噪声 $ε$ 与预测噪声 $\hat{\epsilon}_{\phi}$ 之间的差异,该评分估计函数可为参数 $\theta$ 的更新提供方向。梯度计算公式为
$$
\nabla_\theta\mathcal{L}{\mathrm{SDS}}(\phi,\mathbf{x}=g(\theta))\triangleq\mathbb{E}{t,\epsilon}\left[w(t)\left(\hat{\epsilon}_\phi(\mathbf{z}_t;y,t)-\epsilon\right)\frac{\partial\mathbf{x}}{\partial\theta}\right]\tag{1}
$$
其中,$w (t)$ 是加权函数(weighting function)
3.1.2 3DGS
略
3.2 整体框架
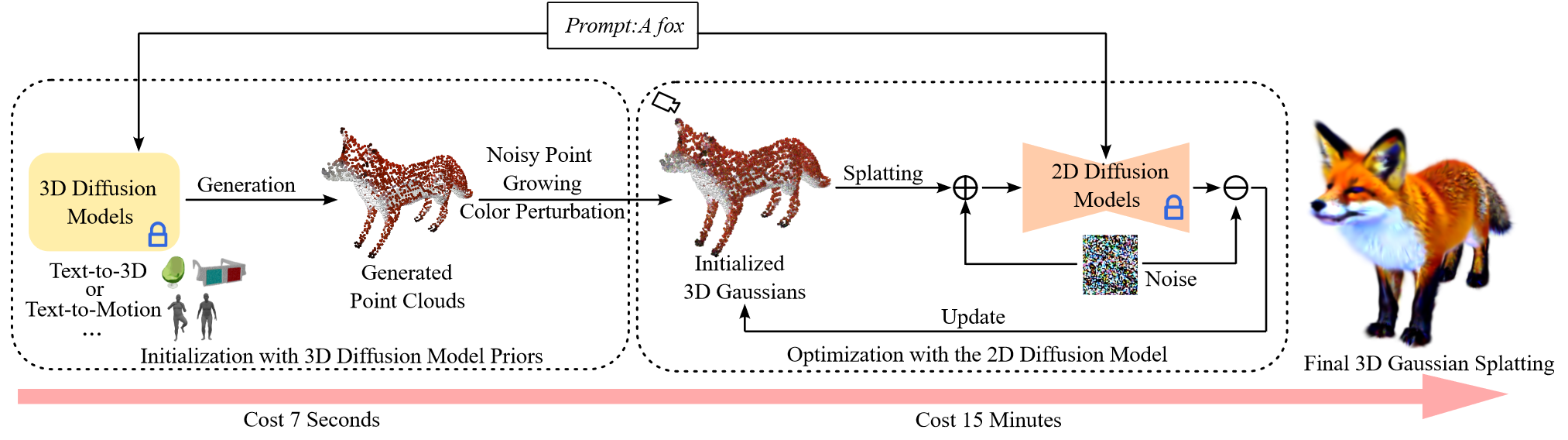
图 2:GaussianDreamer 的整体框架。
- 首先,我们使用 3D Diffusion Model 生成初始化的点云。在点云上执行噪点生长和颜色扰动后,我们使用它们来初始化 3D 高斯模型。
- 使用 SDS 方法 [50] 和 2D Diffusion Model 进一步优化初始化的 3D 高斯函数。
- 最后,我们使用 3D 高斯函数通过 3D GS [24] 渲染图像。我们可以使用各种 3D Diffusion Model 生成初始化的点云。在这种情况下,我们以 text-to-3D 和 text-to-motion Diffusion Model 为例。
我们的总体框架由两部分组成,即使用 3D Diffusion Model priors 进行初始化和使用 2D Diffusion Model 进行优化,如图 2 所示。
使用 3D Diffusion Model priors 来初始化 3D 高斯,我们使用 3D Diffusion Model $F_{3D}$ ,将 Text-to-3D 和 Text-to-Motion Diffusion Model实例化,根据文本提示 $y$ 生成三角形网格 $m$ ,可以表示为 $m=F_{3D}(y)$ 。一组生成的点云是从网格 $m$ 转换而来的。
然后通过噪点增长和颜色扰动,使用生成的点云初始化 3D 高斯 $\theta_b$ 。为了获得更好的质量,我们使用 2D Diffusion Model $F_{2D}$ 通过 SDS [50]和提示 $y$ 进一步优化初始化的 3D 高斯 $\theta_b$ ,得到最终的 3D 高斯 $\theta_f$ 。
通过“泼溅”产生的最终高斯 $\theta_f$ ,可以实时渲染目标实例。
3.3 高斯初始化与 3D Diffusion Model 先验
Gaussian Initialization with 3D Diffusion Model Priors
在本节中,我们主要讨论如何使用 3D Diffusion Model priors 来初始化 3D 高斯模型。
首先,我们使用 3D Diffusion Model $F_{3D}$ 基于提示 $y$ 生成 3D 资产。然后,我们将 3D 资产转换为点云,并使用转换后的点云来初始化 3D 高斯。
我们使用了两种类型的 3D Diffusion Model 来生成 3D 资产。下面,我们将解释如何使用这两种 Model 来初始化 3D 高斯模型。
3.3.1 Text-to-3D Diffusion Model
在使用基于文本的 3D 生成模型时,生成的 3D 资产采用多层感知器(MLP)来预测 SDF 值和纹理颜色。
为了构建三角形网格 $m$,我们在 MLP 中沿着大小为 $128^3$ 的规则 grid 查询顶点的 SDF 值。
然后我们查询 $m$ 每个顶点的纹理颜色。我们将 $m$ 的顶点和颜色转换为点云,表示为 $\boldsymbol{pt}_m(\boldsymbol{p}_m,\boldsymbol{c}_m)$。
- $p_m\in\mathbb{R}^3$ 表示点云的位置,它等于 $m$ 的顶点坐标;
- $c_m\in\mathbb{R}^3$ 指的是点云的颜色,与 $m$ 的颜色相同。
- 不过,所得到的颜色 $c_m$ 相对简单,而位置 $p_m$ 则比较稀疏。
3.3.1.1 噪点增长和颜色扰动
Noisy Point Growing and Color Perturbation
我们不直接使用生成的点云 $\boldsymbol{pt}_m$ 来初始化 3D 高斯分布。为了提高初始化的质量,我们在点云 $\boldsymbol{pt}_m$ 周围进行噪点增长和颜色扰动。
首先,我们计算曲面在 $\boldsymbol{pt}_m$ 上的 bounding box(BBox),然后在 BBox 内均匀生长点云 $\boldsymbol{pt}_r(\boldsymbol{p}_r,\boldsymbol{c}_r)$ 。 $\boldsymbol{p}_r$ 和 $\boldsymbol{c}_r$ 表示 $\boldsymbol{pt}_r$ 的位置和颜色。
为了实现快速搜索,我们使用位置 $\boldsymbol{p}_m$ 构建了一个 KD 树[4] $K_m$ 。根据位置 $p_r$ 与 KD 树 $K_m$ 中找到的最近点之间的距离,确定要保留哪些点。在此过程中,我们选择距离(normalized distance)为 0.01 的点。对于噪声点云,我们使它们的颜色 $\boldsymbol{c}_r$ 与 $\boldsymbol{c}_m$ 相似,并添加一些扰动:
$$
c_r=c_m+a \tag{4}
$$
其中 $a$ 的值在 0 和 0.2 之间随机采样。我们合并 $\boldsymbol{pt}_m$ 和 $\boldsymbol{pt}_r$ 的位置和颜色,得到最终的点云。
$$
pt(p_f,c_f)=(p_m\oplus p_r,c_m\oplus c_r)
$$
其中 ⊕ 是串联操作(concatenation)。
图 3 展示了噪点生长和颜色扰动的过程。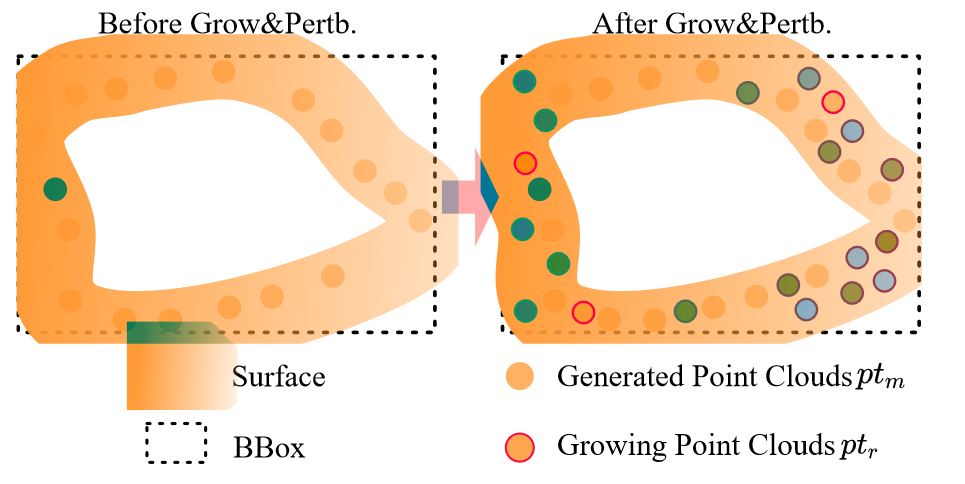
图 3:噪点生长和颜色扰动的过程。“Grow&Pertb.”表示噪点生长和颜色扰动
最后,我们使用最终点云 $\boldsymbol{pt}$ 的位置 $\boldsymbol{pt}_f$ 和颜色 $\boldsymbol{c}_f$ 来初始化 3D 高斯分布 $\theta_b(\mu_b,c_b,{\Sigma_b},\alpha_b)$ 的位置 $\lambda_b$ 和颜色 $c_b$ 。3D 高斯分布的不透明度 $\alpha_b$ 初始化为 0.1,协方差 $\Sigma_b$ 计算为最近两个点之间的距离。
算法 1 展示了具体的算法流程图。
3.3.2 Text-to-Motion Diffusion Model
我们使用文本生成一系列人体动作(human body motions),并选择与给定文本最匹配的人体姿势。然后将该人体姿势的关键点转换为 SMPL 模型[38],该模型由三角网格 $m$ 表示。然后将网格 $m$ 转换为点云 $\boldsymbol{pt}_m(\boldsymbol{p}_m,\boldsymbol{c}_m)$。
- $p_m\in\mathbb{R}^3$ 表示点云的位置,它等于 $m$ 的顶点坐标;
- $c_m\in\mathbb{R}^3$ 指的是点云的颜色,由于此处使用的 SMPL 模型没有纹理,我们随机初始化 $c_m$
为了将 $\boldsymbol{pt}_m$ 移动到原点附近,我们计算 $\boldsymbol{pt}_m$ 的中心点 $p_c\in\mathbb{R}^3$ ,根据下式计算移动后的点云
$$
pt(p_f,c_f)=pt_m(p_m-p_c,c_m)\tag{6}
$$
最后,我们使用点云 𝒑𝒕 来初始化 3D 高斯,类似于第 3.3.1 节中描述的内容。
为了改善运动序列的生成,我们简化文本,只保留与运动相关的部分,并添加一个主语。 例如,如果文本提示是“钢铁侠用左腿踢”,在生成运动序列时,我们将其转换为“某人用左腿踢”。
3.4 使用 2D Diffusion Model 进行优化
为了丰富细节并提高 3D 资产的质量,我们在使用 3D Diffusion Model priors 进行初始化后,对 3D 高斯模型 $\theta_b$ 进行优化,采用 2D Diffusion Model $F_{2D}$ 。我们利用 SDS(得分蒸馏采样)损失来优化 3D 高斯模型。
首先,我们使用 3D GS 方法[24]来获得渲染图像 $x=g(\theta_i)$ 。在这里, $g$ 表示 [[论文/3DGS/03 Mesh提取/01 3DGS起源/总结#渲染公式|3DGS渲染公式]]。
然后,我们利用[[#3.1.1 DreamFusion|公式 1]] 计算梯度,以便用 2D Diffusion Model $F_{2D}$ 更新高斯参数 $\theta_i$ 。
在使用 2D Diffusion Model $F_{2D}$ 进行短期优化后,最终生成的 3D 实例 $\theta_f$ 在 3D Diffusion Model $F_{3D}$ 提供的 3D 一致性的基础上实现了高质量和保真度。
4 实验
- 首先介绍了第 4.1 节的实现细节和第 4.2 节的定量比较。
- 在第 4.3 节中,我们展示了我们方法的可视化结果,并将其与其他方法进行了比较。
- 在第 4.4 节中,我们进行了一系列消融实验来验证我们方法的有效性。
- 最后,我们讨论了我们方法的局限性。
略

图 4:我们的方法和 DreamFusion [50]、Magic3D [31]、Fantasia3D [6] 和 ProlificDreamer [77] 的定性比较。这里我们参考他们的论文所报告的 GPU 时间。DreamFusion 使用 TPUv4 进行测量,Magic3D 使用 A100 进行测量,Fantasia3D 使用 RTX 3090 进行测量,我们的方法使用 RTX 3090 进行测量。

图 5:由我们的 GaussianDreamer 生成的更多样本。每个样本显示了两个视图。

图 6:使用地面进行生成的结果。

图 7:我们的方法与 DreamFusion [50],DreamAvatar [5],DreamWaltz [18]和 AvatarVerse [86]的定性比较。

图 8. 我们的 GaussianDreamer 使用 SMPL 的不同姿势初始化生成的更多 3D 头像[38]。在这里,SMPL 的不同姿势是通过 text-to-motion diffusion model生成的。
5 结论
我们提出了一种快速的text-to-3D 方法 GaussianDreamer,通过 GS 表示法将 3D 和 2D Diffusion Model 的能力结合起来。GaussianDreamer 能够生成详细和逼真的几何和外观,同时保持 3D 的一致性。
3D Diffusion Model 先验和来自 3D 高斯的几何先验有效地促进了收敛速度。每个样本可以在一个 GPU 上在 15 分钟内生成。
我们相信桥接 3D 和 2D Diffusion Model 的方法可能是有效生成 3D 资产的一个有前途的方向。
 微信
微信 支付宝
支付宝



