
【图形系统01】渲染管线
[!NOTE]
本文是对 RTR4 和龙书渲染管线部分内容的总结
1 概述
关于Pipleline
当我们谈到管线时,我们指的是一个由多个阶段组成的过程,每个阶段都完成任务的一部分。在现实世界中,流水线的概念在许多不同的领域中都有应用,比如工厂的生产线和快餐厅的厨房等。
管线的各个阶段都是平行的,这意味着各个阶段依次依赖于上一个阶段的输出。理想情况下,将一个非管道系统划分为 n 个流水线阶段可以提供 n 倍的加速。这种性能提升是使用流水线的主要原因。
例如,一系列人可以快速准备大量的三明治,其中一个人负责准备面包,另一个人添加肉,另一个人添加浇头。每个人将结果传递给排队的下一个人,立即开始制作下一个三明治。如果每个人完成任务需要 20 秒,那么每 20 秒可以制作三个三明治。
管线的速度取决于管线中最慢阶段的速度,最慢的阶段被称为**瓶颈 (bottleneck)**。此时,其他的阶段会等待瓶颈的工作完成,称其他阶段此时处于 starved 状态。因此,优化管线中最慢的阶段可以提高整个管线的性能。
混乱的翻译
[!NOTE] Pipeline 的翻译
Pipleline 也叫流水线,图形渲染领域,更多翻译为“管线” , 后文也采用管线的译法。
渲染管线(Rendering Pipeline)、图形管线、图形流水线(Graphics Pipeline)、图形渲染管线(Rendering Graphics Pipeline) 其实是一个东西,是针对 GPU 硬件来说的。我更习惯翻译成渲染管线。
- 对于渲染管线,将其分为按功能阶段性划分的渲染管线和 GPU 硬件渲染管线(本质相同,都是硬件渲染管线)
- 对于游戏制作中更细分的渲染管线,我将其称为渲染流程(Rendering Processing),如下为天涯明月刀 OL 的渲染流程。渲染流程是个范围更大,更细节的管线。
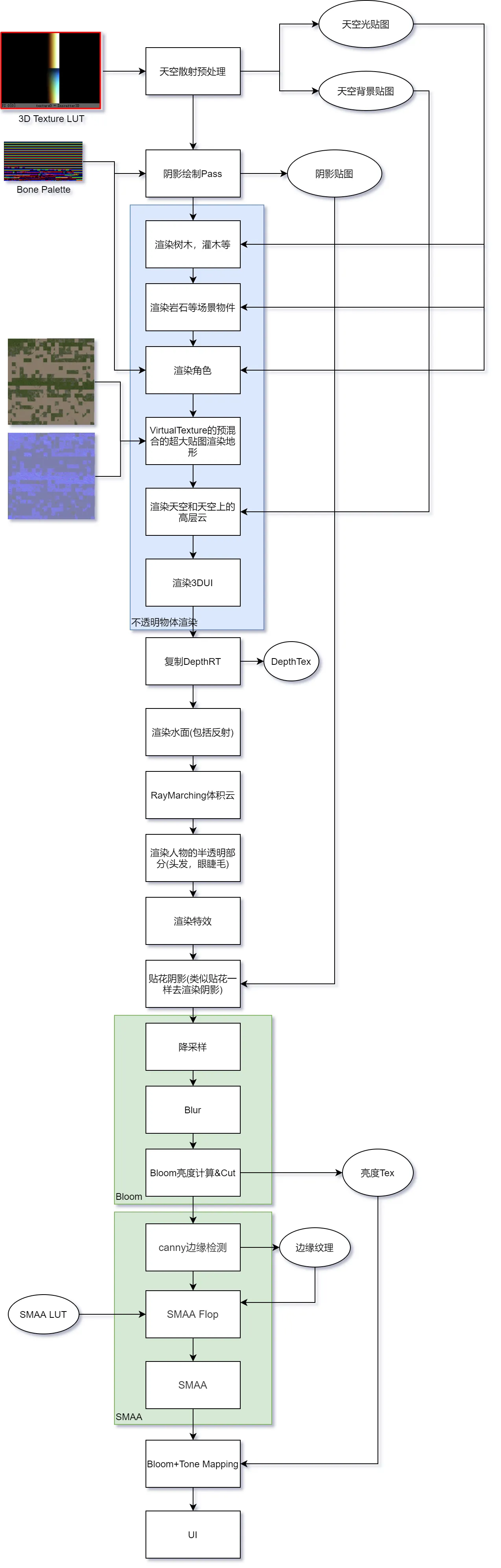
渲染管线
**渲染管线(graphics rendering pipeline)
在计算机图形学中,我们使用渲染管线来实现将 3D 场景转换成 2D 图像的过程。如果给出一台具有确定位置和朝向的摄像机以及某个场景的几何描述,那么渲染管线则是以摄像机为视角进行观察,并据此生成给定 3D 场景 2D 图像的一整套处理步骤。
具体来说,把渲染管线想象为一个工厂里的流水线,里面有不同的加工环节(渲染阶段),可以根据用户需求对每个环节灵活改造或拆卸(可编程或可配置),以此把原始材料(CPU 端向 GPU 端提交的纹理等资源以及指令等) 加工为成品出售给消费者(在 GPU 端,资源流经流水线里的各个阶段, 经指令的调度对其进行处理,最终计算出像素的颜色,将其呈现在用户屏幕上)。
事实上,渲染管线是种模型,将 3D 场景变换至 2D 场景的处理流程抽象分离为不同的流水线阶段,供用户使用。其本质即指令从 CPU 端的应用程序层发送至 API 运行时、驱动层及至 GPU 端(包括二者间的通信,连接都靠 PCle 接口,实质上就是围绕这种总线传递数据),资源数据在内存与显存间游走,最后是 GPU 内部各种引擎、缓存、命令队列等根据指令配合运作将数据转化为显示器可视信号。
2 GPU 硬件渲染管线
DX12 的硬件管线:
[[DX12理论#3 渲染管线]]
DX12 中硬件渲染管线:注意:很多阶段不仅接收上一步的数据作为输入,还可以从 GPU 中取读数据!
![[DX12理论#3.2 概述]]
3 按功能性阶段划分
在划分渲染管线阶段之前,首先需要区分渲染管线的功能性阶段和 GPU 硬件管线阶段区分。
- 功能性阶段是概念性的,是我们为了给一个渲染流程进行基本的功能划分而提出来的。
- GPU 硬件管线则是硬件层上真正用于实现上述功能的流水线。
- 一个图形单元 / Core 可能处理多个功能性阶段,一个功能性阶段可能也会拆分成几个硬件单元。
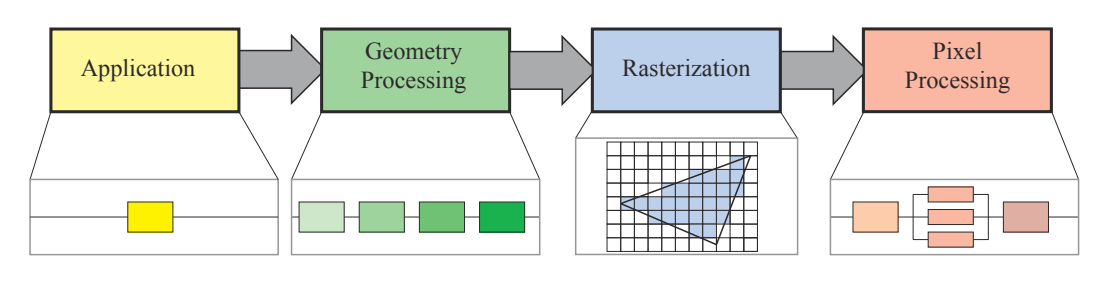
实时渲染管线(real-time rendering pipeline)一般分为如下四个功能性阶段:应用程序阶段 (Application)、几何处理阶段 (Geometry Processing)、光栅化阶段 (Rasterization) 和**像素处理阶段 (Pixel Processing)**。
- 这些阶段中的每个阶段本身也可以是一条管线(如本书描述的几何处理阶段),这意味着它会由几个子阶段组成。
- 这些阶段也可以是(部分的)并行化阶段(如本书描述的像素处理阶段)
- 本书中应用程序阶段是单个过程,但是该阶段也可以进行管线化或并行化。
- 需要注意的是,光栅化阶段可以调用到图元(如三角形)内部的像素。
细节: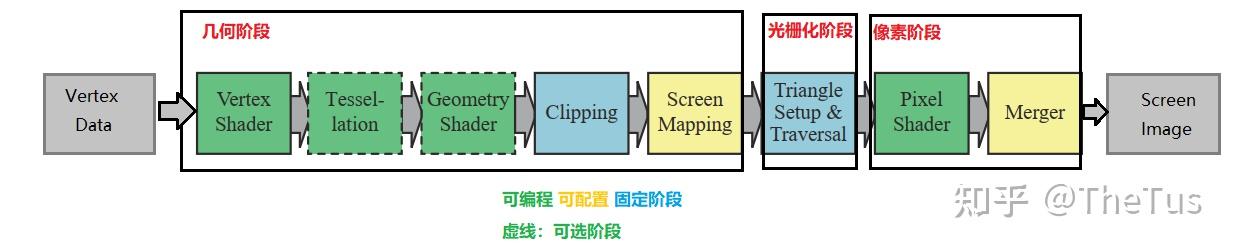
- 顶点着色器在齐次裁剪空间将计算的顶点信息输出
- 片元着色器在屏幕空间接受输入
1 应用程序阶段(输入装配器阶段)
[!NOTE] 关联
产生 DrawCall
[!summary] 任务
主要任务:输入装配
其他任务:粗粒度剔除 (将完全不可见的物体剔除),碰撞检测、处理其他源输入 (键盘、鼠标等)、加速算法…
应用程序阶段是完全可控制的,因为它在 CPU 上执行。并且可以在之后对它进行修改以提高性能表现,另外,此处的修改也会影响后续阶段的性能表现。
应用程序阶段会从内存中读取几何数据 (顶点和索引),再将它装配为几何图元 (geometry primitive) 传递给几何处理阶段。
在 Direct3D 中,我们要通过一种名为顶点缓冲区 ( vertex buffer ) 的特殊数据结构,将顶点与渲染管线相绑定。顶点缓冲区利用连续的内存来存储一系列顶点。
我们要通过指定图元拓扑( primitive topology,或称基元拓扑) 来告知 Direct3D 如何用顶点数据来表示几何图元:
图元拓扑按类型分可以分为:点列表,线条带,线列表,三角形带,三角形列表,具有邻接数据的图元拓扑,控制点点面片列表。
另外,应用程序阶段也可以通过计算着色器在 GPU 上运行。
2 几何处理阶段
[!NOTE] 关联
顶点着色器、曲面细分着色器、几何着色器
[[02 空间变换]]
[!summary] 任务
把顶点坐标变换到屏幕空间中,再交给光栅器进行处理
通过对输入的渲染图元进行多步处理后,这一阶段将会输出屏幕空间的二维顶点坐标、每个顶点对应的深度值、着色等相关信息,并传递给光栅化阶段。
几何处理阶段在 GPU 上运行,它处理应用程序阶段发送的渲染图元,负责大部分的逐三角形和逐顶点操作。
几何处理阶段可以细分多个子阶段:
- **顶点着色器阶段 (Vertex Shading)**,
- 可选阶段
- 曲面细分阶段(tessellation Stage)
- 几何着色阶段(geometry shading)
- 流输出(stream output)。
- 投影阶段 (Projection)
- 裁剪阶段 (Clipping)
- **屏幕映射阶段 (Screen Mapping)**。
后面三个阶段主要功能就是将讲过顶点着色器阶段和可选阶段处理后的顶点投影到屏幕。

顶点着色器阶段
[!summary] 任务
主要任务:
- 计算顶点位置,通过 MV 矩阵从模型空间变换到观察空间
- 传递后续流水线需要的用来插值的数据,如法线和纹理坐标
我们可以利用顶点着色器来实现许多特效,例如变换、光照和置换贴图。请牢记: 在顶点着色器中,不但可以访问输入的顶点数据,也能够访问纹理和其他存于显存中的数据(如变换矩阵与场景的光照信息)。
在顶点着色器(或几何着色器)中是无法进行透视除法的,此阶段只能实现投影矩阵这一环节的运算。而透视除法将在后面交由硬件执行。
曲面细分阶段 Tessellation Stage
[[11 曲线曲面几何]]
概念:
镶嵌 (tessellation):在实时渲染中,我们需要计算并创建 (多个) 三角形对真实曲面进行拟合,这个过程称为镶嵌。在运行时,表面可以被镶嵌为多个小三角形。
控制点(control point):控制点是定义曲面形状的关键元素。它们是二维或三维空间中的点,用于确定曲面的控制网格。一般来说,曲面通过关于控制点的方程计算生成。比如贝塞尔曲线通过控制点控制曲线,三角形可以看作时拥有 3 个控制点的面片。
面片(patch):对于一个参数曲面 $p(u,v)$ ,如果定义域 $(u,v)$ 为矩形,则称该曲面为 patch。可以看成是多个顶点的集合,包含每个顶点的属性。(属性是所有顶点共享的,不是每个顶点有独自的属性)
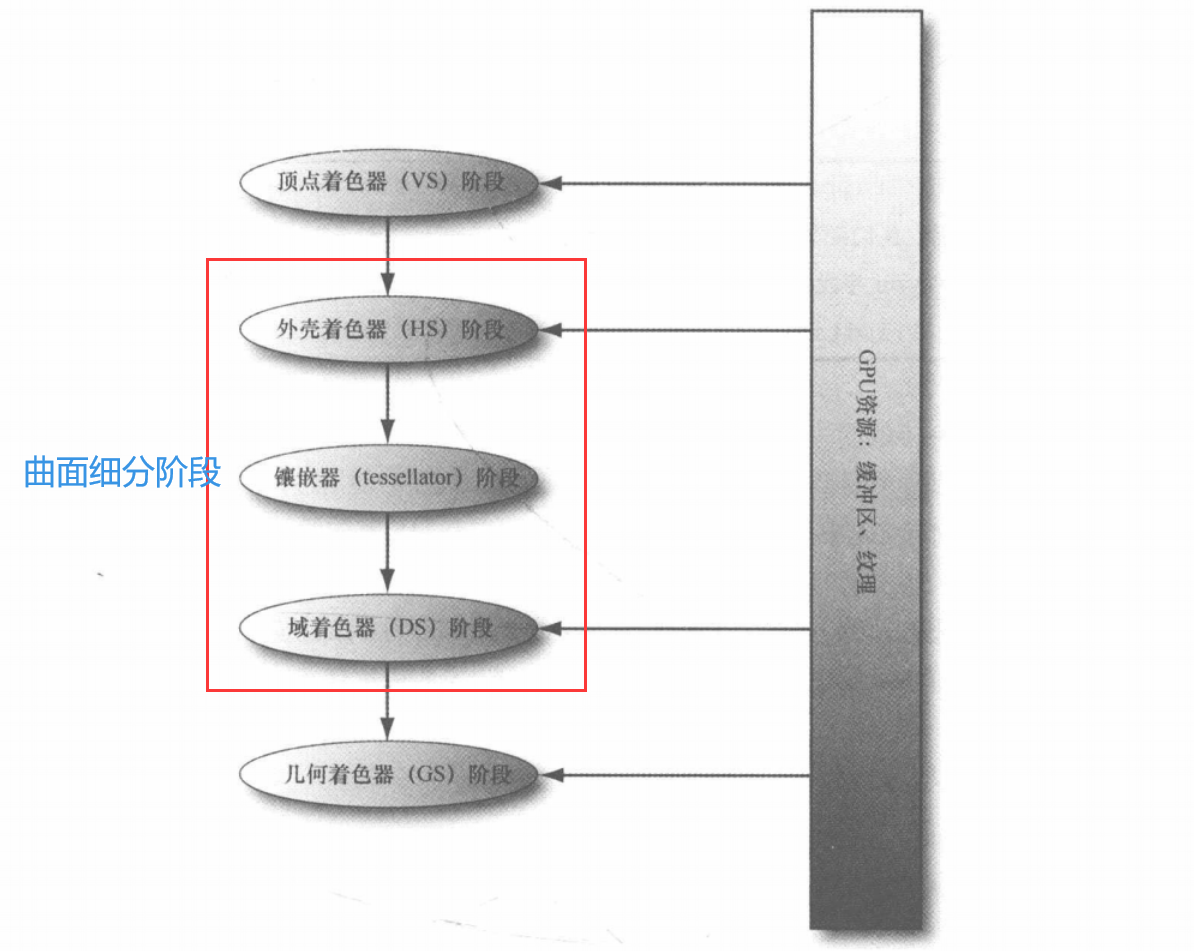
[!NOTE] 关联
- 基于 GPU 实现动态LOD(细节层次 level-of-detail) 机制。
- 在内存中仅维护低模 (low-poly) 网格,再根据需求为它动态地增添额外的三角形,以此节省内存资源。
- 处理动画和物理模拟时采用简单的低模网格,而仅在渲染过程中使用经镶嵌化处理地高模 (high-poly) 网格。
曲面细分阶段 (tessellation stages) 是利用镶嵌化处理技术对网格中三角形进行**细分 (subdivide)**,以此来增加物体表面上的三角形数量。再将这些新的三角形偏移到适当的位置,使网格表现出更加细腻的细节。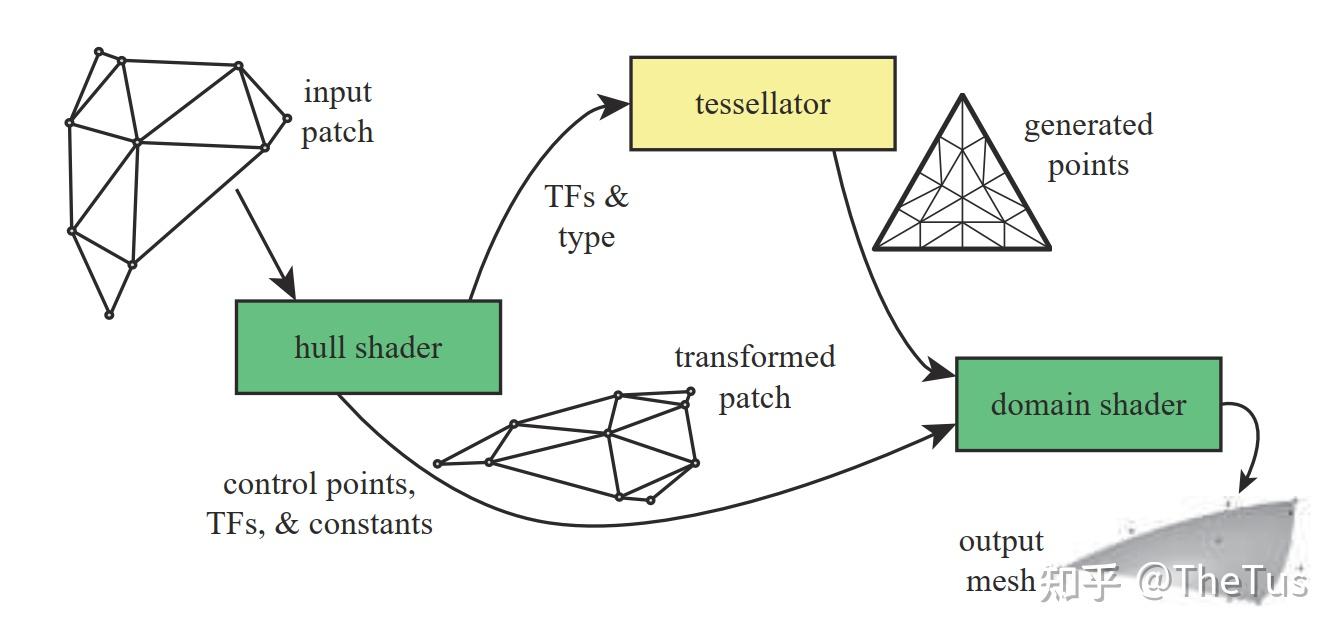
曲面细分阶段是指渲染流水线中参与对几何图形进行镶嵌处理(Tessellating geometry)的三个阶段
- (可编程)外壳着色器阶段 Hull Shader(HS) :细分为两个着色器

- 常量外壳着色器:对每个面片(Patch) 逐一处理,输出网格的曲面细分因子和其他面片信息,曲面细分因子指示了在镶嵌器阶段中将面片细分的份数。
- 优化细节:如果将所有的曲面细分因子设置为 0,则该面片会被后续的处理阶段丢弃,我们可以利用这个特性以每个面片为基准实现视锥体剔除和背面剔除这类优化。
- 控制点外壳着色器:以控制点作为输入和输出,修改输入面片的曲面表示方式。例如,若向外壳着色器阶段输入具有 3 个控制点的三角形,它便可能输出拥有 10 个控制点的贝塞尔三角形面片。
- 常量外壳着色器:对每个面片(Patch) 逐一处理,输出网格的曲面细分因子和其他面片信息,曲面细分因子指示了在镶嵌器阶段中将面片细分的份数。
- (不可编程,由硬件处理)镶嵌器阶段 Tessellator Stage:基于外壳着色器输出的曲面细分因子,对面片进行细分操作。并输出所有新建的顶点和三角形
- (可编程)域着色器阶段 Domain Shader(DS) :
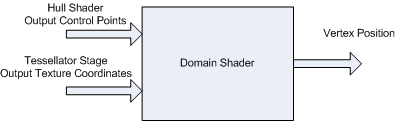
对镶嵌器传来的细分后的顶点进行处理,此时顶点处于面片域空间(patch domain space)。用户可以控制是否将处理后的顶点转换到齐次裁剪空间。(龙书:曲面细分功能开启后,顶点着色器便化身为“处理每个控制点的顶点着色器”(以控制点作为输入,并针对每个控制点执行相应的动画或物理模拟计算),而域着色器”的本质实为“针对已经过镶嵌化的面片进行处理的顶点着色器”)
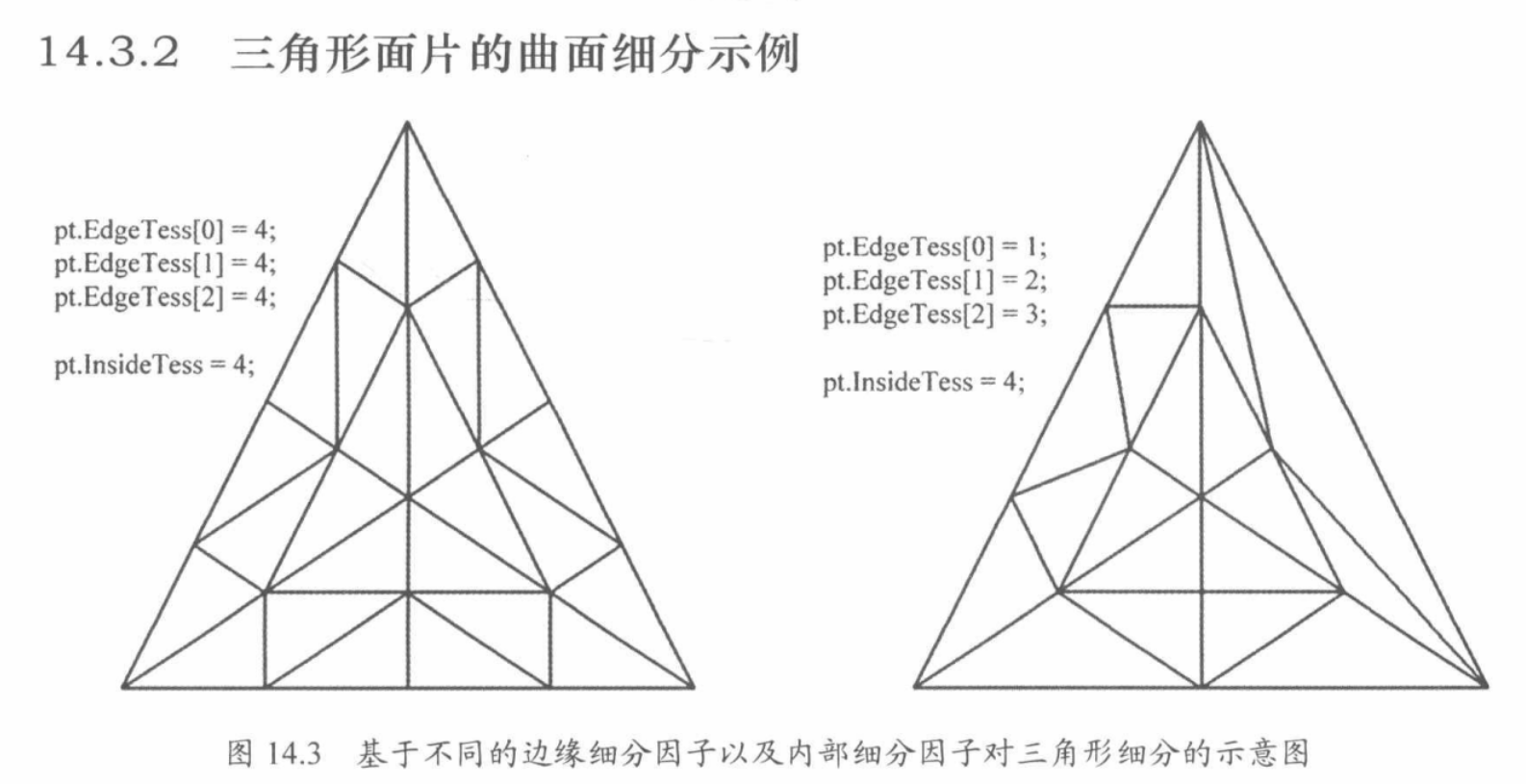
细分因子
- 定义把一条边分为几个部分
- 切分的方法有三种:
- equal_Spacing:把一条边等分(二、三分等等..)

- fractional_even_spacing:向上取最近的偶数,最小值是 2
- 会把周长分为 n-2 的等长部分、以及两端不等长的部分(两端部分和小数有关,具体看 gif)

- 会把周长分为 n-2 的等长部分、以及两端不等长的部分(两端部分和小数有关,具体看 gif)
- fractional_odd_spacing:向上取最近的奇数,最小值是 1
- 会把周长分为 n-2 的等长部分、以及两端不等长的部分

- 会把周长分为 n-2 的等长部分、以及两端不等长的部分
- equal_Spacing:把一条边等分(二、三分等等..)
- 定义内部的三角形/矩形是怎么画出来的
三角形情况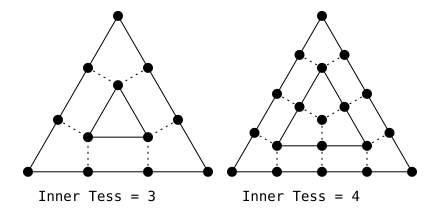
- 例如上图三等分的情况:
- 将三条边三等分,然后从一个端点开始,取邻近的两个切分点做垂线,两者的交点就是新三角形的一个端点。以此类推就是左图的效果。
矩形情况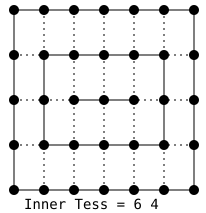
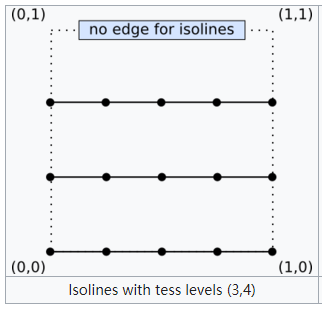
- 同样的,做垂线,交点,直到没有交点或者交于重心一个点
曲面细分 Demo
Demo1:曲面细分算法展示
1 | //曲面细分Demo1 |
Demo2:和和置换贴图结合
基本原理
通过置换贴图的深度,来把顶点沿着它的法线方向进行移动,以此来对 mash 进行形变。
代码部分和上个 Demo 的区别也就是在顶点 shader 部分对顶点进行了位移、和一些计算法线的参数。(因为顶点位移后没有对应的法线贴图,所以需要自己计算一下,具体怎么算先不讲,属于置换贴图部分的知识)
fold title:曲面细分Demo2:与置换贴图结合使用 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177//曲面细分Demo2:与置换贴图结合使用
Shader "Unlit/Tess_Diss_Shader"
{
Properties
{
_MainTex("MainTex",2D) = "white"{}
_DisplacementMap("_DisplacementMap",2D)="gray"{}
_DisplacementStrength("DisplacementStrength",Range(0,1)) = 0
_Smoothness("Smoothness",Range(0,5))=0.5
_TessellationUniform("TessellationUniform",Range(1,64)) = 1
}
SubShader
{
Tags { "RenderType"="Opaque"
"LightMode"="ForwardBase"}
LOD 100
Pass
{
CGPROGRAM
//定义2个函数 hull domain
//引入曲面细分的头文件
float _TessellationUniform;
sampler2D _MainTex;
float4 _MainTex_ST;
sampler2D _DisplacementMap;
float4 _DisplacementMap_ST;
float _DisplacementStrength;
float _Smoothness;
struct VertexInput
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
float3 normal : NORMAL;
float4 tangent : TANGENT;
};
struct VertexOutput
{
float2 uv : TEXCOORD0;
float4 pos : SV_POSITION;
float4 worldPos:TEXCOORD1;
half3 tspace0 :TEXCOORD2;
half3 tspace1 :TEXCOORD3;
half3 tspace2 :TEXCOORD4;
};
VertexOutput vert (VertexInput v)
//这个函数应用在domain函数中,用来空间转换的函数
{
VertexOutput o;
o.uv = TRANSFORM_TEX(v.uv,_MainTex);
//Displacement
//由于并不是在Fragnent shader中读取图片,GPU无法获取mipmap信息,因此需要使用tex2Dlod来读取图片,使用第四坐标作为mipmap的level,这里取了0
float Displacement = tex2Dlod(_DisplacementMap,float4(o.uv.xy,0.0,0.0)).g;
Displacement = (Displacement-0.5)*_DisplacementStrength;
v.normal = normalize(v.normal);
v.vertex.xyz += v.normal * Displacement;
o.pos = UnityObjectToClipPos(v.vertex);
o.worldPos = mul(unity_ObjectToWorld, v.vertex);
//计算切线空间转换矩阵
half3 vNormal = UnityObjectToWorldNormal(v.normal);
half3 vTangent = UnityObjectToWorldDir (v.tangent. xyz);
//compute bitangent from cross product of normal and tangent
half tangentSign = v.tangent. w * unity_WorldTransformParams. w;
half3 vBitangent = cross(vNormal,vTangent)*tangentSign;
//output the tangent space matrix
o.tspace0 = half3(vTangent.x,vBitangent.x,vNormal.x);
o.tspace1 = half3(vTangent.y,vBitangent.y,vNormal.y);
o.tspace2 = half3(vTangent.z,vBitangent.z,vNormal.z);
return o;
}
//有些硬件不支持曲面细分着色器,定义了该宏就能够在不支持的硬件上不会变粉,也不会报错
//顶点着色器结构的定义
struct TessVertex{
float4 vertex : INTERNALTESSPOS;
float3 normal : NORMAL;
float4 tangent : TANGENT;
float2 uv : TEXCOORD0;
};
struct OutputPatchConstant {
//不同的图元,该结构会有所不同
//该部分用于Hull Shader里面
//定义了patch的属性
//Tessellation Factor和Inner Tessellation Factor
float edge[3] : SV_TESSFACTOR;
float inside : SV_INSIDETESSFACTOR;
};
TessVertex tessvert (VertexInput v){
//顶点着色器函数
TessVertex o;
o.vertex = v.vertex;
o.normal = v.normal;
o.tangent = v.tangent;
o.uv = v.uv;
return o;
}
//float _TessellationUniform;
OutputPatchConstant hsconst (InputPatch<TessVertex,3> patch){
//定义曲面细分的参数
OutputPatchConstant o;
o.edge[0] = _TessellationUniform;
o.edge[1] = _TessellationUniform;
o.edge[2] = _TessellationUniform;
o.inside = _TessellationUniform;
return o;
}
[UNITY_domain("tri")]//确定图元,quad,triangle等
[UNITY_partitioning("fractional_odd")]//拆分edge的规则,equal_spacing,fractional_odd,fractional_even
[UNITY_outputtopology("triangle_cw")]
[UNITY_patchconstantfunc("hsconst")]//一个patch一共有三个点,但是这三个点都共用这个函数
[UNITY_outputcontrolpoints(3)] //不同的图元会对应不同的控制点
TessVertex hullProgram (InputPatch<TessVertex,3> patch,uint id : SV_OutputControlPointID){
//定义hullshaderV函数
return patch[id];
}
[UNITY_domain("tri")]//同样需要定义图元
VertexOutput ds (OutputPatchConstant tessFactors, const OutputPatch<TessVertex,3>patch,float3 bary :SV_DOMAINLOCATION)
//bary:重心坐标
{
VertexInput v;
v.vertex = patch[0].vertex*bary.x + patch[1].vertex*bary.y + patch[2].vertex*bary.z;
v.tangent = patch[0].tangent*bary.x + patch[1].tangent*bary.y + patch[2].tangent*bary.z;
v.normal = patch[0].normal*bary.x + patch[1].normal*bary.y + patch[2].normal*bary.z;
v.uv = patch[0]. uv*bary. x + patch[1]. uv*bary. y + patch[2]. uv*bary. z;
VertexOutput o = vert (v);
return o;
}
float4 frag (VertexOutput i) : SV_Target
{
float3 lightDir =_WorldSpaceLightPos0. xyz;
float3 tnormal = UnpackNormal (tex2D (_DisplacementMap, i.uv));
half3 worldNormal;
worldNormal.x=dot(i.tspace0,tnormal);
worldNormal.y= dot (i.tspace1, tnormal);
worldNormal.z=dot (i.tspace2, tnormal);
float3 albedo=tex2D (_MainTex, i.uv). rgb;
float3 lightColor = _LightColor0.rgb;
float3 diffuse = albedo * lightColor * DotClamped(lightDir,worldNormal);
float3 viewDir = normalize (_WorldSpaceCameraPos. xyz-i. worldPos. xyz);
float3 halfVector = normalize(lightDir + viewDir);
float3 specular = albedo * pow (DotClamped (halfVector, worldNormal), _Smoothness * 100);
float3 result = specular + diffuse;
return float4(result, 1.0);
return float4(result,1.0);
}
ENDCG
}
}
Fallback "Diffuse"
}
应用
海浪、雪地等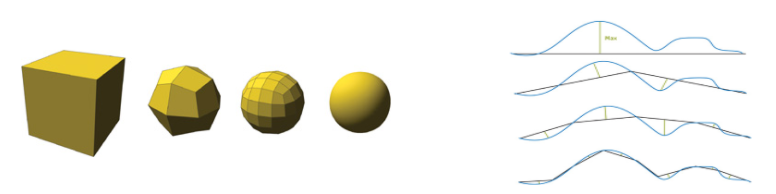
- 如右图一样,将一条直线进行细分,向一条曲线慢慢逼近
和置换贴图(DIsplacement mapping,也叫位移贴图)结合

注意:使用置换贴图,对模型的面数有要求。模型低会显得过于锐利。正是这个原因,让它和曲面细分着色器有着很好的契合度。
几何着色器阶段 Geometry shader
输入为单个图元(三角形、矩形、线等等),通过配置可以不输出图元,也可以输出一个或多个图元。输出的图元类型可能和输入的图元类型不同。
在输出的图元顶点离开几何着色器之前,应当将其变换到齐次裁剪空间。接下来输出的图元会进入光栅化阶段。
输入
- 输入为单个图元(三角形、矩形、线等等)
- 根据不同的图元,shader 中会出现不同的顶点数量
输出
- 输出也为图元(一个或者多个)
- 同时还要定义输出的最大顶点数
- 输出的图元需要自己一个点一个点的自己去构建,顺序很重要(这个着色器最主要的功能:自己构建图元)
流程
- 输入输出结构
- 定义最大输出定点数
- 几何着色器
几何着色器的应用
①几何动画
简单的几何动画、甚至可以做一些破碎的效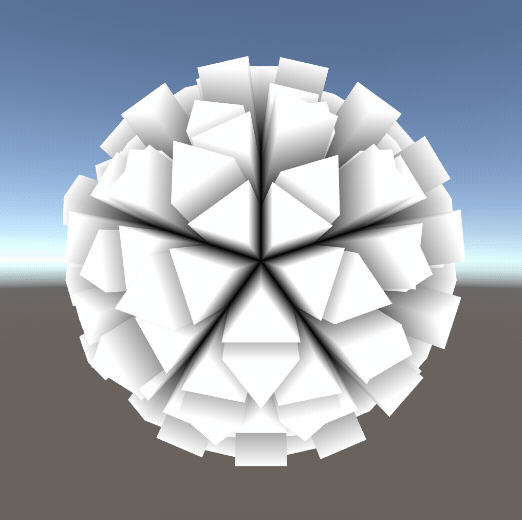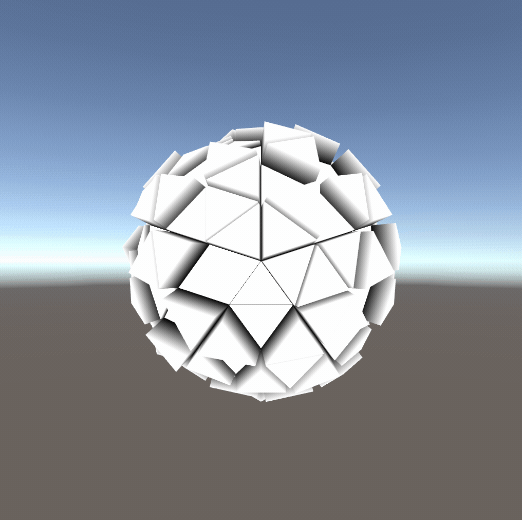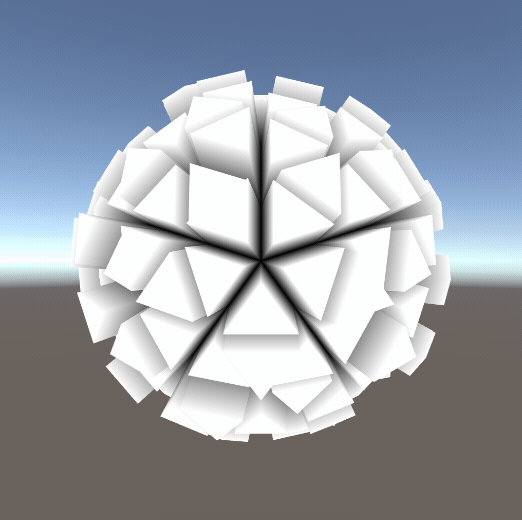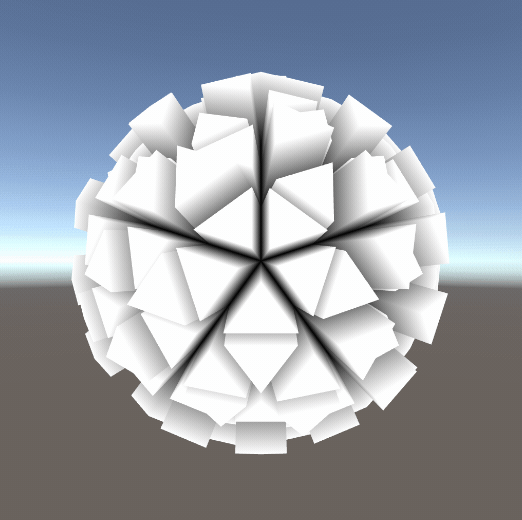

②草地等效果(与曲面细分结合)
菜鸡都能学会的Unity草地shader - 知乎 (zhihu.com)
- 自定义草的画法,再和曲面细分着色器结合,就可以得到一个可以动态调整草密度的一个草地效果。
流输出阶段 Stream-Output Stage
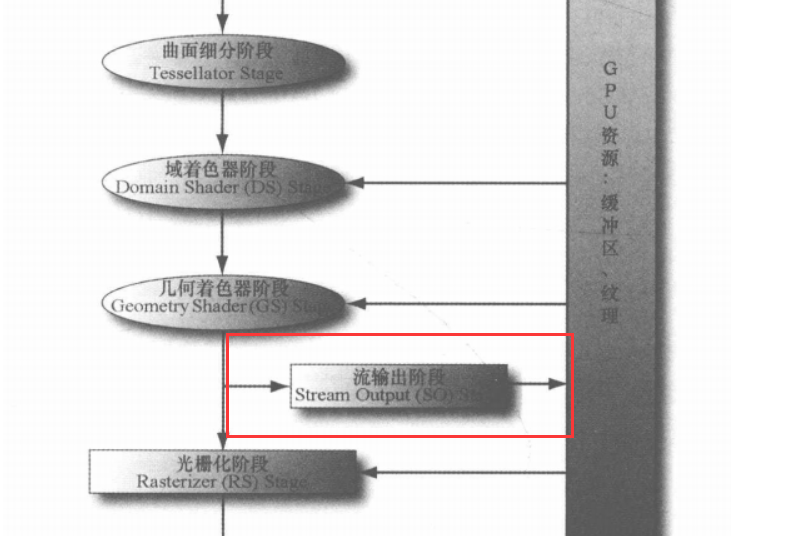
流输出 (SO) 阶段可将顶点数据从之前的有效阶段输出(或流式传输)至内存中的一个或多个缓冲区。流出到内存的数据可以作为输入数据再次循环回到管道,或者从 CPU 读回。
3 光栅化阶段
[!summary] 任务
根据几何处理阶段传来的经过变换和投影的顶点及其关联的着色数据,找到需要渲染的图元(例如一个三角形)内的所有像素,将生成的片元传递给像素处理阶段。
[!NOTE] 片元和像素
片元是在图元经过光栅化阶段后,被分割成一个个像素大小的基本单位。片元其实已经很接近像素了,但是它还不是像素。片元包含了比 RGBA 更多的信息,比如可能有深度值,法线,纹理坐标等等信息。片元需要在通过一些测试(如深度测试)后才会最终成为像素。可能会有多个片元竞争同一个像素,而这些测试会最终筛选出一个合适的片元,丢弃法线和纹理坐标等不需要的信息后,成为像素。
光栅化阶段在 GPU 上执行。
光栅化就是在屏幕空间离散的像素中心点上进行采样来判断像素是否在三角形内的过程。
光栅化阶段的目标是找到处于图元 (三角形) 内部的所有像素,进而将 2D 坐标顶点转为屏幕上的像素,每个像素附带深度和其他着色信息,它们一并传入 pixel。它需要对上一个阶段得到的逐顶点数据 (例如纹理坐标 、顶点颜色等) 进行插值,然后再进行逐像素处理。
光栅化阶段分为两个子阶段:三角形设置 (Triangle Setup) 和**三角形遍历 (Triangle Traversal)**。
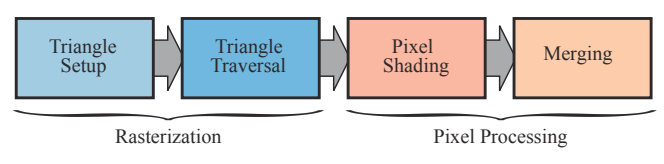
三角形设置阶段
计算三角形网格信息,例如三角形顶点坐标和边界表达式。
edge 函数用于确定一个像素中心或其他 sampler 是否在一个三角形内,硬件上会对每个三角形边缘应用一个 edge 函数,它基于直线方程。

GPU 会在三角形设置阶段计算三角形上的常数因子,以便三角形遍历阶段能够有效地进行 (edge 方程的 a, b, c 常量)。并且,还会计算与属性插值相关的常量。 总之,它就是处理前面阶段传递的数据,为三角形遍历阶段做准备。
三角形遍历阶段
[!NOTE] 关联
- 采样
- 透视校正插值(perspective-correct interpolation)也发生在该阶段
[!summary] 任务
检查像素是否在三角形内(采样),如果在的话就会生成一个**片元 (fragment)**。
判断方法有多种,由程序员决定。
找到哪些像素被三角网格覆盖的过程就是三角形遍历,这个阶段也被称为扫描变换 (Scan Conversion) 。
在三角形遍历阶段,片元的几何处理阶段传递的值会进行插值。GPU 采用重心坐标系来对值进行插值。重心坐标系的性质是,每个值的系数与三角形重心坐标顶点系数相同。因此,GPU 可以通过插值顶点的值来计算任意像素的值,并且这些值在三角形内部会进行插值计算。
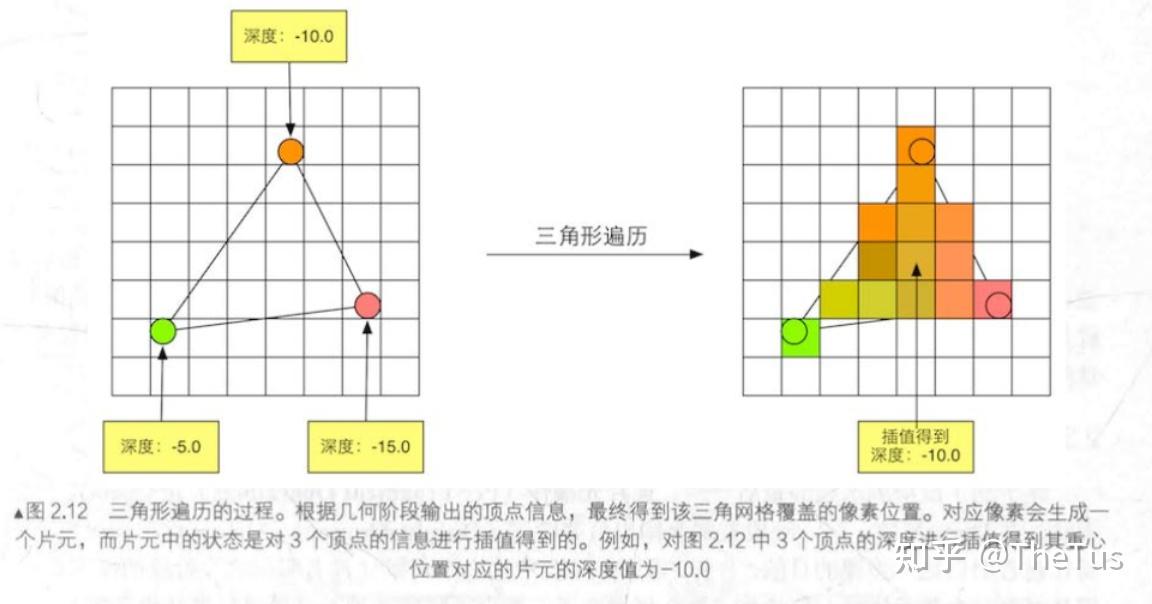
4 像素处理阶段(逐片元阶段)
[!summary] 任务
处理光栅化阶段发送过来的在图元内部的片元序列。GPU 会对每个片元进行像素操作,如颜色和深度的计算、纹理采样、混合等。最终,这些像素被组合成最终的图像(最终呈现在屏幕上的包含 RGBA 值的图像最小单元就是像素)
像素处理阶段在 GPU 上执行,它主要
像素处理阶段可以分为两个子阶段:像素着色阶段 (Pixel Shading) 和**合并阶段 (Merging)**。
像素着色阶段
[!NOTE] 关联
该阶段使用像素着色器(片元着色器)
[!summary] 任务
使用光栅化阶段传递的插值后的数据以及纹理计算像素颜色,将计算的颜色传递给合并阶段
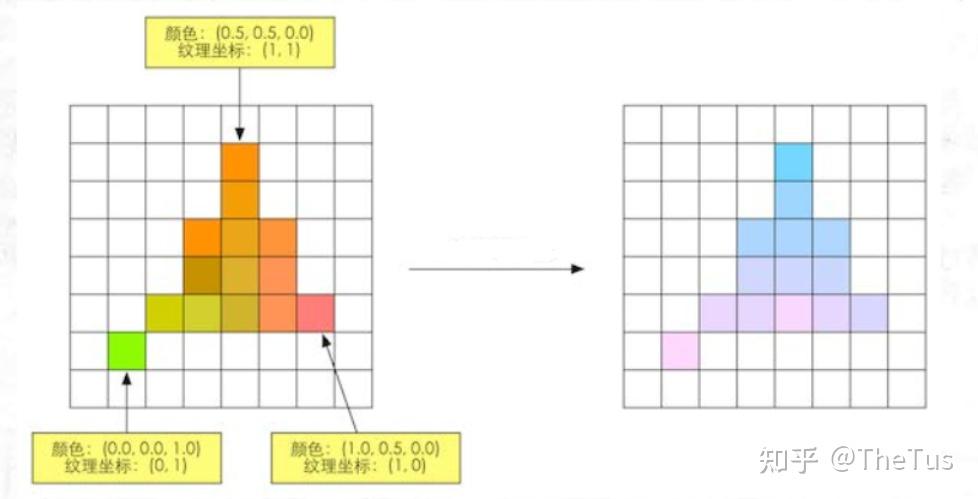
合并阶段
[!NOTE] 关联
该过程的测试是对片元操作的,合并完成后显示在屏幕上的才是像素:
深度测试
模板测试
混合
缓冲区
[!summary] 任务
将像素着色阶段产生的片元颜色与当前存储在缓冲区中的颜色进行组合
决定每个片元的可见性。这涉及了很多测试工作,例如深度测试、模板测试等。
[[3 进阶应用#3.1.1 StencilTest 模板测试]]
[[3 进阶应用#3.1.2 深度测试]]如果一个片元通过了所有的测试,就需要把这个片元的颜色值和已经存储在颜色缓冲区中的颜色进行合并,或者说是混合。
[[3 进阶应用#3.2 混合模式及剔除]]
合并阶段,又称 ROP 阶段,代表 “光栅操作管线”(raster operations pipeline)或 “渲染输出单元”(render output unit)。
与着色阶段不同,执行此阶段的 GPU 子单元通常不是完全可编程的。但是,它是高度可配置的,可实现各种效果。
通过一系列测试决定每个片元的可见性:
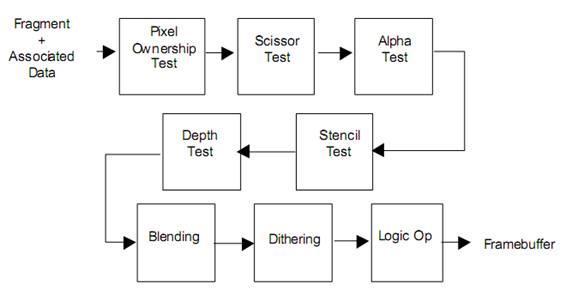
流程:
像素所有权测试→裁剪测试→透明度测试→模板测试→深度测试→透明度混合
PixelOwnershipTest(像素所有权测试):
简单来说就是控制当前屏幕像素的使用权限
举例:比如 unity 引擎中仅渲染 scene 和 game 窗口,即只对 scene 和 game 窗口部分的像素具有使用权限
ScissorTest(裁剪测试):
在渲染窗口再定义要渲染哪一部分,默认全部渲染,可以自己控制。
和裁剪空间一起理解,也就是只渲染能看到的部分
举例:只渲染窗口的左下角部分
AlphaTest(透明度测试)
提前设置一个透明度阈值
只能实现不透明效果和全透明效果
举例:设置透明度 a 为 0.5,如果片元大于这个值就通过测试,如果小于 0.5 就剔除掉
StencilTest(模板测试)
DepthTest(深度测试)
Blending(透明度混合)
可以实现半透明效果
完成接下来的其他一系列操作后,我们会将合格的片元/像素输出到帧缓冲区(FrameBuffer),最后渲染到屏幕上。
我们的屏幕显示的就是颜色缓冲区中的颜色值。但是,为了避免我们看到那些正在进行光栅化的图元,GPU 会使用双重缓冲 (Double Buffering) 的策略。这意味着,场景的渲染发生在后台缓冲区的屏幕外,即在后置缓冲 (Back Buffer) 中。一旦场景已经被渲染到了后置缓冲中, GPU 就会交换后置缓冲区和前置缓冲 (Front Buffer) 中的内容,而前置缓冲区是之前显示在屏幕上的图像。由此,保证了我们看到的图像总是连续的。
帧缓冲区(framebuffer)通常由系统上的所有缓冲区组成。
4 前向/延迟渲染路径
渲染路径
什么是渲染路径(Rendering Path)
- 决定光照的实现方式。(也就是当前渲染目标使用光照的流程)
渲染方式
首先看一下两者的直观的不同
前向/正向渲染 Forward Rendering
一句话概括:每个光照都计算
1 流程
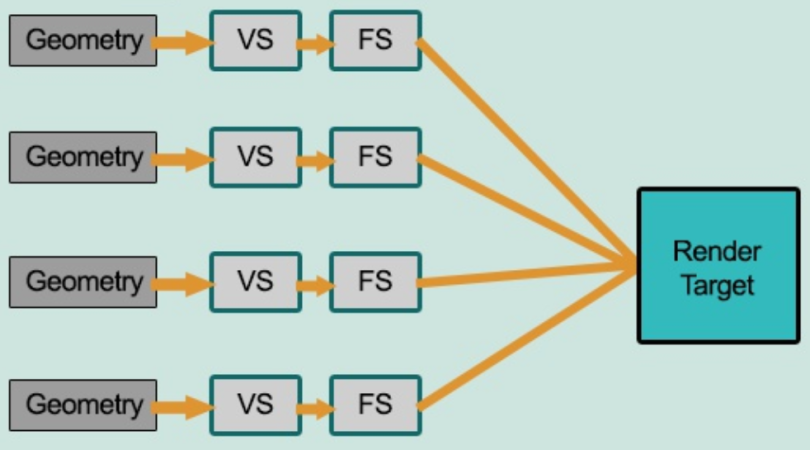
如图所示,流程为:
待渲染几何体 → 顶点着色器 → 片元着色器 → 渲染目标
在渲染每一帧的时,每一个顶点/片元都要执行一次片元着色器代码,这时需要将所有的光照信息传到片元着色器中。
虽然大部分情况下的光照都趋向于小型化,而且照亮区域也不大,但即便是离这个像素所对应的世界空间的位置很远的光源,光照计算还是会把所有的光源考虑进去的。
简单来说就是不管光源的影响大不大,计算的时候都会把所有光源计算进去,这样就会造成一个很大的浪费
2 规则(如何渲染每一帧的)和注意事项
Unity 引擎:
发生在顶点处理阶段,会计算所有顶点的光照。全平台支持
规则 1:最亮的几个光源会被实现为逐像素光照
规则 2:然后就是,最多四个光源会被实现逐顶点光照
规则 3:剩下的光源会实现为效率较高的球谐光照(Spherical Hamanic),这是一种模拟光照。SH 光照可以被非常快速地渲染,它只消耗很少的 CPU 性能,几乎不消耗 GPU 性能。并且增加 SH 灯光的数量不会影响性能的消耗。
一个灯光是逐像素光照还是其他方式渲染取决于以下几点:
(1)渲染模式(Render Mode)设置为 Not Important 的灯光总是以逐顶点或者 SH 的方式渲染。
(2)渲染模式(Render Mode)设置为 Important 的灯光总是逐像素渲染。
(3)最亮的平行光总是逐像素渲染。
(4)如果逐像素光照的灯光数量少于项目质量设置中 Pixel Light Count(最大像素光照数量),那么其余比较亮的灯光将会被逐像素渲染。
(5)最后剩下的光源,按照规则 2 或 3。
Render Mode 设置: 默认为 Auto,Unity 会根据灯光的亮度以及与物体的距离自动判断该灯光是否重要。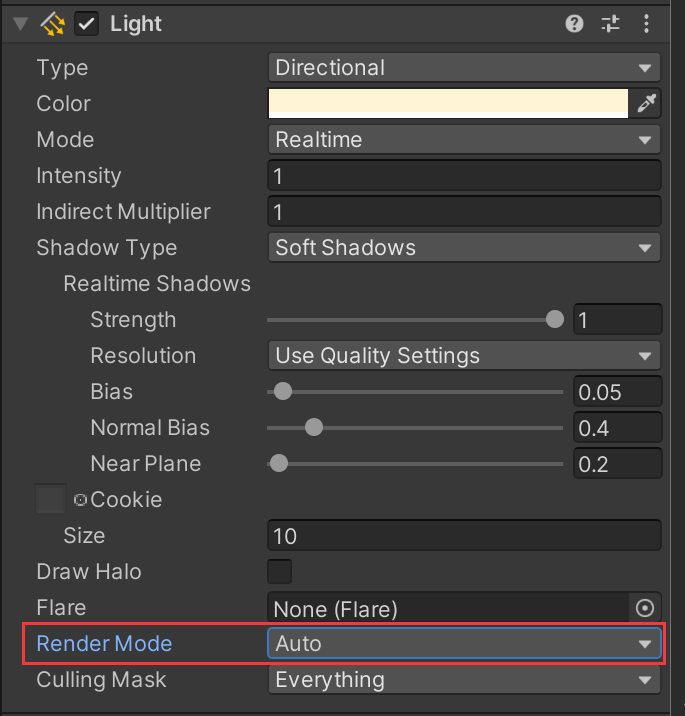
Pixel Light Count 设置: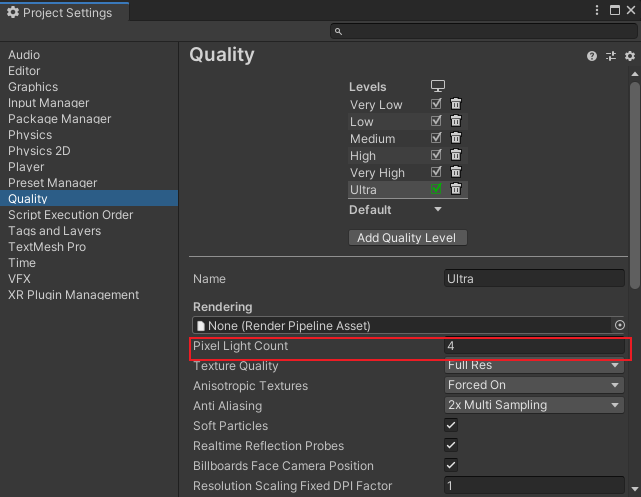
- 所以,如果一个物体受到 n 个光源影响,那么每个片元着色器执行代码时,都必须把 n 个光源传递给着色器中进行计算。

3 两种 Pass
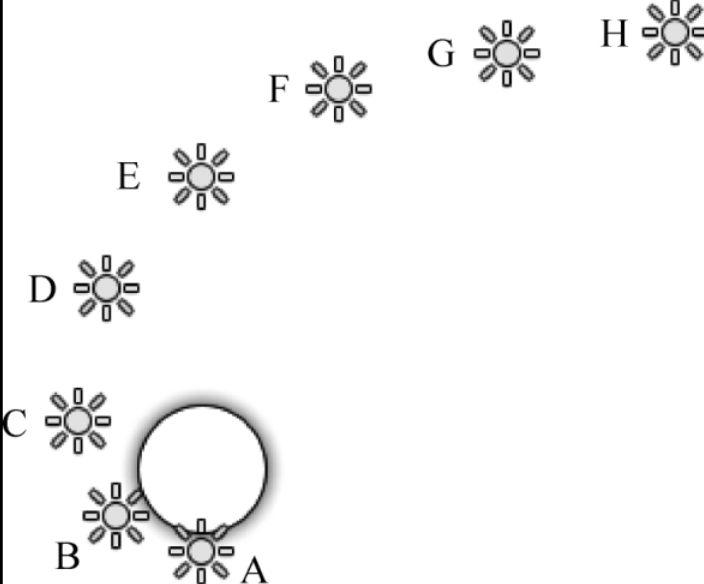
一个物体受到 A-H 共 8 个灯光照射,假设所有灯光有相同颜色和强度,并且它们的渲染模式为自动。
最终这 8 个灯光的渲染模式如图所示,由于 A-D 这 4 个灯光距离物体更近,因此亮度更亮,会逐像素渲染,然后最多 4 个灯光(D-G)逐顶点渲染,最后剩余的灯光(G-H)以 SH 渲染。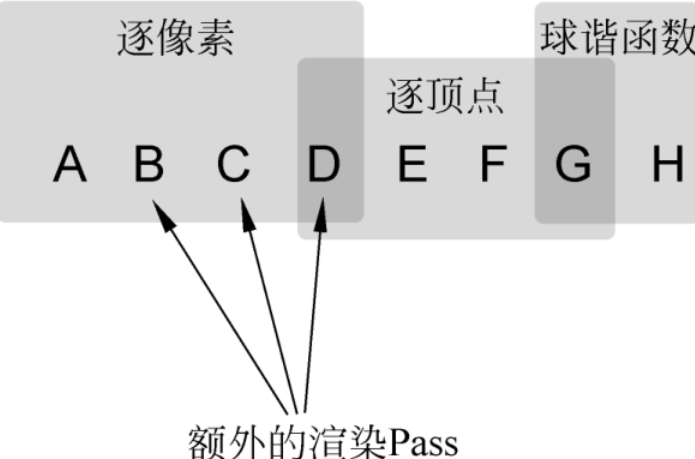
灯光 D 既是逐像素照明又是逐顶点照明,灯光 G 既是逐顶点照明又是 SH 照明,这是因为当物体或者灯光移动的时候,不同渲染模式的灯光交界处会出现明显的缺陷,为了避免这个问题,Unity 将不同的灯光组之间进行了重叠。
前向渲染有两种 Pass:Base Pass 和 Additional Pass

- Base Pass 中的渲染计算包含一个逐像素的平行光和所有逐顶点或 SH 的灯光,并且也会包含所有来自于 Shader 的光照贴图、环境光和自发光。BasePass 中的平行光默认支持投射阴影,
- 其他逐像素的灯光会在额外的 Additional Pass 中渲染,每一个灯光会产生一个额外的 Pass。在 Additional Pass 中的光源默认没有阴影效果,可以使用
multi_compile_fwdadd_fullshadows编译指令代替multi_compile_fwdadd编译指令,为点光源和聚光灯开启阴影效果。 - Additional Pass 中还要开启混合模式,因为我们希望每个 Additoinal Pass 可以和上次一的光照结果在帧缓存冲进行叠加,从而得到最终的有多个光照的渲染结果。如果没有开启和设置混合模式 Blend One One 或其他,那么 Additional Pass 的渲染结果会覆盖掉之前的渲染结果,看起来好像该物体之受该光源的影响。
- 对于前向渲染来说,一个 Unity Shader 通常会定义一个 Base Pass (Base Pass 也可以定义多次,例如需要双面渲染等情况)以及一个 Additional Pass。一个 Base Pass 仅会执行一次 (定义了多个 Base Pass 的情况除外),而一个 Additional Pass 会根据影响该物体的其他逐像素光源的数目被多次调用,即每个逐像素光源会执行一次 Additional Pass。
延迟渲染 Deferred Rendering
一句话概括:先不计算光照,延迟到最后再一起计算
1、什么是延迟渲染
- 主要用来解决大量光照渲染的方案
- 延迟渲染的实质是:
- 先不要做迭代三角形做光照计算,而是先找出来你能看到的所有像素,再去迭代光照。
- 直接迭代三角形的话,由于大量三角形是看不到的,会造成极大的浪费。
2、流程
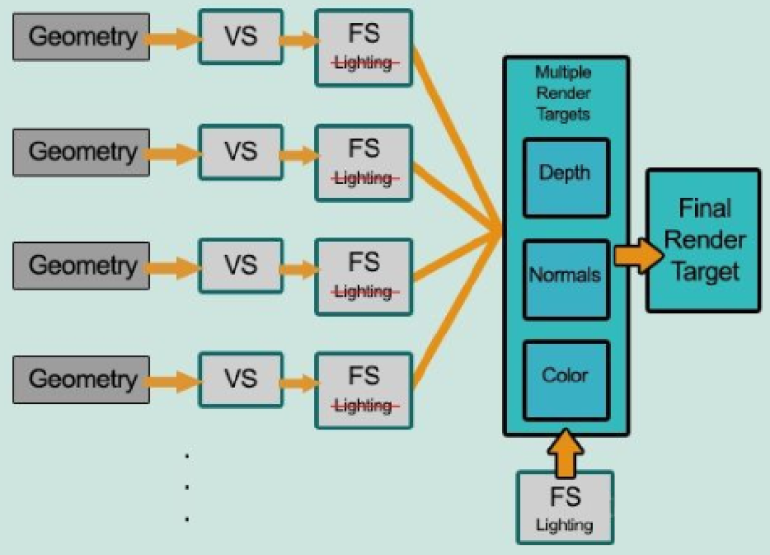 - 流程为:待渲染几何体 → 顶点着色器 → 片元着色器(写入颜色,但不进行光照计算)→ MRT 多重渲染目标 → 光照计算(全部执行逐像素渲染) → 渲染目标
- 流程为:待渲染几何体 → 顶点着色器 → 片元着色器(写入颜色,但不进行光照计算)→ MRT 多重渲染目标 → 光照计算(全部执行逐像素渲染) → 渲染目标
过程可以拆分为两个 pass:
- 第一个 pass:几何处理通路。
- 首先将场景渲染一次,获取到的待渲染对象的各种几何信息存储到名为 G-buffer 的缓冲区中,这些缓冲区用来之后进行更复杂的光照计算。
- 由于有深度测试,所以最终写入 G-buffer 中的,都是离摄像机最近的片元的集合属性,这就意味着,在 G-buffer 中的片元必定要进行光照计算。
- 第二个 pass:光照处理通路。
- 这个 pass 会遍历所有 G-buffer 中的位置、颜色、法线等参数,执行一次光照计算。
3、一些注意事项
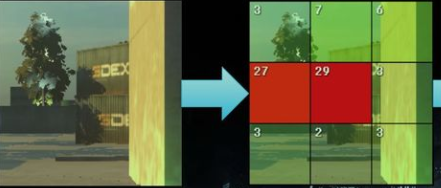
G-buffer 的概念
G-Buffer,全称 Geometric Buffer ,译作几何缓冲区,它主要用于存储每个像素对应的位置(Position),法线(Normal),漫反射颜色(Diffuse Color)以及其他有用材质参数。
根据这些信息,就可以在像空间(二维空间)中对每个像素进行光照处理。
如图为一个典型的 G-buffer

UE4 默认使用的是延迟管线
我们在视图模式—缓冲显示—总览,就可以看到所有 G-buffer 的预览

延迟渲染不支持透明物体的渲染,因为没有深度信息,所以渲染透明物体时引擎会自动使用前向渲染处理
延迟着色不支持正交投影,当摄像机使用正交投影模式的时候,摄像机会自动使用前向渲染。
[!NOTE] MRT 现在已经支持 MSAA 抗锯齿!
DX10.1 支持了带 MSAA 的 MRT,很多老文章说延迟渲染不支持抗锯齿是因为十几年前 DX9 时代的 MRT 不支持 MSAA伪代码

RT(G-buffer)相当于把整个屏幕的信息绘制到一个图中,每个 RT 都可以写到一个 G-buffer 中
G-buffer 中的数据都是 2D 的,所以我们的光照计算就相当于一个2D 的光照后处理
不同渲染路径的特性
1、后处理方式不同
- 如果需要深度信息进行后处理的话
- 前向渲染需要单独渲染出一张深度图
- 延迟渲染直接用 G-buffer 中的深度图计算
2、着色计算不同(shader)
延迟渲染因为是最后统一计算光照的,所以只能算一个光照模型(如果需要其他光照模型,只能切换 pass)
不同渲染路径的优劣
前向渲染的优点、缺点
优点
- 支持半透明渲染
- 支持使用多个光照 pass
- 支持自定义光照计算方式
(延迟渲染是渲染到 Gbuffer,再一起计算光照,所以不支持每一个物体用单独的光照方式计算)
缺点
- 光源数量对计算复杂度影响巨大
- 访问深度等数据需要额外计算(需要再渲染一张深度图)
延迟渲染的优点、缺点
优点
- 大量光照场景的情况下,优势明显
- 只渲染可见像素,节省计算量
- 对后处理支持良好(例如深度信息:直接拿 G-buffer 中的就行)
- 用更少的 shader(所有的物体光照模型都一样,很多东西不用再定义了)
缺点
- 对 MSAA 支持不友好
- 透明物体渲染存在问题(深度问题,只渲染力物体最近的物体,渲染透明度时会出现问题)
- 占用大量的显存带宽,所以移动端用得较少(原神是延迟渲染)
涉及一个 clear 的操作,如果不清理的话,后边可以继续获取到
每一帧都需要几张 rt 在显存中传输、清理等,会更耗带宽
- 只能使用同一个光照 pass
其他部分
2 TBDR(分块延迟渲染)
针对移动端的优化
有两个 TBDR,名字一样,内容不同
第一个:
是 SIGGRAPH2010 提出的,作为传统 Defferred Rendering 的另一种主要改进,分块延迟渲染(Tile-Based Deferred Rendering,TBDR)旨在合理分摊开销(amortize overhead),自 SIGGRAPH 2010 上提出以来逐渐为业界所了解。基于延迟渲染的优化方式,通过分块来降低带宽内存用量(解决带宽和内存问题)
延迟渲染的分块,把整个图像分为很多块,再一块一块的渲染第二个:
PowerVR 基于手机 GPU 的 TBR 框架提出的改进,通过 HSR 减少 Overdraw
TBDR 这个架构是 PowerVR 提出来的对 TBR 的一次改进,在 TBR 的基础上再加了一个 Deferred。
通过做一些可见性测试来减少 Overdraw
涉及手机 GPU 架构,和延迟渲染没什么关系
[[3 进阶应用#3.7 现代移动端的TBR和TBDR渲染管线]]
3 其他渲染路径
延迟光照(Light Pre-Pass / Deferred Lighting)
- 减少 G-buffer 占用的过多开销,支持多种光照模型
- 和延迟渲染的区别:
- 用更少的 buffer 信息,着色计算的时候用的是 forward,所以第三步开始都是前向渲染(可以对不同的物体进行不同的光照模型)
Forward+(即 Tiled Forward Rendering,分块正向渲染)
- 减少带宽,支持多光源,强制需要一个 preZ
- 通过分块索引的方式,以及深度和法线信息来到需要进行光照计算的片元进行光照计算。
- 需要法线和深度的后处理需要单独渲染一个 rt 出来
- 强制使用了一个 preZ(如果没涉及过这个概念的话,可以理解为进行了一个深度预计算 Pass)
群组渲染(Clustered Rendering)
- 带宽相对减少,多光源下效率提升
- 分为 forward 和 deferred 两种
- 详细补充拓展:https://zhuanlan.zhihu.com/p/54694743
compute shader
[!NOTE]
Direct3D 中计算着色器不属于渲染管线,但可以读写 GPU 资源。从本质上来说,计算着色器能够是我们访问 GPU 来实现数据并行算法,而不必渲染出任何图形(比如 FFT 海洋利用 compute shader 计算出法线贴图等波形数据,但不负责水体的渲染部分)
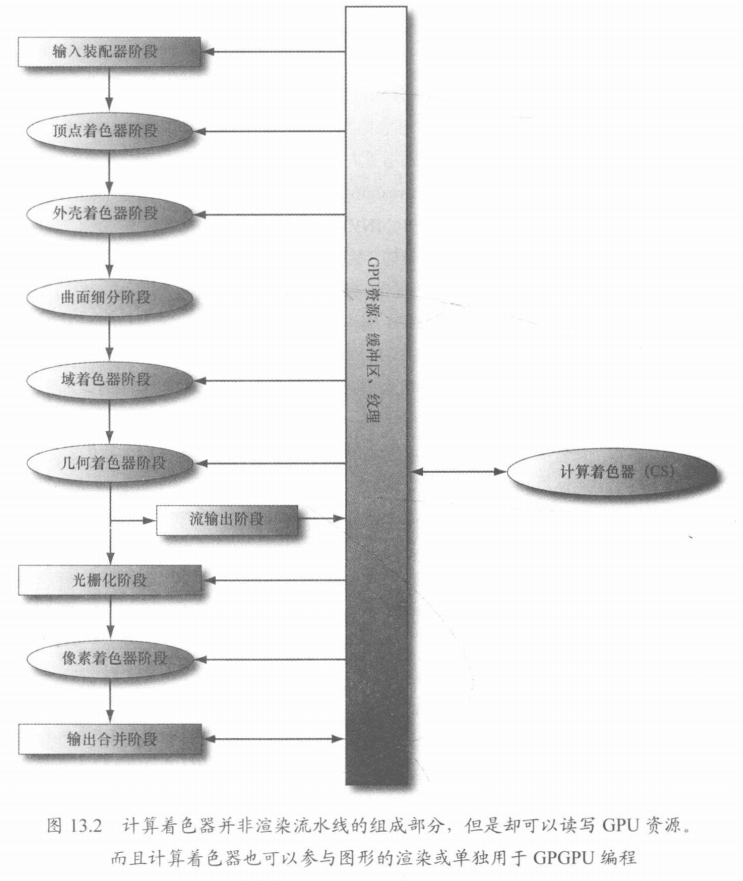
当代 GPU 被设计成可以执行大规模的并行操作,这有益于图形应用,因为在渲染管线中,不论是顶点着色器还是像素着色器,它们都可以独立进行。然而对于一些非图形应用也可以受益于 GPU 并行架构所提供的大量计算能力。比如说我们有个应用可以把两个 excel 里的 N 个值相加,如果 N 很大,那么是不是可以利用 GPU 来进行这些相加计算,来提升速度。像这样的非图形应用使用 GPU 的情况,我们称之为 GPGPU(General Purpose GPU ,通用 GPU)编程。
对于 GPGPU 编程而言,用户通常需要将 GPU 计算后的结果返回到 CPU 供其访问。例如前面的例子中,我们要在 CPU 中读取到 GPU 计算后值,以便可以将结果写入到新的 excel 中。这就涉及到将数据从 GPU 显存(VRAM)中拷贝到 CPU 系统内存(RAM)中的操作,该操作非常的慢。但是相比使用 GPU 来计算所提升的运行速度而言,可以忽略此问题。下图展示了 CPU 和 RAM、GPU 和 VRAM、CPU 和 GPU 之间的相对内存带宽速度(图中的数字只是说明性的数字,以显示带宽之间的数量级差异),可以发现瓶颈在于 CPU 和 GPU 之间的内存传输。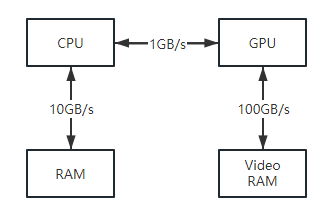
针对图形处理任务来说,我们一般将运算结果作为渲染流水线的输入,所以无需再由 GPU 向向 CPU 输入。例如我们要实现一个模糊效果,可以先用 CS 模糊一个 Texture,然后模糊后的 Texture 可以直接作为 Fragment Shader 的输入。
某些应用程序阶段的工作可以由 GPU 执行,使用一种被称为计算着色器(compute shader)的单独模式。此模式会将 GPU 视为高度并行的通用处理器,而忽略它专门用于渲染图形的特殊功能。
 微信
微信 支付宝
支付宝









