
3DGS总结
3D GS 整体框架
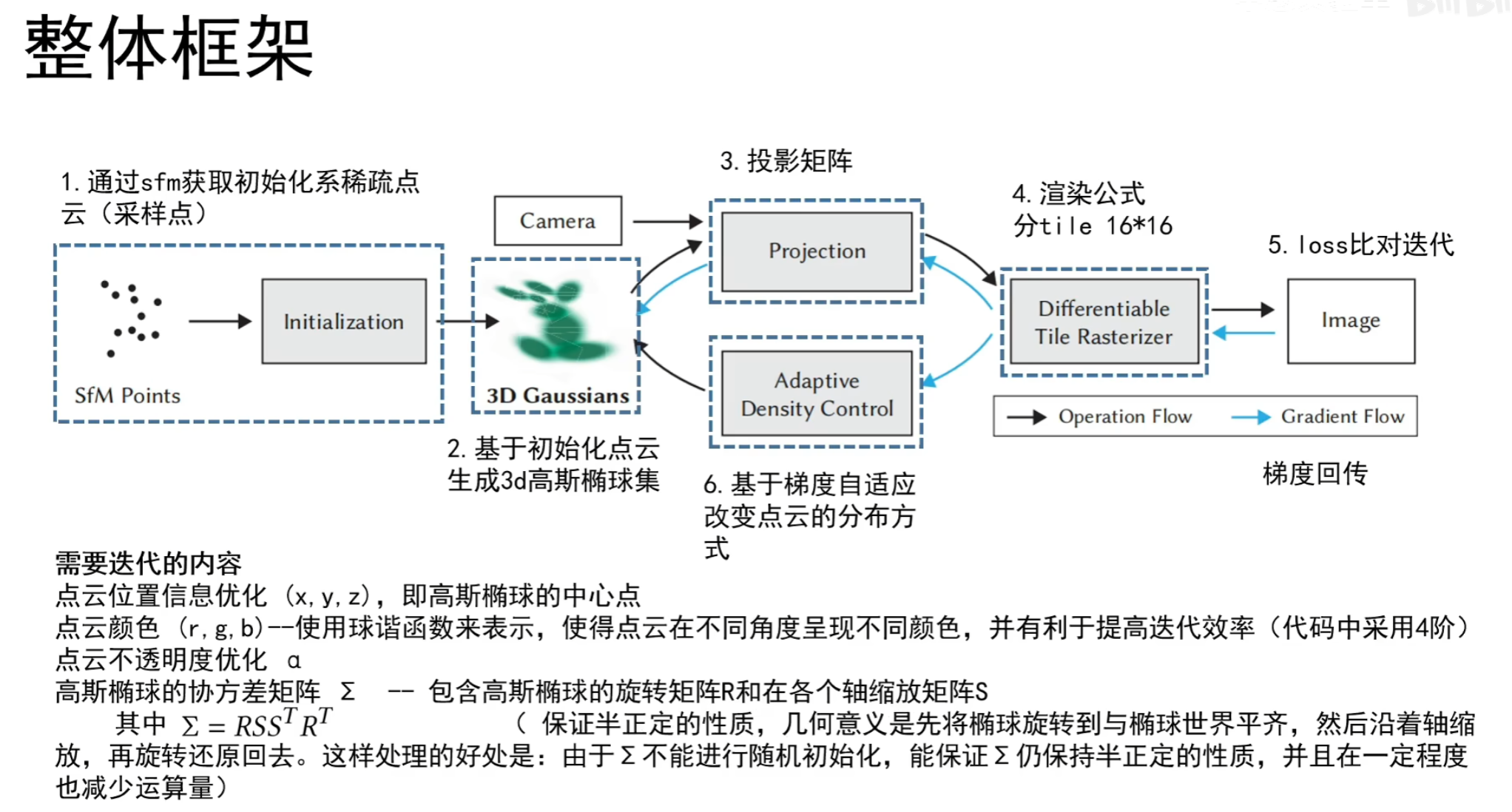
- (1) 使用 SfM 从一组图像中生成稀疏点云(调用 COLMAP 库 )
- (2) 点云经初始化生成 3D 高斯椭球集。(当由于某种原因无法获得点云时,可以使用随机初始化来代替,但可能会降低最终的重建质量)
- (3)(4) 通过泼溅等一系列 [[#3D GS 的前向过程]],进行光栅化渲染
- (5)(6) 训练:与神经网络类似,我们使用随机梯度下降法进行训练,但这里没有神经网络的层的概念 (都是 3D 高斯函数)。
- 训练步骤如下:
- 经过步骤 (3)(4) 渲染出图像
- 根据渲染图像和 GT 之间的差计算 loss
- 根据 loss 进行 3D 高斯的参数控制
- 基于梯度进行 3D 高斯的自适应密度控制
- 训练步骤如下:

3D Gaussian 定义
3D 高斯的属性包括 (所有属性都可以通过反向传播来学习和优化):
| 属性 | 优化方法 |
|---|---|
| 中心坐标 $\mu$ | ($x,y,z$ )的均值 |
| 3D 协方差矩阵 $\Sigma=RSS^\top R^\top$ | [[#参数优化]] |
| 不透明度 $α$ | [[#自适应密度控制]] |
| 颜色 $c(r,g,b)$ | [[#球谐函数表示颜色]] |
3D 高斯是由世界空间中以坐标 $\mu$ 为中 心的 3D 协方差矩阵 $\Sigma$ 定义的(即通过 $\Sigma$ 定义了高斯的形状):
$$
G(x)~=e^{-\frac{1}{2}(x)^{T}\Sigma^{-1}(x)}
$$
在混合过程中,该高斯乘以 $\alpha$ 。
3D GS 的优化
我们方法的核心是优化步骤,它创建了一组密集的 3D 高斯,准确地代表了用于自由视角合成的场景。
**除了位置 $p$ , 透明度 $\alpha$ 和协方差 $\Sigma$ 之外,我们还优化了代表每个高斯的颜色 $c$ 的 SH 系数,以正确捕捉与视角相关的场景外观。这些参数的优化与控制高斯密度的步骤交错进行,以更好地表现场景。
优化基于连续的迭代渲染,并将生成的图像与捕获数据集中的训练视图进行比较。由于三维到 2D 投影的不确定性,几何体的位置难免会不正确。因此,我们的优化需要能够创建几何图形,并在几何图形被错误定位时将其销毁或移动。3D 高斯协方差参数的质量对表示的紧凑性至关重要,因为只需少量各向异性的大高斯就能捕捉到大面积的同质区域。
参数优化和自适应密度控制交错运行,通过优化程序,可以得到一个相当紧凑、非结构化和精确的场景表示(所有测试场景的高斯数均为 100-500 万)。
参数优化

在对所有参数进行优化时,我们使用随机梯度下降法,充分利用标准的 GPU 加速框架,并根据最近的最佳实践 (Fridovich-Keil and Yu et al., 2022; Sun et al., 2022),为某些操作添加定制的 CUDA 内核。
- $\alpha$:对 $\alpha$ 使用了 sigmoid 激活函数,以将其限制在 $[0,1)$ 范围内,从而获得平滑的梯度。
- $\Sigma$ :梯度下降法直接优化协方差矩阵 $\Sigma$ 时可能会产生一个非半正定矩阵,然而,协方差矩阵只有在半正定时才具有物理意义。因此,我们选择了一种更直观、但具有同等表达能力的优化表示方法。3D 高斯的协方差矩阵 $\Sigma$ 类似于描述椭球体的构型。给定缩放矩阵 $S$ 和旋转矩阵 $R$ ,我们就可以找到相应的 $\Sigma$ :$$\Sigma=RSS^\top R^\top$$ 为了对这两个因素进行独立优化,我们将它们分开存储:三维向量 $s$ 用于缩放,四元数 $q$ 表示旋转(我们将会优化 $s$,$q$,而不直接优化协方差矩阵)。我们可以简单地将它们转换为各自的矩阵并进行组合,同时确保对 $q$ 进行归一化处理,以获得有效的单位四元数。其中 $R$ 与 $S$ 分别由 $q$ 和 $s$ 推导得到的旋转和缩放矩阵。
- $R$ 是一个 3x3 的旋转矩阵,通过旋转四元数来表示
- $S$ 是一个对角缩放矩阵,含有 3 个参数
- 为了避免在训练过程中自动微分带来的巨大开销,我们明确推导出了 $q$ 和 $s$ 的梯度。 详情见附录 A。通过这种适合优化的各向异性协方差表示方法,使我们能够对 3D 高斯进行优化,以适应拍摄场景中不同形状的几何图形,可以清楚地显示 3D 高斯的各向异性形状,优化后的 3D 高斯能紧凑地表现复杂的几何图形。
自适应密度控制
我们从 SfM 的初始稀疏点集合开始,应用我们的方法自适应地控制单位体积内的高斯数量及其密度,使我们能够从初始的稀疏高斯集到更密集的高斯集,从而更好地代表场景,并获得正确的参数。
在优化热身(optimization warm-up)之后,我们每迭代 100 次就会进行一次高斯密集化处理,并删除任何基本透明( $\alpha$ 小于阈值 $\epsilon_{\alpha}$ )的高斯。
[!NOTE] warm-up
为了保持稳定,我们在较低分辨率下进行计算 “热身(warm-up)”。具体来说,我们使用 4 倍较小的图像分辨率开始优化,并在迭代 250 次和 500 次后进行两次升采样。
SH 系数优化对缺乏角度信息很敏感。对于典型的 “NeRF-like “捕捉,即通过围绕中心物体的整个半球拍摄的照片来观测中心物体,优化效果很好。但是,如果捕捉的角度区域缺失(例如,捕捉场景的角落或进行 “内向外”捕捉时),优化就会产生完全错误的 SH 零阶分量(即基色或漫反射色)值。为了解决这个问题,我们首先只对零阶成分进行优化,然后每迭代 1000 次就引入一个 SH 波段(one band of the SH),直到所有 4 个 SH 波段都得到体现。
我们对高斯的自适应控制需要填充空白区域。 它不仅关注几何特征缺失的区域(重建不足),也关注高斯覆盖场景大面积的区域(重建过度),两者都有较大的视空间位置梯度。直观地说,这可能是因为它们对应的区域还没有得到很好的重建,而优化试图移动高斯来纠正这一点。由于这两种情况都适合进行高斯密集化处理,因此我们会对观察空间位置梯度平均值超过阈值 $\tau_{pos}$ 的高斯进行密集化处理 (基于梯度)。我们在测试中将其设置为 0.0002 。
高斯密集化(Densification) 有两种情况:
- 在重建不足的区域克隆小高斯,并沿位置梯度方向移动
- 在过度重建的区域分割大高斯,用两个较小的高斯替换一个大高斯,并用实验确定的 $\phi =1.6$ 因子来划分它们的比例。我们还使用原始 3D 高斯作为采样的 PDF 来初始化它们的位置。
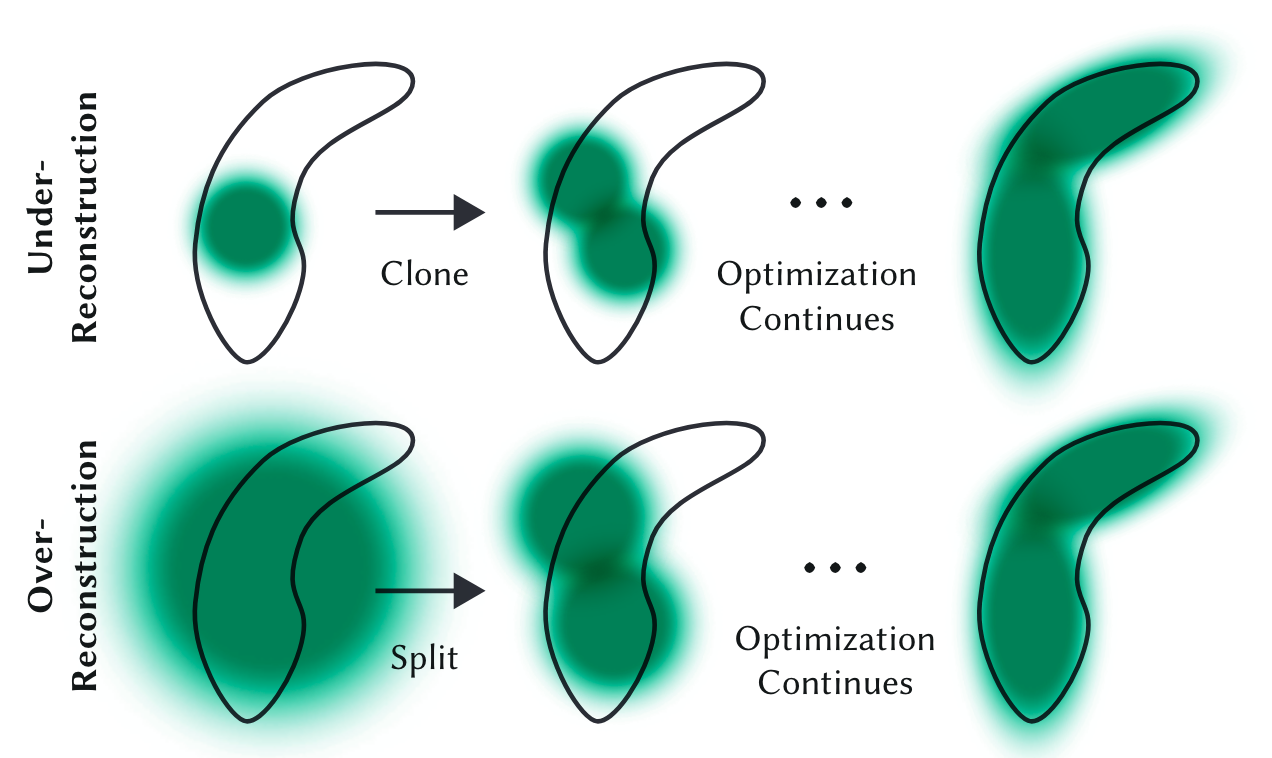
高斯剪枝(Pruning):
与其他体积表示法类似,密集化增加的高斯可能会陷入靠近输入相机的漂浮物;在我们的案例中,这可能会导致高斯密度的不合理增加。减缓高斯数量增加的有效方法是每 $N=3000$ 次迭代,将 $\alpha$ 值设为接近零。 密集化后,高斯的 $\alpha$ 值会增加,同时我们的剔除方法可以去除 $\alpha$ 小于 $\epsilon_{\alpha}$ 的高斯,如上所述。
高斯可能会缩小或增大,也可能与其他高斯严重重叠,但我们会定期删除世界空间中非常大的高斯和视图空间中足迹(footprint)较大的高斯。 这种策略可以很好地控制高斯总数。与其他方法不同的是,我们的模型中的高斯始终保持欧几里得空间中的基元;对于遥远或大型高斯,我们不需要空间压缩、扭曲或投影策略。
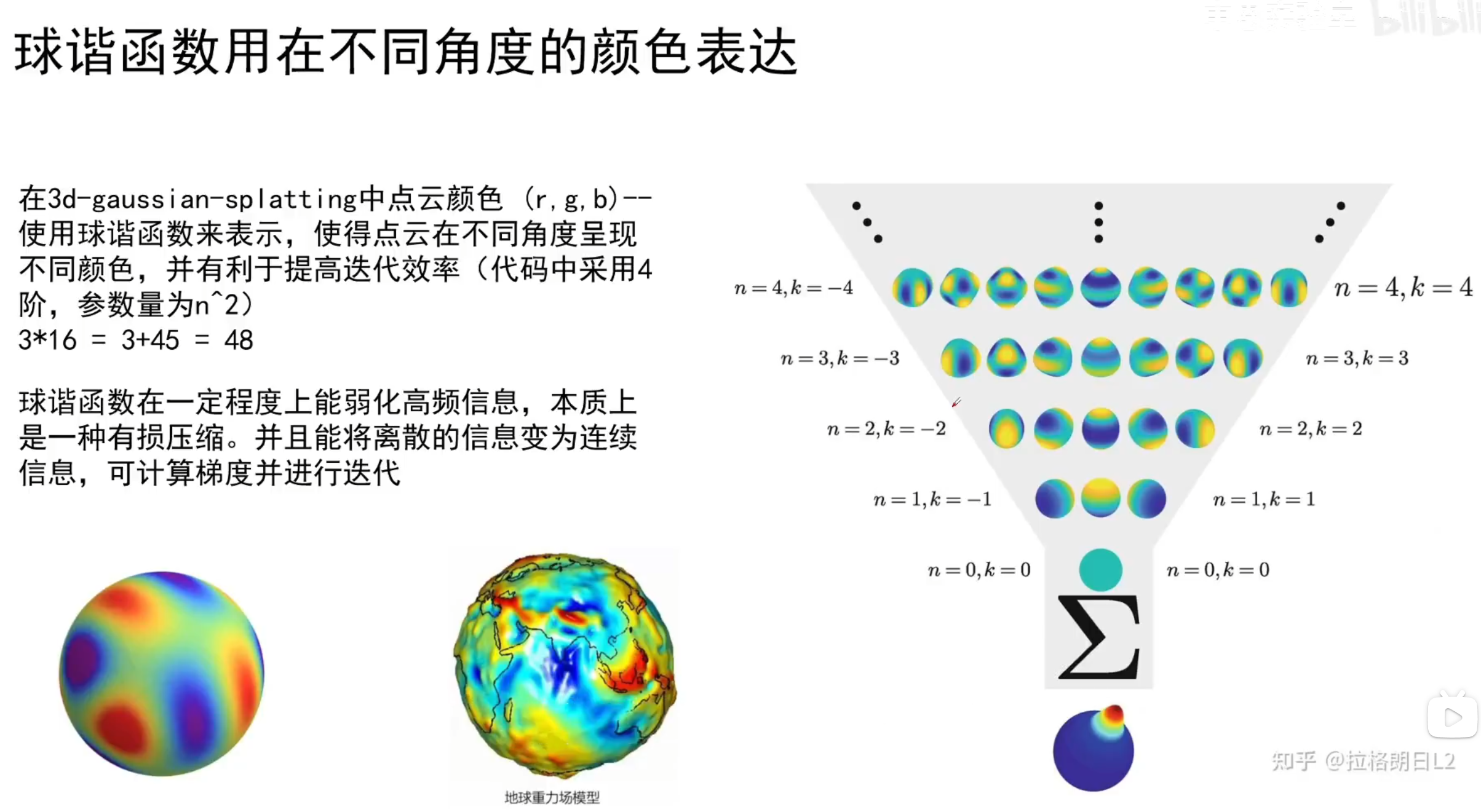
球谐函数表示颜色
3DGS 从点云 pcd 数据中读取了球谐系数,使用硬编码的球谐函数多项式,计算出单位方向上的高斯颜色。
损失函数
图像合成后,计算渲染图像与 GT 的差值作为 loss。使用了与 Plenoxels 类似的标准指数衰减调度技术,但只针对位置。
**损失函数为 $\mathcal{L}_1$ 结合 $D-SSIM$ 项:$$\mathcal{L}=(1-\lambda)\mathcal{L}1+\lambda\mathcal{L}{D-SSIM}$$ 其中 $λ$ 是权重因子(在所有测试中都使用了 $\lambda=0.2$ ),$\mathcal{L}_1$ 损失和 $D-SSIM$ 项是标准测量值。
3DGS 的损失函数与 NeRF 的损失函数略有不同:NeRF 通常在像素级别而不是图像级别进行计算,因此需要耗费大量的光线步进,而 3D GS 是图像级别的。
3D GS 的前向过程
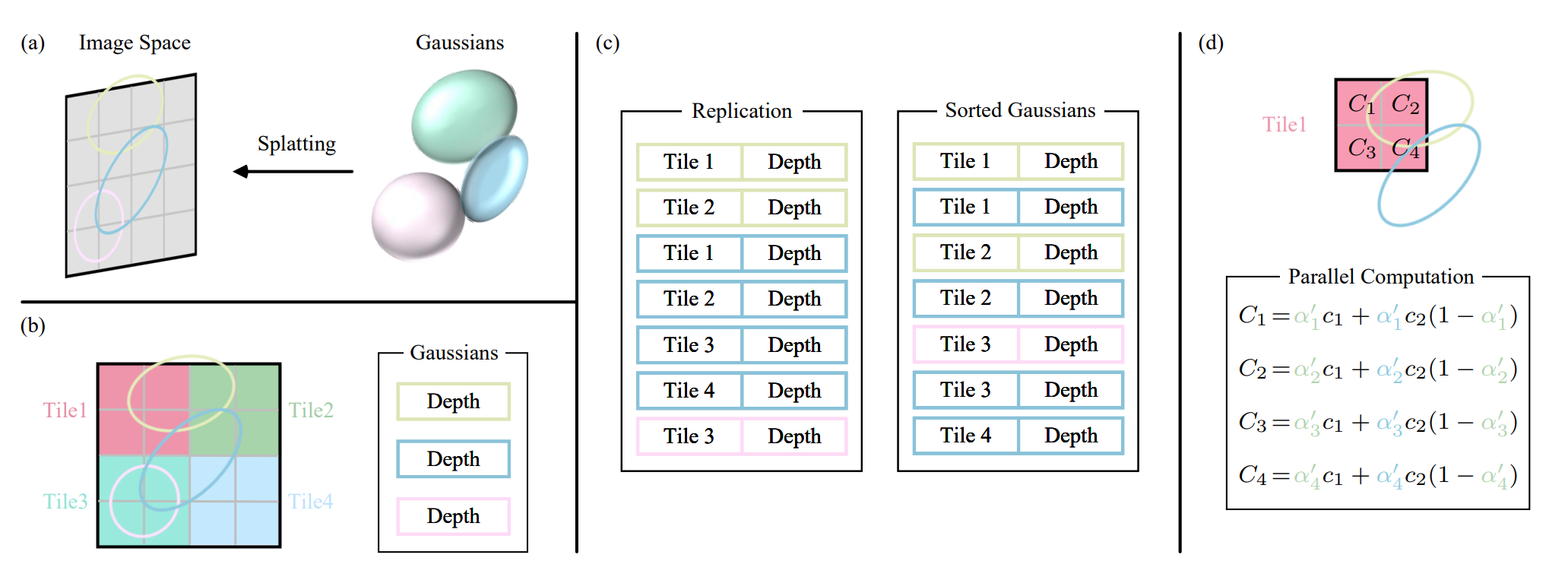
图 3:3D 高斯前向处理过程示意图(第 3.1 节)。
(a) 泼溅步骤将 3D 高斯投影到图像空间 (屏幕空间)。
(b) 3D 高斯将屏幕划分为多个不重叠的tile。
(c) 3D 高斯复制覆盖多个tile的高斯,为每个副本分配一个标识符,即tile ID。
(d) 通过渲染分类高斯,我们可以获得tile内的所有像素。请注意,像素和tile的计算工作流程是独立的,可以并行处理。
考虑一个由(数百万个)优化 3D 高斯表示的场景。目标是根据指定的相机姿态生成图像。3DGS 首先将这些三维高斯投影到基于像素的图像平面(即屏幕)上,这一过程被称为 “泼溅(Splatting)”(图 3a)然后,3D 高斯排序并计算每个像素的值。(3DGS 这个渲染过程就是光栅化渲染)
渲染方法
泼溅(Splatting)
将 3D 高斯投影到 2D 图像空间(世界空间->屏幕空间;椭圆体->椭圆)。给定观察变换 $W$ 和 3D 协方差矩阵 $\Sigma$ ,可以投影出 2D 协方差矩阵 $\Sigma^{\prime}$: $$\Sigma^{\prime}=JW\Sigma W^\top J^\top$$ 其中 $J$ 为投影变换仿射近似的雅可比矩阵。
对 $J$ 矩阵的解释:
3D 高斯的基础单元是一个3D 分布,论文应该是希望在变换中保持 3D 分布的(不然光栅完和高斯没关系岂不是一直以来的努力都白费了),难免会遇到更多限制。观察变换 $W$ 是 3D 仿射变换(3d->3d),但透视投影变换引入了透视(3d->2d)不再是 3D 仿射变换,于是论文用 $J$ 替代了透视投影矩阵,它是对投影变换进行仿射近似,再取雅克比矩阵的产物。
根据EWA volume splatting(Zwicker et al. [2001a],取一个点对透视投影矩阵二阶泰勒展开即可得到仿射近似 local affine approximation,更具体来说其中雅克比矩阵是透视投影矩阵在这一点对相机空间点的偏导。最后得到的投影如下图:
相机空间、local affine approximation和理论上的目ray空间
左下是文中得到的近似结果,右下是理想的投影结果。这样最终变换完的的基础单元仍然是一个3D 高斯,而且3D 的前两维对应2D 像素坐标 xy,第三维则对应从像素进入的深度。
快速微分光栅化器
我们的目标是实现快速的整体渲染和快速排序,以允许近似的 $\alpha$ 混合(包括各向异性的 splats ),并避免之前工作(Lassner 和 Zollhofer,2021 年)中存在的对可接收梯度的 splats 数量的硬性限制。
为了实现这些目标,我们设计了一种基于 tile 的高斯泼溅光栅化器:
- 可以一次对整个图像的基元进行预排序,避免了以往 alpha 混合解决方案所遇到的按像素排序的问题。
- 可以对任意数量的混合高斯进行高效的反向传播,额外内存消耗低,每个像素只需要一个恒定的开销。
- 我们的光栅化管线是完全可微的,在投影到 2D 的情况下,可以对各向异性的高斯进行光栅化。
为了避免为每个像素推导高斯的计算成本,3D 高斯将精度从像素级转移到了 tile 级。
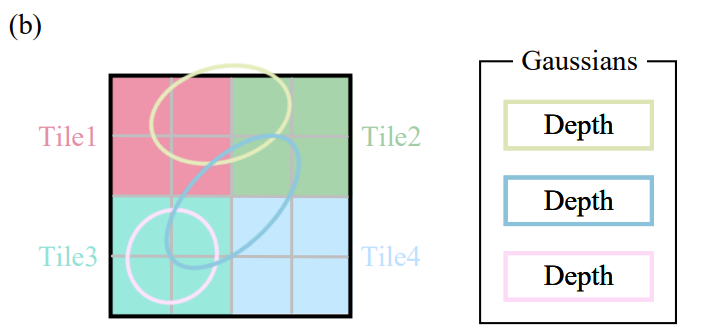
- 首先将屏幕分割成 16 × 16 个
tile,然后根据视锥和每个 tile 剔除(cull)3D 高斯。具体来说:- 只保留置信区间为 99% 且与视锥相交的高斯。
- 此外还使用一个保护带 (guard band) 来剔除极端位置的高斯(即均值接近近平面但远离视锥的高斯),因为计算它们的投影 2D 协方差将是不稳定的。
- 然后,我们根据每个高斯覆盖的 tile 数量对其进行实例化(覆盖几个 tile 就实例化几次,也可以说复制几次),复制后,3D GS 会将各自的
tile ID与每个高斯观察变换得到的深度值结合起来。这将产生一个未排序的列表,其中高位代表tile ID,低位表示观察空间深度Depthh。。(这样排序时不用判断每个像素与高斯的距离,而是判断 tile ,这样计算就简单多了)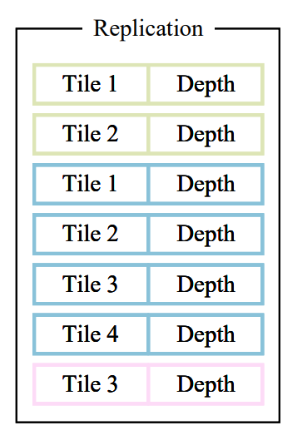
- 然后,使用单个快速 GPU Radix 排序 (Merrill and Grimshaw, 2010) 根据这些键对高斯进行排序,在对高斯进行排序后,我们会通过识别第一个和最后一个按深度排序的泼溅到指定 tile 的条目来为每个 tile 生成一个列表。
- 需要注意的是,没有额外的按像素排序的点,混合是基于这种初始排序执行的)因此,我们的 $\alpha$ 混合在某些配置中可能是近似的。不过,当高斯的大小接近单个像素时,这些近似值就可以忽略不计了。我们发现,这种选择大大提高了训练和渲染性能,而不会在聚合场景中产生明显的人工痕迹。
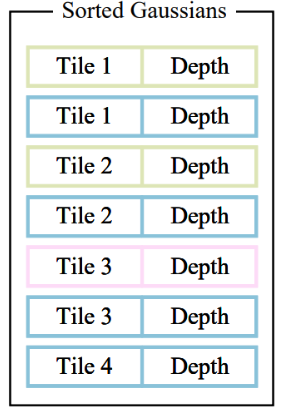
- 需要注意的是,没有额外的按像素排序的点,混合是基于这种初始排序执行的)因此,我们的 $\alpha$ 混合在某些配置中可能是近似的。不过,当高斯的大小接近单个像素时,这些近似值就可以忽略不计了。我们发现,这种选择大大提高了训练和渲染性能,而不会在聚合场景中产生明显的人工痕迹。
- 在光栅化过程中,我们为每个 tile 启动一个线程块(thread block)。
- 每个 block 首先协同将高斯数据包加载到共享内存中,然后针对给定像素,通过前后遍历列表来累积颜色和 $\alpha$ 值,从而最大限度地提高数据加载/共享和处理的并行性。
- 当某一像素的 $\alpha$ 达到目标饱和度时,相应的线程就会停止。每隔一定时间,我们会对一个 tile 中的线程进行查询,当所有像素都达到饱和(即 $\alpha$ 变为 1)时,整个 tile 的处理就会终止。 有关排序的详细信息和整个光栅化方法的高级概述见附录 C。
- 值得强调的是,每个
tile和像素的渲染都是独立进行的,因此这一过程非常适合并行计算。另外一个好处是,每个tile的像素都可以访问共同的共享内存,并保持统一的读取顺序,从而提高 Alpha 混合的并行执行效率。在原论文的正式实施中,该框架将tile和像素的处理分别视为类似于 CUDA 编程架构中的块和线程。
- 注意, $\alpha$ 的饱和度是唯一的停止标准。与之前的工作不同,我们不限制接受梯度更新的混合基元的数量。我们强制执行这一特性,是为了让我们的方法能够处理具有任意不同深度复杂性的场景,并对其进行精确学习,而无需诉诸特定场景的超参数调整。因此,在 backward pass(后向处理)过程中,我们必须恢复 forward pass (前向处理)过程中每个像素的完整混合点序列。为了避免隐含的动态内存管理开销,我们选择再次遍历每个 tile 列表;我们可以重复使用前向遍历中的高斯排序数组和 tile 范围。为了方便梯度计算,我们现在从后向前遍历它们。
遍历从影响 tile 中任何像素的最后一个点开始,并再次以协作方式将点加载到共享内存中。此外,只有当每个像素点的深度小于或等于在 forward pass 中对其颜色有贡献的最后一个点的深度时,才会开始对其进行(昂贵的)重叠测试和处理。计算第 4 章所述的梯度需要原始混合过程中每一步累积的不透明度值。我们可以只存储前向传递结束时的总累积不透明度,而不是在后向传递中遍历一个逐渐缩小的不透明度显式列表,从而恢复这些中间不透明度。具体来说,在前向遍历过程中,每个点都会存储最终累积的不透明度 (opacity) $\alpha$ ;在后向遍历过程中,我们将其除以每个点的 $\alpha$ ,从而得到梯度计算所需的系数。
渲染公式
基于点的 alpha 混合和 NeRF 风格的体积渲染在本质上共享相同的图像形成模型。具体来说,颜色 $C$ 是通过沿射线的体积渲染得到的。
$$
C=\sum_{i=1}^{N}T_{i}(1-\exp(-\sigma_{i}\delta_{i}))\mathbf{c}{i}\quad其中\quad T{i}=\exp\left(-\sum_{j=1}^{i-1}\sigma_{j}\delta_{j}\right)\tag{1}
$$
其中密度 $\sigma$、透射率 $T$ 和颜色 $c$ 的样本是沿着光线以间隔 $\delta_i$ 采集的。这可以重写为
$$
C=\sum_{i=1}^{N}T_{i}\alpha_{i}\mathbf{c}{i}\tag{2}
$$
其中 $\displaystyle\alpha{i}=(1-\exp(-\sigma_{i}\delta_{i}))\quad T_{i}=\prod_{j=1}^{\iota-1}(1-\alpha_{i})$
(3DGS 采用这种方法)典型的基于神经点的方法 (e.g., [Kopanas et al. 2022, 2021])通过 Alpha 混合像素上重叠的 𝒩个有序点来计算像素的颜色 $C$。
$$
C=\sum_{i\in\mathcal{N}}c_{i}\alpha_{i}\prod_{j=1}^{i-1}(1-\alpha_{j})\tag{3}
$$
其中,
- $c_i$ 是当前点 i 的颜色
- $\alpha_i$ 代表当前点 i 的不透明度,是通过对具有协方差 $\Sigma$ 的二维高斯(泼溅后的 2D 高斯)乘以学习到的点 i 的不透明度 $\alpha_i’$ 求得的。$$\alpha_i=\alpha_i’\times\exp\left(-\frac12(x’-\mu_i’)^\top\Sigma_i’^{-1}(x’-\mu_i’)\right)$$
- 其中 $x’$ 是点 i 在屏幕空间中的坐标, $μ’_i$ 是中心坐标,同时我也找了个 gif 来可视化了一下 Gaussian Splatting 对位置 p 的影响:

- 其中 $x’$ 是点 i 在屏幕空间中的坐标, $μ’_i$ 是中心坐标,同时我也找了个 gif 来可视化了一下 Gaussian Splatting 对位置 p 的影响:
- $\prod_{j=1}^{i-1}(1-\alpha_{j})$ 代表排序在 i 之前的点的透明度累乘
- 在 3D GS 中基于 tile 将高斯(相当于公式中的点)划分,并进行了排序[[#快速微分光栅化器]],即可通过该公式计算。
从(2)(3)的公式中,我们可以清楚地看到图像形成模型是相同的。但是,渲染算法却截然不同:
- NeRF 是一种隐含地表示空/占空间的连续表示法;采样需要进行昂贵的随机采样,因此会产生噪声和计算费用。
- 相比之下,点是一种非结构化的离散表示法,具有足够的灵活性,可以创建、破坏和位移与 NeRF 类似的几何体。正如之前的工作所示,这是通过优化不透明度和位置实现的,同时避免了全体积表示法的缺点。
伪代码
讲解:3D Gaussian Splatting原理速通(四)–伪代码流程_哔哩哔哩_bilibili

源码解析
学习笔记之——3D Gaussian Splatting源码解读_gaussian splatting源码分析-CSDN博客
TODO: CUDA
 微信
微信 支付宝
支付宝



