
Lua精粹
[!NOTE] 约定
在本书中,我们使用
- 双引号表示字符串常量(如
"literal strings")- 单引号表示单个字符(如
'a'),用作模式的字符串也会被单引号引起来,例如'[%w_]*'。- 符号
<-->表示两者完全等价:
一、特性
程序段
我们将Lua语言执行的每一段代码(例如,一个文件或交互模式下的一行)称为一个程序段( Chunk ),即一组命令或表达式组成的序列。
注释
注释格式:
1 | -- 行注释 |
在注释一段代码时,一个常见的技巧是将这些代码放入 --[[ 和 --]] 之间,例如:
1 | --[[ |
当我们需要重新启用这段代码时,只需在第一行行首添加一个连字符即可(即开头连续三个-):
1 |
|
解释:在第一个示例中,第一行的 --[[ 表示一段多行注释的开始,直到遇到两个连续的右括号这段多行注释才会结束,因而尽管最后一行有两个连续的连字符,但由于这两个连字符在最后两个右方括号之前,所以仍然被注释掉了。在第二个示例中,由于第一行的 ---[[ 实际是单行注释,因此最后一行实际上也是一条独立的单行注释(最后的两个连续右方括号没有与之匹配的 --[[),print并没有被注释掉。
标识符
- Lua语言中的标识符(或名称)是由任意字母、数字和下画线组成的字符串(注意,不能以数字开头),例如:

- 下画线+大写字母”(例如
_VERSION)组成的标识符通常被Lua语言用作特殊用途,应避免将其用作其他用途。通常会将“下画线+小写字母”用作哑变量(Dummy variable)。 - 以下是Lua语言的保留字(reserved word),它们不能被用作标识符:

Lua语言是对大小写敏感的,因而虽然 and 是保留字,但是And和AND就是两个不同的标识符。
其他
- lua 和 C 语言一样,对大小写字符敏感
- 句尾分号是可省略的,以下四种写法等价

- 数组下标从 1 开始
- 不支持函数重载,如果有多个同名函数,只会调用最后声明的函数。
#用于获取指定变量的长度,例如string,table等。#获取长度不准确(当序列中存在 nil 值时),推荐使用迭代器遍历for pairs- 只有 nil 和 false 被认为是假值
二、变量
1 变量类型
Lua语言是一种动态类型语言,在这种语言中没有类型定义,每个值都带有其自身的类型信息。任何变量都可以相互赋值
获取变量类型:
type(a)type()的返回值是 string 类型,可以通过type(type(a))验证
值类型:
nilbooleannumberstringnil即 null,访问未声明的变量不会报错,默认为nil。它的主要作用就是与其他所有值进行区分,即将 nil 视为无效值boolean即 bool,trueorfalse。在 lua 中,任何值都可以用于条件测试,除了 false 和 nil 外都视为真。注意,lua 把零和空字符都视为真。- 所有的数值都是
number(数值) 类型,- Lua5.2 及之前默认为双精度浮点型
- 从Lua 5.3版本开始,Lua语言为数值格式提供了两种选择:被称为
integer的64位整型和被称为float的双精度浮点类型 - 对于资源受限的平台,我们可以将Lua 5.3编译为精简 Lua ( Small Lua )模式,在该模式中使用32位整型和单精度浮点类型
string为字符串,可以使用''或"",lua 中没有 char 类型。string 是不可变值,不能直接修改其中某个字符,但是可以通过创建一个新字符串实现功能。
引用类型:
functiontableuserdatathread
引用类型默认为浅拷贝:
1 | local a = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; |
userdata 类型允许把任意的C语言数据保存在Lua语言变量中。userdata 类型除了赋值和相等性测试外,没有其他预定义的操作。userdata 被用来表示由应用或C语言编写的库所创建的新类型。例如,标准I/O库使用用户数据来表示打开的文件。我们会在后面涉及CAPI时再讨论更多的相关内容。
2 全局变量与局部变量
全局变量(Global Variable)无须声明即可使用,使用未经初始化的全局变量也不会导致错误。当使用未经初始化的全局变量时,得到的结果是nil。
当把nil赋值给全局变量时,Lua会回收该全局变量的内存(Lua 不区分未初始化变量和被赋值为 nil 的变量)
默认声明的变量都是全局变量
局部变量关键字:
local
1 | for i = 1, 10, 1 do |
Lua语言中有一种常见的用法:
1 | local foo = foo |
这段代码声明了一个局部变量foo,然后用全局变量foo对其赋初值(局部变量foo只有在声明之后才能被访问)。这个用法在需要提高对foo的访问速度时很有用。当其他函数改变了全局变量foo的值,而代码段又需要保留foo的原始值时,这个用法也很有用,尤其是在进行运行时动态替换(monkey patching,猴子补丁)时。即使其他代码把 foo动态替换成了其他函数,在local foo=foo语句之前的所有代码使用的还都是原先的 foo函数?
局部变量的生效范围仅限于声明它的代码块。如果 local 在代码块外部使用呢?
1 | local a = 123 |
那么这和全局变量有什么区别?这和多脚本执行有关:脚本 B 可以访问脚本 A 声明的全局变量,但不能访问 local 变量
全局变量的声明
Lua语言中的全局变量不需要声明就可以使用,可以通过元表来发现访问不存在全局变量的情况。
一种方法是简单地检测所有对全局表中不存在键的访问:
1 | setmetatable(_G, { |
这段代码执行后,所有试图对不存在全局变量的访问都将引发一个错误。
如何声明一个新的变量?
方法一:使用函数 rawset,它可以绕过元方法
1 | function decalre (name, val) |
其中,or 和 false 保证新变量一定会得到一个不为nil的值。
方法二:
更简单的方法是把对新全局变量的赋值限制在仅能在函数内进行,而代码段外层的代码则被允许自由赋值。
要检查赋值是否在主代码段中必须用到调试库。调用函数 debug.getinfo(2,"S") 将返回一个表,其中的字段 what 表示调用元方法的函数是主代码段还是普通的Lua函数还是C函数。使用该函数,可以将 __newindex 元方法重写:
1 | __newindex = function(t, name, val) |
如果要测试一个变量是否存在,并不能简单地将它与nil比较。因为如果它为nil,那么访问就会引发一个错误。这时,应该使用rawget来绕过元方法:
1 | -- 'var' 未被声明 |
3 多变量赋值
1 | a, b, c = 1, 2, 3 |
4 string 操作
#获取字符串长度 (包含空格)
- 英文字母长度为 1
- 汉字长度为 3
1 | print(#"hello") -- 输出5 |
长字符串/多行字符串
[[]]- 使用转义字符
\n - 使用双中括号
[[]]有时字符串中可能有类似1
2
3
4
5
6
7
8
9
10
11
12
13
14
15print("hello\nworld")
print[[你好世界]]
print[[你好
世界]]
-- 输出如下
hello
world
你好世界
你好
世界a=b[c[i]]这样的内容(注意其中的]]),或者,字符串中可能有被注释掉的代码。为了应对这些情况,可以在两个左方括号之间加上任意数量的等号,如[===[。这样,字符串常量只有在遇到了包含相同数量等号的两个右方括号时才会结束(就前例而言,即]===])。Lua语言的语法扫描器会忽略所含等号数量不相同的方括号。通过选择恰当数量的等号,就可以在无须修改原字符串的情况下声明任意的字符串常量了。
对注释而言,这种机制也同样有效。例如,我们可以使用--[=[和]=]来进行长注释,从而降低了对内部已经包含注释的代码进行注释的难度。
- 使用转义字符
字符串拼接
..或string.format()方法- 支持不同类型变量拼接
- 当在 number 后紧接着使用字符串连接时,必须使用空格将它们分开,否则Lua语言会把第一个点当成小数点。
1
2
3
4
5
6s1 = "hello"
s2 = 123
print(s1..s2)
-- hello123
print(string.format("%s %d", s1, s2))
-- hello 123
- 其他类型转字符串
tostring(x)
print() 支持所有类型,都会自动转换为字符串。使用 tostring() 可以手动转换
- 其他方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30-- 大写转小写
string.upper(str)
-- 小写转大写
string.lower(str)
-- 翻转字符串
string.reverse(str)
-- 字符串模式匹配
-- 返回两个值,第一个是首字母位置,第二个是尾字母位置
string.find(str, "ab")
-- 将第一个字符串中的"l"替换为".", 第二个返回值返回替换的次数
string.gshub("hello world", "l", ".");
-- 子字符串
string.sub(str, 2) -- 从第二个字符开始截取
string.sub(str, 2, 3) -- 从第二个字符开始截取到第三个字符
-- 字符串重复
string.rep(str, 2) -- 重复两次
-- 字符串替换
string.gsub(str, "a", "c") -- 将a替换为c,返回替换后的字符串和替换次数
-- 字符转ASCII码
a = string.byte(str, 2) -- 返回第二个字符的ASCII码
-- ASCII码转字符
string.char(a)
6 table 表
表(Table)是Lua语言中最主要(事实上也是唯一的)和强大的数据结构,Lua语言也使用表来表示包(package)和其他对象。当调用函数math.sin时,我们可能认为是“调用了math库中函数sin”;而对于Lua语言来说,其实际含义是“以字符串”sin”为键检索表math”。
Lua语言中的表要么是值要么是变量,它们都是对象( object )。可以认为,表是一种动态分配的对象,程序只能操作指向表的引用(或指针)。除此以外,Lua语言不会进行隐藏的拷贝或创建新的表
当程序中没有对 table 的引用时,该 table 会被自动 GC
所有的复杂类型都是
table类型,存储键值对,类似 C++中的 map元素用
{}组织table 是动态对象,可按需增长
表索引
表本质上是一种辅助数组,这种数组不仅可以使用 number 作为索引,也可以使用 string 或其他任意类型的值作为索引(nil 除外)。
当把表当作结构体使用时,可以把索引当作成员名称使用(a.name 等价于 a["name"])。
1 | a = {} |
对Lua语言而言,这两种形式是等价且可以自由混用的,为了方便阅读,可以按一下方式表示 table:
- 形如
a.name的点分形式说明表是被当作结构体使用的,此时表实际上是由固定的、预先定义的键组成的集合; - 形如
a["name"]的字符串索引形式则说明了表可以使用任意字符串作为键,并且出于某种原因我们操作的是指定的键。
初学者常常会混淆 a.x 和 a[x]。实际上,a.x 代表的是 a["x"],即由字符串 "x" 索引的表;而 a[x] 则是指由变量 x 对应的值索引的表。
表构造器
两种方式构造表:
1 | --列表式 |
不过,这两种构造器都有各自的局限。例如,使用这两种构造器时,不能使用负数索引初始化表元素,也不能使用不符合规范的标识符作为索引。
对于这类需求,可以使用另一种更加通用的构造器,即通过方括号 []括起来的表达式显式地指定每一个索引:
1 | names = {["+"] = "add", ["-"] = "sub"}} |
这种构造器虽然冗长,但却非常灵活,不管是记录式构造器还是列表式构造器均是其特殊形式。例如,下面的表达式就相互等价:
1 | {x=0,y=0} --{["x"]=0,["y"]=0} |
最后一个元素后可以加逗号,是可选的
表的操作
由表标准库提供
1 | table.insert() -- 向序列的指定位置插入一个元素,其他元素依次后移。如果不指定位置默认插入末尾 |
函数table.move还支持使用一个表作为可选的参数。当带有可选的表作为参数时,该函数将第一个表中的元素移动到第二个表中。例如,table.move(a,1,#a,1,{}) 返回列表a的一个克隆(clone)(通过将列表a中的所有元素拷贝到新列表中),table.move(a,1, #a , #b+1,b) 将列表a中的所有元素复制到列表b的末尾
打包解包:pack把参数列表转换成Lua语言中一个真实的列表(一个表),而unpack则把Lua语言中的真实的列表(一个表)转换成一组返回值,进而可以作为另一个函数的参数被使用。
1 | print(string.find("hello", "world")) |
通常,函数table.unpack使用长度操作符获取返回值的个数,因而该函数只能用于序列。不过,如果有需要,也可以显式地限制返回元素的范围:
1 | print(table.unpack({"Sun","Mon","Tue","Wed"}, 2, 3)) |
数据结构
使用 table 实现各种数据结构
数组
在Lua语言中,简单地使用整数来索引 table 即可实现数组
- lua 的数组下标(索引)默认从 1 开始,Lua 的标准库和
#运算符都遵循这个管理(实际上可以使用其他任何值来作为数组的起始索引,但会破坏标准库和#运算符的机制 ) - 数组大小不是固定的,可按需增长
nil会截断数组,导致无法遍历后序元素
声明数组:
1 | -- 一维数组 |
自定义数组索引(不要滥用):
- 使用
[x] = var指定索引 x 对应变量 var1
2
3
4
5
6
7
8
9
10a = { [0] = 1, 2, 3, [-1] = 4, 5 }
print(a[0]) -- 1
print(a[-1])-- 4
-- 由于lua数组下标从1开始计算,a中的索引0和-1对应的数被忽略,剩下的元素按顺序排列
print(a[1]) -- 2
print(a[2]) -- 3
print(a[3]) -- 5
print(#a) -- 3
链表
把每个节点用一个表来表示(也只能用表表示),链接则为一个包含指向其他表的引用的简单表字段。
例如,让我们实现一个单链表(singly-linked list),其中每个节点具有两个字段value和next。最简单的变量就是根节点:
1 | --根节点 |
诸如双向链表(doubly-linked list)或环形表(circular list)等其他类型的链表也很容易实现。不过,由于通常无须链表即可用更简单的方式来表示数据,所以在Lua语言中很少需要用到这些数据结构。
栈
我们可以使用 t={} 来表示栈,Push 操作可以使用 table.insert(t,x) 实现,Pop 操作可以使用 table.remove(t) 实现,调用 table.insert(t,1,x) 可以实现在栈的顶部进行插入,调用 table.remove(t,1) 可以从栈的顶部移除
字典
1 | -- 字典声明(两种写法等价) |
7 metatable 元表
在 Lua 中,metatable 是一种特殊的 table ,用于定义其他 table 的行为。通过设置某个 table 的 metatable,你可以控制该 table 的一些操作,例如对 table 进行加法、乘法等操作时的行为。
- 任何
table都可以作为另一个table的元表 - 任何
table都可以有自己的元表 - 当对
table进行一些操作时,就会执行元表中的元方法 - Lua中的每一个值都可以有元表,使用 Lua 只能为
table设置元表;如果要为其他类型的值设置元表,则必须通过C代码或调试库完成。
元方法 (MetaMethod):
1 | __add(a, b) 对应表达式 a + b |
示例:
1 | MetaTable = |
如果要实现__index 指向 MetaTable 自身,是不能在表内实现的:
1 | MetaTable = |
8 thread 线程
9 协程
协同程序 coroutine 是一个 thread 类型的对象
[!quote]
coroutine:”co-“ 表示 “共同”(cooperative)或 “协同”(coordinated)的意思。
routine 常规、惯例
协程操作
1 | Fun = function() |
协程的运行
1 | Func = function() |
协程的返回值
1 | Func = function() |
9 强制类型转换
隐式类型转换
- Lua会根据代码具体实现在 number 与 string 类型之间的自动转换。在任何需要数值的情况下都会尝试将 string 转换为 number,比如在数值运算时。相反,当Lua语言发现在需要 string 的地方出现了 number 时,它就会把 number 转换为 string:
- Lua5.3 提出的
integer整形没有上述功能,规则是只有在两个操作数都是 integer 值时结果才是整型。因此,由于字符串不是整型值,所以任何有字符串参与的算术运算都会被当作浮点运算处理。1
"10" + 1 --结果为11.0
显示类型转换
tonumber :string 转换为 number
1 | tonumber("-3") -- 默认为十进制 |
tostring:将 number 转换为 string
三、运算符
算术运算符:
- 支持
+-*/%^ (幂)// (floor向下取整) - 不支持
++--+=-=/=*=%=
1 | print("123" + 1) |
条件运算符: > < >= <= == ~= (不等于)
逻辑运算符:
and(逻辑与,相当于&&)or(逻辑或,相当于||)not:逻辑非,相当于!(not 返回值固定位 Boolean)- lua 和 C++ 的
and与or或都支持“短路求值”,这是一种优化机制,即在表达式的值已经可以确定整个表达式的值时,就停止对表达式的进一步求值。 andor支持连接任何类型的变量- 在 lua 中,只有 nil 和 false 被认为是假值
1
2
3
4
5
6
7
8
9
10local a, b = 1, 2
print(false and (a+b)) --返回false
-- false在前,and规定当有一个是false时,结果就是false,所以后面就没必要执行计算了。这样可以减小开销
print("hello" and (a+b)) --返回3
-- "hello"不是假值,所以会执行(a+b)
print(true or (a+b)) --返回true
-- or规定有一个是true,结果就是true,这里a+b不会被执行
- lua 和 C++ 的
惯用写法:在Lua语言中,形如 x=x or v 的惯用写法非常有用,它等价于:
1 | if not x then |
即,当 x 未被初始化 (nil 为假)时,将其默认值设为 v(假设x不是Boolean类型的 false )。
不支持位运算符:& |
不支持三目运算符,需要自己实现:? :
⭐使用短路求值实现三目运算符 and or:
1 | local a, b = 1, 2 |
安全访问操作符
Lua 没有类似 C# 中的 ? 安全访问符,但我们可以使用 lua 语法模拟
1 | --C#写法: |
四、控制流
lua 不支持switch
if then end
注意 elseif 连写, end 结尾
1 | if a > 1 then |
while do end
相当于 while
1 | a = 1 |
repeat until
重复执行直到条件为真
和 C++中的 do while 不同,do while 中 do 是入口条件。而这里 until 是出口条件
1 | a = 1 |
for do end
数值型 for
注意,在循环开始前,三个表达式(参数)都会运行一次。
1 | -- 前两个参数表示i从1开始,当 i>10 时结束循环 |
for 循环遍历 table
1 | t = {10,print,12,"hi"} |
泛型 for
与数值型 for 不同,泛型 for 可以使用多个变量,这些变量在每次循环时都会更新。当第一个变量变为nil时,循环终止。
break、return、goto
break 和 return 语句用于从当前的循环结构中跳出
goto 语句则允许跳转到函数中的几乎任何地方。goto 语句慎用,详情见 8.3 节
所有函数的最后都有一个隐含的return,因此我们不需要在每一个没有返还值的函数最后书写return语句。
五、迭代器
面试考点:ipairs 和 pairs 的区别
ipairs
全称:indexed pairs 索引对,ipairs 是专门用于处理数字索引的。
从第一个非空的数字索引开始,一直迭代到第一个空值为止。通常用于遍历数组,因为它只考虑连续的数字索引。
和 pairs 不同,ipairs遍历是按照索引顺序进行的
ipairs 遍历也是从下标 1 开始,忽略小于 0 的下标:
1 | A = { [0] = 1, [-1] = 2, 3, 4 } |
ipairs 只能遍历连续索引,如下所示:
1 | A = { 1, 2, 3, 4, [7] = 5, 6 } |
我们可以只遍历键,或同时遍历键值,但无法单独遍历值。可能会见到这如下写法,看似时只遍历了value:
1 | for _, value in ipairs(A) do |
实际上在 lua 中 _ 也可以作为变量名,上述写法和常规写法实际是相同的,仍是同时遍历键值
1 | for index, value in ipairs(A) do |
pairs
pairs迭代表的所有键值对。pairs 适用于任何表,无论其键是数字还是字符串。它迭代表中的所有键值对,不考虑键的类型。
受限于表在Lua语言中的底层实现机制,遍历过程中元素的出现顺序可能是随机的,相同的程序在每次运行时也可能产生不同的顺序。唯一可以确定的是,在遍历的过程中每个元素会且只会出现一次。
pairs 可以获取所有的键值,不会受不连续的或小于 0 的下标影响
1 | A = { [-1] = 1, age = 25, [0] = 5, city = "New York" } |
nil 会被忽略,但不会截断数组
1 | A = { 1, 2, 3, nil, 4 } |
六、function 函数
- 在 lua 中
function是一种类型 - Lua 程序既可以调用 Lua 语言编写的函数,也可以调用 C 语言(或者宿主程序使用的其他任意语言)编写的函数。
函数是第一类值
在 Lua 语言中,函数是严格遵循词法定界的第一类值。
- “第一类值” 意味着 Lua 语言中的函数与其他常见类型的值(例如数值和字符串)具有同等权限:一个程序可以将某个函数保存到变量中(全局变量和局部变量均可)或表中,也可以将某个函数作为参数传递给其他函数,还可以将某个函数作为其他函数的返回值返回。
- “词法定界” 意味着 Lua 语言中的函数可以访问包含其自身的外部函数中的变量(也意味着 Lua 语言完全支持 Lambda 演算)。 ^awkby7
- 在 Lua 中所有的函数都是匿名的。像其他所有的值一样,函数并没有名字。当讨论函数名时,比如 print,实际上指的是保存该函数的变量。
函数写法
1 | -- 写法一(推荐) |
局部函数
1 | local function func() |
定义局部递归函数要注意:
1 | local fact = function(n) |
当 Lua 语言编译函数体中的 fact(n-1)调用时,局部的 fact 尚未定义。因此,这个表达式会尝试调用全局的 fact 而非局部的 fact。我们可以通过先定义局部变量再定义函数的方式来解决这个问题:这样,函数内的 fact 指向的是局部变量
1 | local fact |
参数与返回值
有参:
1 | PrintText = function(a) |
有返回值:
1 | -- lua函数不需要声明返回值类型 |
变长参数:
1 | function PrintText(...) |
当函数只有一个参数且该参数是字符串常量或表构造器时,括号是可选的 (可读性不好):
1 | print "Hello World!" |
参数和返回值数量
调用函数时使用的参数个数可以与定义函数时使用的参数个数不一致。Lua 语言会通过抛弃多余参数和将不足的参数设为 nil 的方式来调整参数的个数
Lua 语言根据函数的被调用情况调整返回值的数量。
当函数被作为一条单独语句调用时,其所有返回值都会被丢弃;
当函数被作为表达式(例如,加法的操作数)调用时,将只保留函数的第一个返回值。
只有当函数调用是一系列表达式中的最后一个表达式(或是唯一一个表达式)时,其所有的返回值才能被获取到。否则只返回一个结果
- 什么叫一系列表达式中的最后一个表达式? 例子如下:
1
2
3
4
5
6
7function func()
return "a", "b"
end
--函数调用
x, y, z = func(), 2; -- 此时func()不是最后一个表达式,
x, y, z = 1, func(); -- 此时func()就是以后一个表达式
- 什么叫一系列表达式中的最后一个表达式? 例子如下:
将函数调用用一对圆括号括起来可以强制其只返回一个结果
1
print((func()))
变长参数的遍历
要遍历可变长参数,函数可以使用表达式 {...} 将可变长参数放在一个表中,就像上文示例中所做的那样。
不过,在某些罕见的情况下,如果可变长参数中包含无效的 nil,那么 {...} 获得的表可能不再是一个有效的序列。此时,就没有办法在表中判断原始参数究竟是不是以 nil 结尾的。
此时也不能用 # 获取长度,不准确(当序列中存在 nil 值时)????
对于这种情况,Lua 语言提供了函数 table.pack。该函数像表达式 {...} 一样保存所有的参数,然后将其放在一个表中返回,但是这个表还有一个保存了参数个数的额外字段 n。例如,下面的函数使用了函数 table.pack 来检测参数中是否有 nil:
1 | function nonils(...) |
另一种遍历函数的可变长参数的方法是使用函数 select。函数 select 总是具有一个固定的参数 selector ,以及数量可变的参数。
- 如果 selector 是数值 n,那么函数 select 则返回第 n 个参数后的所有参数;
- 否则,selector 应该是字符串”#”,以便函数 select 返回额外参数的总数。

通常,我们在需要把返回值个数调整为 1 的地方使用函数 select,因此可以把 select(n,…)认为是返回第 n 个额外参数的表达式。
函数嵌套
1 | function PrintText(a) |
或者这样写更简洁:
1 | function PrintText(a) |
再次强调,在 lua 中 function 只是一种变量类型,所以我们可以将它作为返回值并保存到新变量中。
闭包
![[Lua精粹#^awkby7]]
当编写一个被其他函数 B 包含的函数 A 时,被包含的函数 A 可以访问包含其的函数 B 的所有局部变量,我们将这种特性称为词法定界( lexical scoping )
1 | function newCounter() |
在上述代码中,匿名函数访问了一个非局部变量(count)并将其当作计数器。然而,由于创建变量的函数(newCounter)己经返回,因此当我们调用匿名函数时,变量 count 似乎已经超出了作用范围。
但其实不然,由于闭包(closure )概念的存在,Lua 语言能够正确地应对这种情况。简单地说,一个闭包就是一个函数外加能够使该函数正确访问非局部变量所需的其他机制。如果我们再次调用 newCounter,那么一个新的局部变量 count 和一个新的闭包会被创建出来。
[!summary]
从技术上讲,Lua 语言中只有闭包而没有函数。函数本身只是闭包的一种原型。不过尽管如此,只要不会引起混淆,我们就仍将使用术语“函数”来指代闭包。
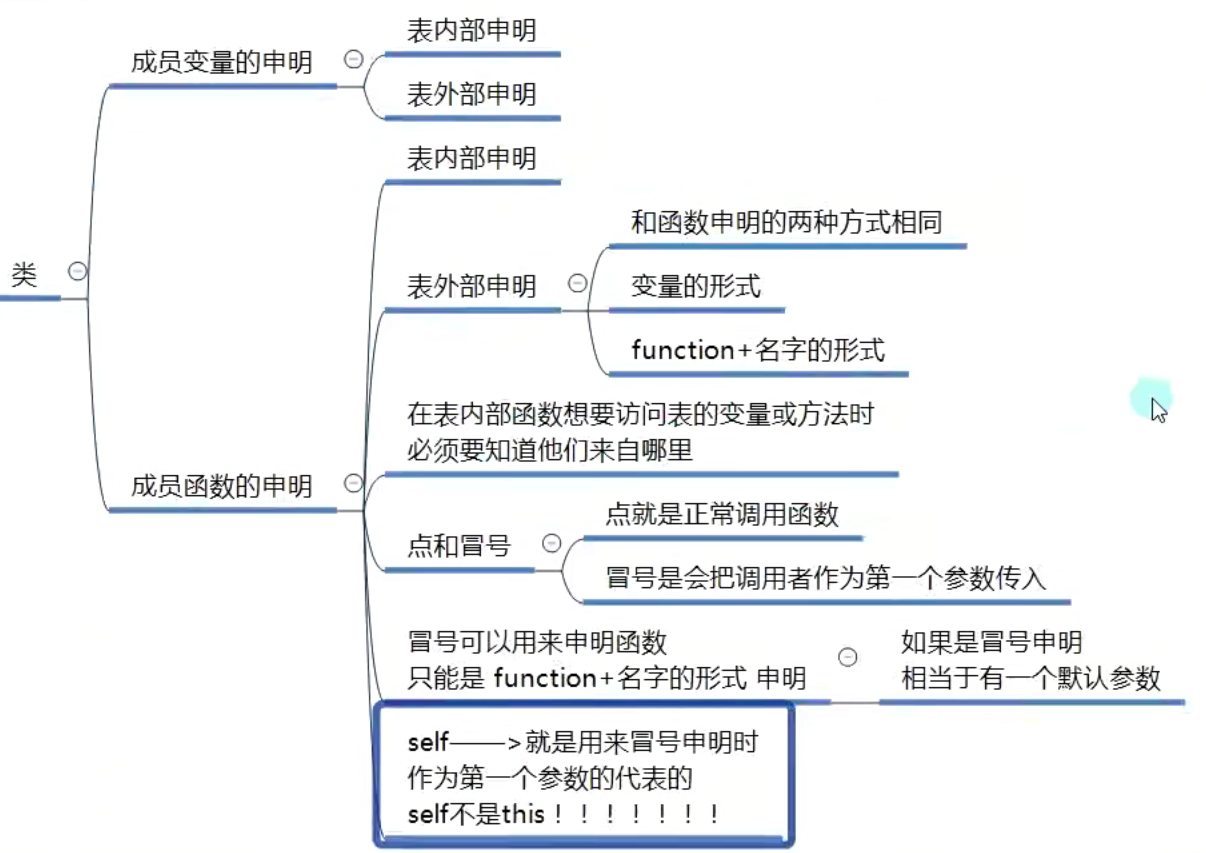
: 和 self
self 类似于 this 指针,大多数面向对象语言都隐藏了这个机制,在编码时不需要显示的声明这个参数,就可以在方法内使用 this(例如 C++和 C#)。在 lua 中,提供了冒号操作符 : 来隐藏这个参数。
1 | local t = {a = 1, b = 2} |
冒号操作符是 Lua 提供的面向对象风格的调用,形如 o:foo() 的表达式意为调用对象 o 的 foo 方法。
冒号的作用有两个:
- 对于方法定义来说,会增加一个额外的隐藏形参(self);
- 对于方法调用来说,会增加一个额外的实参(表自身作为第一个实参)
冒号只是一种语法机制,提供的是便利性,并没有引入任何新的东西。使用冒号完成的事情,都可以使用点语法来完成。看下面的例子:
1 | local t = {a = 1, b = 2} |
尾调用
1 | function f(x) |
当一个函数的最后一个动作是调用另一个函数而没有再进行其他工作时,就形成了尾调用。
当函数 f 调用完函数 g 之后,f 不再需要进行其他的工作。这样,当被调用的函数执行结束后,程序就不再需要返回最初的调用者。因此,在尾调用之后,程序也就不需要在调用栈中保存有关调用函数的任何信息。当 g 返回时,程序的执行路径会直接返回到调用 f 的位置。由于尾调用不会使用栈空间,所以一个程序中能够嵌套的尾调用的数量是无限的
注意,尾调用要求没有进行其他工作
1 | return g(x)+1 --调用后又进行了加法,所以不是尾调用 |
六、模块和包
[!NOTE]
包(Package)是包(module)的集合
require
一个模块( module )就是一些代码( Lua 或 C ),这些代码可以通过函数 require 加载,然后创建和返回一个 table。这个表就像是某种命名空间,其中定义的内容是模块中导出的东西,比如函数和常量。
使用表来实现模块的显著优点之一是,让我们可以像操作普通表那样操作模块,并且能利用Lua语言的所有功能实现额外的功能。
例如,所有的标准库都是模块。我们可以按照如下的方法使用数学库:
1 | local m = require "math" |
独立解释器会使用跟如下代码等价的方式提前加载所有标准库,这种提前加载使得我们可以不用费劲地编写代码来加载模块 math 就可以直接使用函数 math.sin。
1 | math = require "math" |
- require 函数,载入同样的 lua 文件时,只有第一次的时候会去执行,后面的相同的都不执行了。
- 如果你要让每一次文件都会执行的话,你可以使用
dofile("name")函数 - 如果你要玩载入后不执行,等你需要的时候执行时,你可以使用 loadfile()函数,如下所示:
1
2local hello = loadfile("A") --脚本A不会立即执行
hello() -- 调用时,脚本A才执行
多脚本交互示例:
1 | Var1 = 123; |
1 | local ARef = require("A") -- 执行脚本A |
特别的,我们可以在脚本 A 末尾执行 return 语句,这样 require(“A”)获取返回值。
1 | print("脚本A执行"); |
1 | local ARef = require("A") -- 执行脚本A |
如果不在同一文件夹之下的脚本,则需要指明文件夹名称,例如脚本 A 要访问 Layer 文件夹下的脚本 C,则脚本名填写成"Layer. C"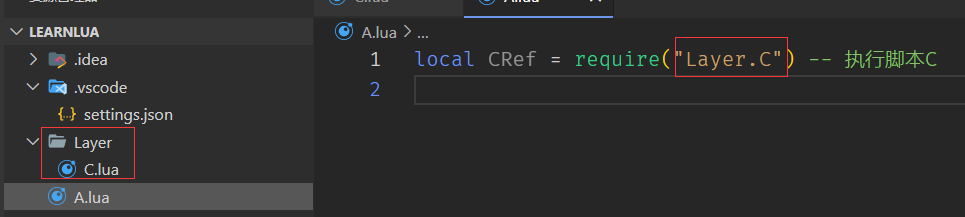
package. loaded
package.loaded是一个全局 table,用于追踪已经加载的模块。每当使用require加载一个模块时,该模块的信息会被存储在package.loaded表格中,以便在后续的require调用中避免重复加载相同的模块。
加载过程:
首先,函数 require 在表 package.loaded 中检査模块是否已被加载。如果模块已经被加载,函数require就返回相应的值。因此,一旦一个模块被加载过,后续的对于同一模块的所有require调用都将返回同一个值,而不会再运行任何代码。
如果模块尚未加载,那么函数require则搜索具有指定模块名的Lua文件(搜索路径由变量package.path指定)。如果函数require找到了相应的文件,那么就用函数loadfile 将其进行加载,结果是一个我们称之为加载器( loader )的函数(加载器就是一个被调用时加载模块的函数)
如果函数require找不到指定模块名的Lua文件,那么它就搜索相应名称的C标准库。 (在这种情况下,搜索路径由变量 package.cpath指定)如果找到了一个C标准库,则使用底层函数package.loadlib进行加载,这个底层函数会查找名为luaopen_ modname 的函数。在这种情况下,加载函数就是loadlib的执行结果,也就是一个被表示为Lua函数的C语言函数luaopen_ _modname_ 。
不管模块是在Lua文件还是C标准库中找到的,函数require此时都具有了用于加载它的加载函数。为了最终加载模块,函数require带着两个参数调用加载函数:模块名和加载函数所在文件的名称(大多数模块会忽略这两个参数)。如果加载函数有返回值,那么函数require会返回这个值,然后将其保存在表package.loaded中,以便于将来在加载同一模块时返回相同的值。如果加载函数没有返回值且表中的package.loaded[@rep{modname}]为空,函数require就假设模块的返回值是 true 。如果没有这种补偿,那么后续调用函数require时将会重复加载模块。
要强制函数require加载同一模块两次,可以先将模块从 package.loaded 中删除(令其为 nil):下一次再加载这个模块时,函数 require 就会重新加载模块。
1 | package.loaded.modname = nil |
编写模块的基本方法
在Lua语言中创建模块的最简单方法是,创建一个表并将所有需要导出的函数放入其中
1 | local M = {} --模块 |
有些人不喜欢最后的返回语句。一种将其省略的方式是直接把模块对应的表放到package.loaded中:
1 | local M = {} --模块 |
在模块的最后加上return语句更清晰。如果我们忘了return语句,那么在测试模块的时候很容易就会发现问题。
另一种编写模块的方法是把所有的函数定义为局部变量,然后在最后构造返回的表
1 | local M = {} --模块 |
这种方式的优点在于,无须在每一个标识符前增加前缀M.或类似的东西。通过显式的导出表,我们能够以与在模块中相同的方式定义和使用导出和内部函数。这种方式的缺点在于,导出表位于模块最后而不是最前面(把前面的话当作简略文档的话更有用),而且由于必须把每个名字都写两遍,所以导出表有点冗余(这一缺点其实可能会变成优点,因为这允许函数在模块内和模块外具有不同的名称,不过程序很少会用到)。
子模块和包
Lua支持具有层次结构的模块名,通过点来分隔名称中的层次。例如,一个名为mod.sub的模块是模块mod的一个子模块( submodule )。一个包( package )是一棵由模块组成的完整的树,它是Lua语言中用于发行程序的单位。
当加载一个名为mod.sub的模块时,函数require依次使用原始的模块名”mod.sub”作为键来查询表package.loaded和表package.preload。这里,模块名中的点像模块名中的其他字符一样,没有特殊含义。
然而,当搜索一个定义子模块的文件时,函数require会将点转换为另一个字符,通常就是操作系统的目录分隔符(例如,POSIX操作系统的斜杠或Windows操作系统的反斜杠)。转换之后,函数require会像搜索其他名称一样搜索这个名称。
这种行为使得一个包中的所有模块能够放到一个目录中。例如,一个具有模块p、p.a和p.b的包对应的文件可以分别是p/init.lua、p/a.lua和p/b.lua,目录p又位于其他合适的目录中。
七、面向对象
类
lua 没有面向对象和类的概念,需要我们自己来模拟。类本质上还是 table,我们是用 table 来模拟一个类。
[!quote]
我们可以参考基于原型的语言(prototype-based language)中的一些做法来在Lua语言中模拟类,例如Self语言(JavaScript采用的也是这种方式)。在这些语言中,对象不属于类。相反,每个对象可以有一个原型(prototype)。原型也是一种普通的对象,当对象(类的实例)遇到一个未知操作时会首先在原型中查找。要在这种语言中表示一个类,我们只需要创建一个专门被用作其他对象(类的实例)的原型对象即可。类和原型都是一种组织多个对象间共享行为的方式。
在 Lua 中,如果 有两个对象A和B,要让B成为A的一个原型,只需要:
1 | setmetatable(A, {__index = B}) |
类的成员和调用方法
1 | -- 类名 |
类成员之间的访问
1 | -- 类名 |
封装
1 | -- 元类 |
继承
1 | -- Meta class |
多重继承
21.3
私有性
Lua 本身不提供访问修饰符,可以模拟实现,了解即可
21.4
21.5
21.6
多态
Lua 中我们可以重写基础类的函数,在派生类中定义自己的实现方式:
1 | -- 派生类方法 printArea |
八、环境
在 Lua 语言中,全局变量并不一定是真正全局的,实际上 Lua 并不存在全局变量。而是模拟了全局变量。
_G
Lua 语言把所有的全局变量保存全局环境表中。
为了方便对全局环境表的操作,Lua 语言将全局环境表保存在全局变量 _G 中(因此,_G._G 与 _G 等价)。通过 _G.XXX 或 _G[varname],你可以访问程序中的所有全局变量,而不需要直接引用它们的名称。
非全局环境 _ENV
一个自由名称( free name )是指没有关联到显式声明上的名称,即它不出现在对应局部变量的范围内。
1 | local z = 10 -- z不是自由名称 |
**Lua语言编译器将代码段中的所有自由名称 x 转换为 _ENV.x**。因此,此前的代码段完全等价于:
1 | local z = 10 |
Lua语言把所有的代码段都当作匿名函数。所以,Lua语言编译器实际上将原来的代码段编译为如下形式:也就是说,Lua语言是在一个名为 _ENV 的预定义上值(非局部变量,upvalue)存在的情况下编译所有的代码段的。
因此,所有的变量要么是绑定到了一个名称的局部变量,要么是 _ENV 中的一个字段,而 _ENV 本身是一个非局部变量(一个上值)。
1 | local _ENV = 某些值 |
_ENV的初始值是任意的表,任何一个这样的表都被称为一个环境。- 通常,当加载一个代码段时,**使用全局环境表初始化代码段的第一个上值
_ENV**。因此,原始的代码段等价于:由于_ENV只是一个普通的变量,因此可以对其赋值或像访问其他变量一样访问它。赋值语句_ENV=nil 会使得后续代码不能直接访问全局变量
1 | local _ENV = 全局环境表 |
总结: Lua 语言中处理全局变量的方式
- 编译器在编译所有代码段前,在外层创建局部变量_ENV;
- 编译器将所有自由名称 var 变换为_ENV. var;
- 函数 load(或函数 loadfile)使用全局环境表初始化代码段的第一个上值(即将被代码段的上值
_ENV初始化为全局环境)
作用:_ENV 的主要用途是用来改变代码段使用的环境。一旦改变了环境,所有的全局访问就都将使用新表。
[!NOTE] _G 和_ENV 的关系
通常,_G和_ENV指向的是同一个表(即全局环境表)。但是,尽管如此,它们是很不一样的实体。_ENV是一个局部变量,所有对“全局变量”的访问实际上访问的都是_ENV。_G则是一个在任何情况下都没有任何特殊状态的全局变量。按照定义,_ENV永远指向的是当前的环境;而假设在可见且无人改变过其值的前提下,_G通常指向的是全局环境。
九、垃圾回收
垃圾回收(Garbage Collection, GC)
Lua 使用自动内存管理,但有时需要手动控制垃圾回收器。
弱引用表(weak table)、析构器(finalizer)和函数 collectgarbage 是在Lua语言中用来辅助垃圾回收器的主要机制。
弱引用表允许收集Lua语言中还可以被程序访问的对象;
析构器允许收集不在垃圾回收器直接控制下的外部对象;
函数
collectgarbage则允许我们控制垃圾回收器的步长。lua 中想让变量被GC,只需要令其等于
nil即可
1 | -- 垃圾回收通用接口 |

弱引用表
一旦一个对象成为了数组的一部分,它就再也无法被回收了!虽然已经没有其他任何地方在引用它,但数组依然在引用它。除非我们告诉Lua语言数组对该对象的引用不应该阻碍对此对象的回收,否则是无法 GC 的。
弱引用表就是这样一种用来告知Lua语言一个引用不应阻止对一个对象回收的机制。 所谓弱引用( weak reference )是一种不在垃圾回收器考虑范围内的对象引用。如果对一个对象的所有引用都是弱引用,那么垃圾回收器将会回收这个对象并删除这些弱引用。
Lua通过【弱引用表】实现弱引用,弱引用表就是元素均为弱引用的表,这意味着如果一个对象只被一个弱引用表持有,那么Lua语言最终会回收这个对象。
瞬表
一种棘手的情况是,一个具有弱引用键的表中的值又引用了对应的键。虽然表中的键是弱引用的,但是表中的值却不是弱引用的。因而对于每一个键来说都存在一个强引用。因此,即使有弱引用的键,这些对象也不会被回收。
Lua语言通过瞬表解决上述问题,在Lua语言中,一个具有弱引用键和强引用值的表是一个瞬表。
在一个瞬表中,一个键的可访问性控制着对应值的可访问性。更确切地说,考虑瞬表中的一个元素 (k,v),指向的 v 的引用只有当存在某些指向 k 的其他外部引用存在时才是强引用,否则,即使 v (直接或间接地)引用了 k ,垃圾回收器最终会收集 k 并把元素从表中移除。
垃圾回收器
一直到Lua 5.0,Lua语言使用的都是一个简单的标记-清除式垃圾回收器(Garbage Collector,GC)。这种收集器又被称为“stop-the-world(全局暂停)”式的收集器,意味着Lua语言会时不时地停止主程序的运行来执行一次完整的垃圾回收周期(garbagecollection cycle)。
每一个垃圾回收周期由四个阶段组成:标记、清理、清除和析构。
- 标记阶段:把根结点集合( root set )标记为活跃。保存在一个活跃对象中的对象是程序可达的,因此也会被标记为活跃(当然,在弱引用表中的元素不遵循这个规则)。当所有可达对象都被标记为活跃后,标记阶段完成。
根结点集合由 Lua 语言可以直接访问的对象组成。在 Lua 语言中,这个集合只包括 C 注册表(主线程和全局环境都是在这个注册表中预定义的元素)
- 清理阶段:在这个阶段中处理析构器和弱引用表。首先,Lua语言遍历所有被标记为需要进行析构、但又没有被标记为活跃状态的对象。这些没有被标记为活跃状态的对象会被标记为活跃(复苏机制),并被放在一个单独的列表中,这个列表会在析构阶段用到。然后,Lua语言遍历弱引用表并从中移除键或值未被标记的元素。
- 清除阶段:遍历所有对象(为了实现这种遍历,Lua语言把所有创建的对象放在一个链表中)。如果一个对象没有被标记为活跃,Lua语言就将其回收。否则,Lua语言清理标记,然后准备进行下一个清理周期。
- 析构阶段:Lua 调用清理阶段被分离出的对象的析构器。
Lua 5.1使用了增量式垃圾回收器。这种垃圾收集器像老版的垃圾收集器一样执行相同的步骤,但是不需要在垃圾收集期间停止主程序的运行。相反,它与解释器一起交替运行。每当解释器分配了一定数量的内存时,垃圾收集器也执行一小步。
Lua 5.2引入了紧急垃圾收集。当内存分配失败时,Lua语言会强制进行一次完整的垃圾收集,然后再次尝试分配。这些紧急情况可以发生在Lua语言进行内存分配的任意时刻,包括Lua语言处于不一致的代码执行状态时,因此,这些收集动作不能运行析构器。
十、反射
反射是程序用来检查和修改其自身某些部分的能力。
Lua这样的动态语言支持几种反射机制:
- 环境允许运行时观察全局变量;
- 诸如type和pairs这样的函数允许运行时检查和遍历未知数据结构;
- 诸如load和require这样的函数允许程序在自身中追加代码或更新代码。
- 不过,还有很多方面仍然是缺失的:程序不能检查局部变量,开发人员不能跟踪代码的执行,函数也不知道是被谁调用的,等等。调试库(debug library) 填补了上述的缺失。
调试库由两类函数组成:自省函数( introspective function )和钩子( hook )。
- 自省函数允许我们检查一个正在运行中的程序的几个方面,例如活动函数的栈、当前正在执行的代码行、局部变量的名称和值。
- 钩子则允许我们跟踪一个程序的执行。
- 调试库中的钩子机制允许用户注册一个钩子函数,这个钩子函数会在程序运行中某个特定事件发生时被调用。有四种事件能够触发一个钩子:
- 每当调用一个函数时产生的 call 事件;
- 每当函数返回时产生的 return 事件;
- 每当开始执行一行新代码时产生的 line 事件;
- 执行完指定数量的指令后产生的 count 事件。
- 调试库中的钩子机制允许用户注册一个钩子函数,这个钩子函数会在程序运行中某个特定事件发生时被调用。有四种事件能够触发一个钩子:
虽然名字里带有“调试”的字眼,但调试库提供的并不是Lua语言的调试器(debugger)。不过,调试库提供了编写我们自己的调试器所需要的不同层次的所有底层机制。
调试库与其他库不同,必须被慎重地使用。首先,调试库中的某些功能的性能不高。其次,调试库会打破语言的一些固有规则,例如不能从一个局部变量的词法定界范围外访问这个局部变量。虽然调试库作为标准库直接可用,但笔者建议在使用调试库的代码段中显式地加载调试库。
十一、Lua 与 C++的交互机制
补:27 C 语言 KPI 总览
Lua 虚拟栈
Lua 和 C/C++ 的交互机制的基础在于 Lua 提供了一个虚拟栈,C++ 和 Lua 之间的所有类型的数据交换都通过这个栈完成。
- 无论何时 C++ 想从 Lua 中调用一个值,被请求的值将会被压入栈,
- 无论何时 C++ 想要传递一个值给 Lua,首先将整个值压栈,然后就可以在 Lua 中调用。
Lua 中,对虚拟栈提供正向索引和反向索引两种索引方式,区别是:
- 正数索引 1 永远表示栈底,
- 负数索引 - 1 永远表示栈顶。
假设当前 Lua 的栈中有 5 个元素,如下图所示:
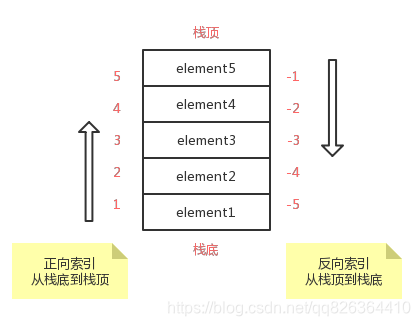
栈上的的每个元素都是一个 Lua 值 (nil,number,string等等).
源码
入栈的数据都由 TValue 这种数据类型来维护。TValue 对应于lua中的所有数据类型, 是一个 {值, 类型} 结构。
1 | /*lobject.h*/ |
value 数据结构
1 | /*lobject.h*/ |
- gc 存其他诸如table, thread, closure, string需要内存管理垃圾回收的类型。
- b 存布尔值
- lua的number是分别由i存整型和n存double
- light userdata类型代表了一个 C 指针
- light C functions的存储
tt 可选值:
1 | /*lua.h*/ |
堆栈的操作
因为 lua 与 c/c++ 是通过栈来通信,lua 提供了 C API 对栈进行操作。
我们先来看一个最简单的例子:
1 |
|
在执行这个例子之前,我们需要引入 Lua.lib 静态库,也就是上文中 extern “C” 中执行的 include。
extern “C”
[[1 C++ Primer#extern “C”]]
主要作用就是为了能够正确实现 C++ 代码调用 C 语言代码。
引入 Lua 静态库
- 首先,新建一个 Visual C++ 的空项目,右键点击工程属性,选择 VC++ 目录,
- 把 **lua 工程中的. h 头文件所在的目录加到包含目录**中
- 把 _Lua 静态库文件所在的目录_加到**库目录**中,
- 最后,点击**链接器 -> 输入 -> 附加依赖项** -> 加上生成的 Lua 静态库,比如 Lua. lib,记得用分号 “;” 与其他库隔开。
- OK,大功告成!
C++ 调用 Lua
C++ 可以获取 Lua 中的值,可以调用 Lua 函数,还可以修改 Lua 文件
- 首先创建虚拟栈(虚拟机)
L - 加载并运行 Lua 文件
- 调用 Lua
- C++ 获取 Lua 值
- 使用
lua_getglocal(L, "varname")来获取值,然后将其入栈。由 lua 去寻找全局变量 str 的值,并将 str 的值返回栈顶(替换 str) - 使用
lua_toXXX将栈中元素取出转成相应的 C++ 类型的值 - 如果 Lua 值为 table 类型的话,通过
lua_getfield和lua_setfield获取和修改表中元素的值
- 使用
- C++ 调用 Lua 函数
- 使用
lua_getglobal来获取函数,然后将其压入栈; - 如果这个函数有参数的话,就需要依次将函数的参数也压入栈;
- 这些准备工作都准备就绪以后,就调用
lua_pcall开始调用函数了,调用完成以后,会将返回值压入栈中;
- 使用
- C++ 获取 Lua 值
示例:
新建一个简单的 lua 放到工程的同级目录下
例如:hello.lua
1 |
|
然后,我们写一个 Lua1. cpp 来访问 lua 中的数据
1 | lua_getglobal(L, "tbl"); |
代码中,已经有很详细的注释了,这里总结一下:
1. 读取 lua 的全局变量:
1 | lua_getglobal(L, "add"); // 获取函数,压入栈中 |
内部实现:1. 把全局变量 str 里的值压栈 2. 由 lua 去寻找全局变量 str 的值,并将 str 的值返回栈顶(替换 str)
注意:如果存在相同命名的其他变量、table 或函数,就会报错(读取位置发生访问冲突)
2. 读取 table 中的键值:
1 | int add(int a,int b) { |
lua_getglobal 方法跟上面的实现是一样的。
lua_getfield 方法:
内部实现:1. 把 name 压入栈中,2. 由 lua 去寻找 table 中 name 键的值,如果键存在,将键值返回栈顶(替换 name)
注意:这里的参数 - 1,就是表示把 table 中的键值返回到栈顶。
3. 调用 lua 中的函数:
1 | int add(lua_state *L) { |
Lua 调用 C++
Lua 可以调用由 C++ 定义、实现具体的函数
步骤:
- 将 C++ 的函数包装成 Lua 环境认可的
Lua_CFunction格式 - 将包装好的函数注册到 Lua 环境中
- 像使用普通 Lua 函数那样使用注册函数
包装 C++ 函数
为了从 Lua 脚本中调用 C++ 函数,需要将被调用的 C++ 函数从普通的 C++ 函数包装成 Lua_CFunction 格式,并需要在函数中将返回值压入栈中,并返回返回值个数。
1 | avg, sum = average(10, 20, 30, 40, 50) |
例如有一个 C++ 函数:
1 |
|
包装为:
1 | // 设置lua中的全局变量 |
示例:
新建一个简单的 lua 放到工程的同级目录下
avg. lua
1 | // 设置lua中table |
然后,创建一个 Lua2. cpp:
1 | static int average(lua_State *L) { |
1. 读取 C++ 的变量:
1 | /* 注册函数 */ |
lua_setglobal (L, “age”) 内部实现: 1. 先将值出栈,保存值,2. 在 lua 中,把值存储到全局变量 age 中
2. 调用在 C++ 中创建的新表的元素:
1 | avg, sum = mylib.average(10, 20, 30, 40, 50) |
lua_setglobal (L, “newTable”) 内部实现: 1. 先将 table 出栈,保存 table,2. 在 lua 中,存储到 newTable 表中
在 lua 中,print (“name”, newTable. name),使用 newTable. name 调用在 C++ 中创建的新表的元素。
3. 调用 C++ 中的函数:
- 将 C++ 的函数包装成 Lua 环境认可的 Lua_CFunction 格式
- 将包装好的函数注册到 Lua 环境中
- 像使用普通 Lua 函数那样使用注册函数
包装 C++ 函数:
1 |
|
将包装好的函数注册到 Lua 环境中
1 | int lua_gettop (lua_State *L); //返回栈顶索引(即栈长度) |
在 lua 中正常调用
1 | LUA_API void (lua_pushnil) (lua_State *L); |
把 C++ 的函数封装成模块
把 C++ 的函数封装成模块:
①将 C++ 的函数包装成 Lua 环境认可的 Lua_CFunction 格式,调用 luaL_newlib,放入到一个 lua 表中压入栈里。
②将自定义模块,注册到 Lua 环境中。
③在 lua 中,加上自定义模块名调用 C++ 函数。
avg. lua,这里的 lua 文件,在调用 C++ 的函数时,需要加上自定义的模块名。比如,我们定义模块名为 mylib。
1 | LUA_API int (lua_isnumber) (lua_State *L, int idx); |
Lua1. cpp
1 | LUA_API lua_Number (lua_tonumberx) (lua_State *L, int idx, int *isnum); |
Lua 调用 C++ 类注册生成的 Lua 模块
由于篇幅的限制,请移步:https://blog.csdn.net/qq826364410/article/details/88652441
在 Lua 中以面向对象的方式使用 C++ 注册的类
由于篇幅的限制,请移步:https://blog.csdn.net/qq826364410/article/details/88639408
Lua 和 C++ 交互:全局数组交互
https://blog.csdn.net/qq826364410/article/details/88713839
补充
这里补充其他一些栈操作:
1 | LUA_API int (lua_getglobal) (lua_State *L, const char *name); |
下面就分两个主要部分进行介绍(C++ 和栈操作;以及 Lua 和栈操作)
- C++ 和栈之间操作相关函数
①c -> stack 将 C++ 数据压到栈里函数: lua_pushxxx
1 | LUA_API void (lua_setglobal) (lua_State *L, const char *name); |
②stack -> c 判断栈里类型相关函数: lua_isxxx (lua_State *L, int idx)
1 | LUA_API int (lua_isnumber) (lua_State *L, int idx); |
③stack -> c 获取栈里数据相关函数:lua_toxxx (lua_State *L, int idx)
1 | LUA_API lua_Number (lua_tonumberx) (lua_State *L, int idx, int *isnum); |
- Lua 和栈之间的操作相关函数
①从 Lua 中得到数据放到栈里进行操作:lua_getxxx
1 | LUA_API int (lua_getglobal) (lua_State *L, const char *name); |
②从栈里将数据写入到 Lua 中: lua_setxxx
1 | LUA_API void (lua_setglobal) (lua_State *L, const char *name); |
总结
Lua 和 C++ 是通过一个虚拟栈来交互通信的。
C++ 调用 Lua:由 C++ 先把函数名、变量名、table 中键放入栈中,然后把函数名、变量名、table 中键出栈,并返回对应的值到栈顶,再由栈顶返回 C++。
Lua 调 C++:
Lua 调用 C++ 的函数: 先把普通的 C++ 函数包装成 Lua_CFunction 格式,然后注册函数到 Lua 解释器中,然后由 Lua 去调用这个模块的函数。
Lua 以面向对象的方式调用 C++ 的类: 新建一个元表 metatable,并设置元表里 key 为 “__index” 的值的为 metatable 本身,然后将成员操作方法添加到元表 metatable 里,在创建对象函数中,把元表赋值给对象指针,这样通过 “: “ 操作符就可以找到对应的方法了。
十二、热更新
常见的 Lua 热更新都是在客户端下载所有 Lua 代码之后重启游戏,以实现重载所有数据和函数的目的。但在实际开发过程中,如果每次都要改完 Lua 代码重启游戏,正常人都不能接受。
除这种热更方式之外,其实还可以实现运行时热更,或者叫无感知热更。可以做到在玩家运行游戏的时候偷偷更新一部分代码。
很多项目会将只负责处理界面的 View 层 Lua 代码在每次调用时重新读取,以此实现不重启地更新代码。但这样依然有局限性——如果需要在数据层等其他模块修改函数,这些修改都无法生效。因为如果直接require,旧的数据都会丢失。
要实现比较合理的运行时热更新,除了设计热更的逻辑之外,前提是遵循一些约定。在规定热更新约定之前,先了解一下 Lua 热更新涉及的原理。
热更新原理
require 机制
从 Lua 5.1 开始,Lua 加入了标准的模块管理机制,可以把一些公用的代码放在一个文件里,以 API 接口的形式在其他地方调用,有利于代码的重用和降低代码耦合度。
Lua 的模块是由变量、函数等已知元素组成的 table,因此创建一个模块很简单,就是创建一个 table,然后把需要导出的常量、函数放入其中,最后返回这个 table 就行。
以下为创建自定义模块 exmaple.lua,文件代码格式如下:
1 | exmaple = {} |
在其他模块中,需要调用exmaple.lua模块的函数,则需要require
1 | require("exmaple") |
或者
1 | require "exmaple" |
require 之后,Lua 的 package.loaded 中就会有 exmaple.lua 模块的数据,并且只有第一次 require 会执行 exmaple.lua 中的内容,之后再次 require 就会直接返回 package.loaded["exmaple"]。
这样的话,如果想要更新 exmaple.lua 的内容,就需要先清空 package.loaded["exmaple"] 再 require。
1 | package.loaded["example"] = nil |
似乎这样就实现了简单的热更,但这远远不够。因为清空package.loaded["exmaple"]会导致丢失原有的数据,下面是一个简单的例子:
1 | local t = {} |
如果按照上面的方式热更,每次t.data都会被重置为 0,显然这不是我们想要的。
这种情况下,t.data 作为函数 t.func 的 upvalue(上值)会被重置。
upvalue
上面讲到的就是 upvalue 的例子,在游戏运行时,我们不会希望数据被覆盖或清空,应该尽量在保留原有数据的情况下替换函数的逻辑。
1 | local count = 0 |
在上面这个例子中,如果使用require机制热更代码,我们需要保存旧函数的count值。Lua 中提供了获取并设置 upvalue 的方法debug.getupvalue和debug.setupvalue。
遍历一个函数的所有 upvalue 并设置 upvalue:
1 | local oldfunc = require "example" |
要注意的是,函数同样可以作为 upvalue,而我们希望使用新的函数、旧的数据。所以在遍历 upvalue 的时候需要判断是否为函数,如果是则要用新的覆盖。
全局语句
在 require 一个模块时,会重新执行其中的全局语句,这会破坏已有的代码逻辑。解决办法有两种,都比较复杂。
- 一种是语法分析,将全局语句变成
local i = {}这种,保留住这个变量,然后把旧的数据复制过来; - 另一种是使用临时环境表执行新模块,执行完切换成旧模块使用的环境表。
这两种方法都比较麻烦,一般需要热更的主要都是各个系统的数据层,这些数据层基本不会包含全局语句的修改,所以我们可以忽略这种情况,只进行数据层的热更新。在多数情况下可以满足需求。
热更新的约定
了解了上面的原理之后,我们要想实现简单的 Lua 运行时热更新,需要满足以下的约定。
不破坏原有数据
游戏运行时许多 Lua 系统中都保存了服务器发来的数据,或者是计算产生的一些数据,我们不希望这些数据被清空或改变。热更新的基础就是更新服务的逻辑,通常只是逻辑发生变化,但原有的值并不能被改变。不为热更多写代码
程序员都比较懒,如果热更需要现在原有的逻辑中加入热更前后进行的操作的话,没人能接受。就像为了热更 C# 而改变原有的代码结构,应该尽量避免额外的负担。只修改逻辑,而非增加
一般来说需要运行时热更的都是改动比较小的更新或者修复一些 bug,这种情况下只要修改函数就可以达到目的,而没有必要新增函数。而且,新增的函数如果使用了 upvalue,新增之后没法给它赋值,因为在旧的模块中不存在这个 upvalue。可以热更嵌套结构中的函数
比如 table 中的函数、table 的 metatable 中的函数等。不改变所有数据和函数的命名
显然,如果改变命名,那谁知道要更新啥呢~
实现思路
一般来说需要热更的话,是你修改了某个XXXModel.lua文件,这个文件在package.loaded中名为XXXSystem.XXXModel。其中XXXSystem是这个 Lua 模块存放的文件夹名称。
- 热更之前要先保存旧模块的全部数据,然后将 package. loaded 置空:
1 | local oldModule |
- 之后直接
require新的模块,然后把新模块记录下来,遍历新模块的所有数据。
- 注意:
- 总体来说,遍历的过程中,元素如果是 table 就保留旧模块的,如果是 function 就用新模块的。
- table 会嵌套 table 和 function,因此这是一个递归的过程。
- function 要用新的,但是 function 的的
upvalue要用旧的。 - table 中的 metatable 同样作为 table 处理,使用
debug.getmetatable获取一个 table 的 metatable 然后进行与 table 一样的操作。 - 对于可能出现循环引用的情况,可以在更新表的时候记录已更新的 table,避免重复处理死循环。
十、编译、执行和错误(略)
[!NOTE] 解释型语言
解释型语言:程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。因此效率比较低相对于编译型语言存在的,源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。比如Python/JavaScript/ Perl /Shell等都是解释型语言。
虽然我们把Lua语言称为解释型语言(interpreted language),为了达到较高的执行效率,lua 代码并不是直接被 Lua 解释器解释执行,而是会先编译为字节码,然后再交给 lua 虚拟机去执行。
Lua 5.0 开始,Lua 就从基于栈的虚拟机( stack-based VM )改为了基于寄存器的虚拟机( register-based VM )。
基于栈的虚拟机有JVM,.Net CLR,javascript V8。基于寄存器的虚拟机有Android Dalvik VM.
编译(compilation)阶段的存在听上去超出了解释型语言的范畴,但解释型语言的区分并不在于源码是否被编译,而在于是否有能力(且轻易地)执行动态生成的代码(即可以在运行时翻译成机器语言)。可以认为,正是由于诸如dofile这样函数的存在,才使得Lua语言能够被称为解释型语言。
dofile loadfile load
dofile,该函数可以立即执行一个指定文件。实际上,函数 dofile 是一个辅助函数,函数 loadfile 才完成了真正的核心工作。与函数 dofile 类似,函数 loadfile 也是从文件中加载Lua代码段,但它不会运行代码,而只是编译代码,然后将编译后的代码段作为一个函数返回。
此外,与函数dofile不同,函数loadfile只返回错误码而不抛出异常。
对于简单的需求而言,由于函数dofile在一次调用中就做完了所有工作,所以该函数非常易用。不过,函数loadfile更灵活。在发生错误的情况中,函数loadfile会返回nil及错误信息,以允许我们按自定义的方式来处理错误。此外,如果需要多次运行同一个文件,那么只需调用一次loadfile函数后再多次调用它的返回结果即可。由于只编译一次文件,因此这种方式的开销要比多次调用函数dofile小得多(编译在某种程度上相比其他操作开销更大)。
函数 load 与函数 loadfile 类似,不同之处在于该函数从一个字符串或函数中读取代码段,而不是从文件中读取。尽管函数load的功能很强大,但还是应该谨慎地使用。相对于其他可选的函数而言,该函数的开销较大并且可能会引起诡异的问题。请先确定当下已经找不到更简单的解决方式后再使用该函数。函数load最典型的用法是执行外部代码(即那些来自程序本身之外的代码段)或动态生成的代码。例如,我们可能想运行用户定义的函数,由用户输入函数的代码后调用函数load对其求值。请注意,函数load期望的输入是一段程序,也就是一系列的语句。如果需要对表达式求值,那么可以在表达式前添加 return ,这样才能构成一条返回指定表达式值的语句。例如:
 微信
微信 支付宝
支付宝



