
全局光照GI
全局光照是增强真实感的重要部分, 因此也是十分复杂的一部分.
从下图中我们会发现, 没有任何一处是全黑的看不见东西的, 比如书本的下方, 蜡烛内部等. 也就是光线 bounce 了很多次才到达我们的眼里, 在 GAMES101 中我们在布林冯模型中, 假设 ambient 项, 认为来自四面八方的间接光照都是相同的, 且最后的 shading 和 normal 是无关的, 这样得到的结果是十分不真实的。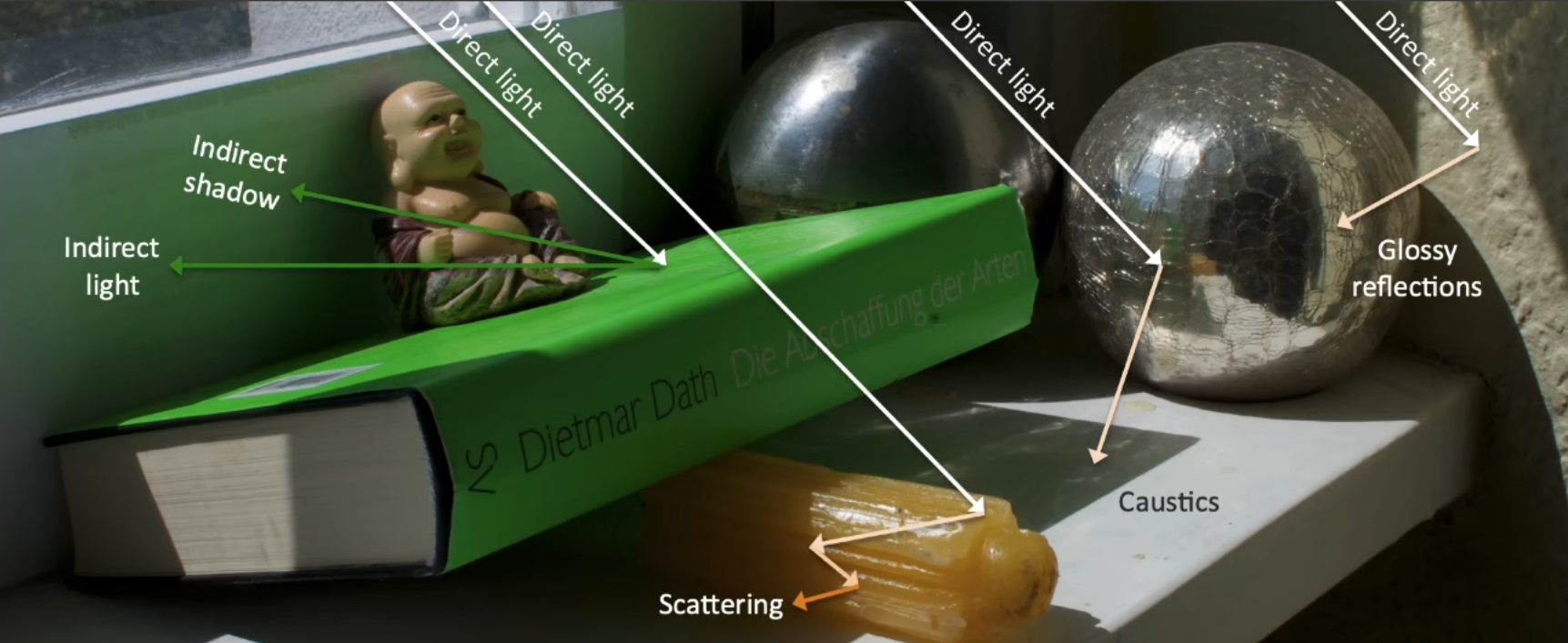
图中的全局光照就不能这么假设了, 大家可以看到书本下方各位置的亮度不同, 还可以看到一些焦散等从金属球反射出的间接光, 他们之间是不一样的, 如果还做 Ambient 项项那种假设从而只提升了一点亮度是无法得到图中的结果的.
在实时渲染中, 全局光照是比直接光照多一次光线弹射的间接光照

如图中, 光线弹射两次, 先打到红色的墙壁上, 在达到 box 面上, 最后被 camera/eye 看到, 这就是在 rtr 中要解决的所谓的 “全局光照”.
我们希望他:
①简单 -> 实现起来不麻烦
②快速 -> 因为全局光照非常难算
实时 GI(图像空间)
为什么说是图像空间:因为很多信息从图像中获得,比如从 shadowmap 中获取信息
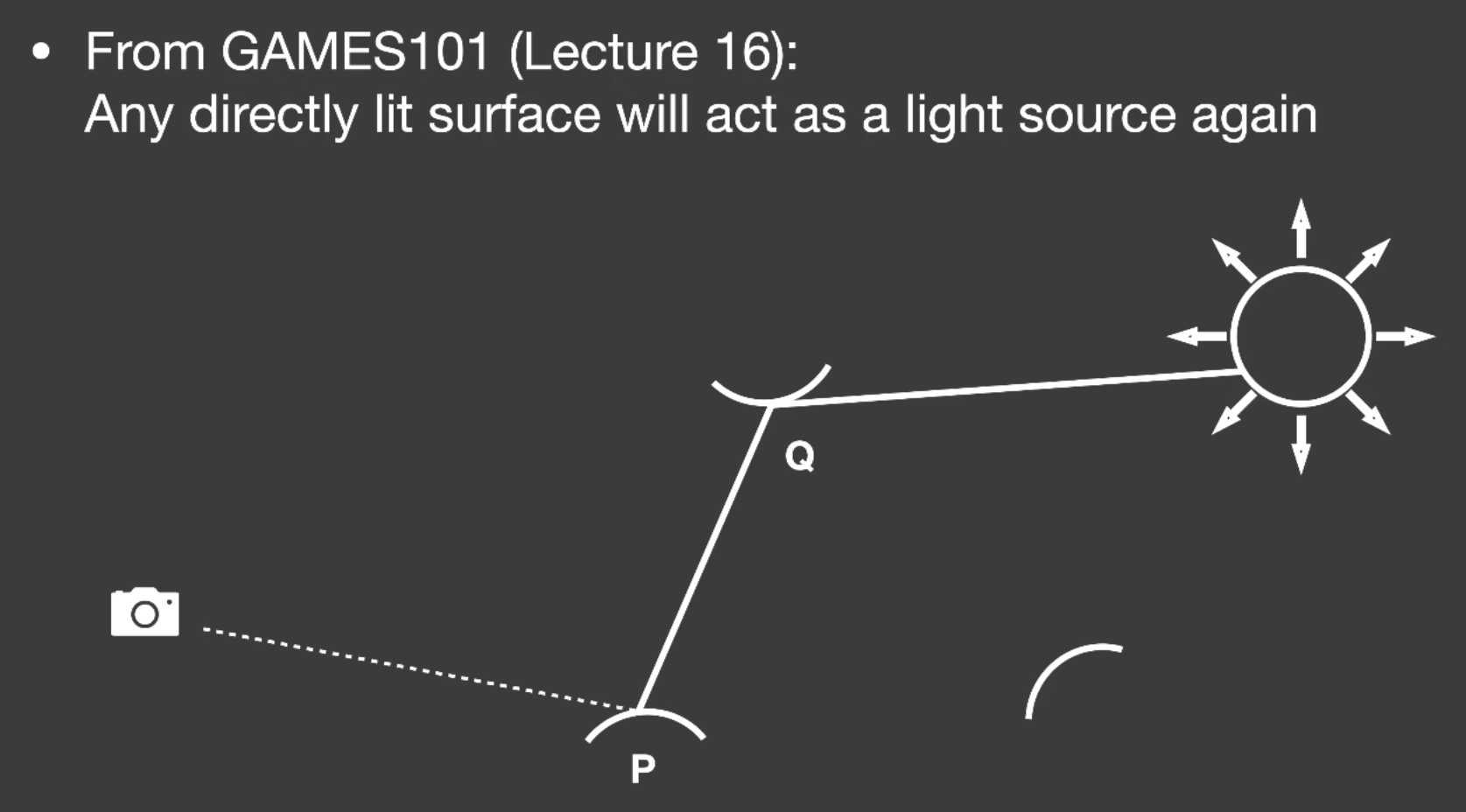
前面提到过,在 path tracing 时, 从 camera 出发打出一条光线到点 P, P 点又往场景中不同的方向发射光线, 如果打到光源则表示接受的是直接光照.
如果没打到光源而是打到了点 Q, 那么我们认为 P 点接收到的光照是从 $Q$ 点反射到 P 点的 Radiance, 也就是 Q 点接收到的直接光照所反射出的光照打到 P 点上.
点 $Q$ 接受的是直接光照, 我们则认为接收到直接光照的表面可以被当作虚拟点光源 (Secondary Light Sourse) 用自身反射的光照来照亮其他物体.
总之把 $Q$ 当成光源(虚拟点光源)

我们可以看到 $P$ 点在柱子后面, 不可能接收到直接光照, 我们稀疏的标示出虚拟点光源。将所有照射到 $P$ 点的虚拟点光源加起来,就是 $P$ 点的着色结果。
RSM 反射阴影贴图
Reflective Shadow Map
Monica 的小甜甜:【论文复现】Reflective Shadow Maps
本质就是 shadowmap,不过是多存了一些信息,注意它不是用来解决阴影问题的,而是用来解决间接光照问题的:shadowmap 中存的像素就是场景中可以被照亮的像素,而这些被照亮的物体也可以作为光源发出间接光照照亮其他物体。
[!NOTE] RSM 数据存储
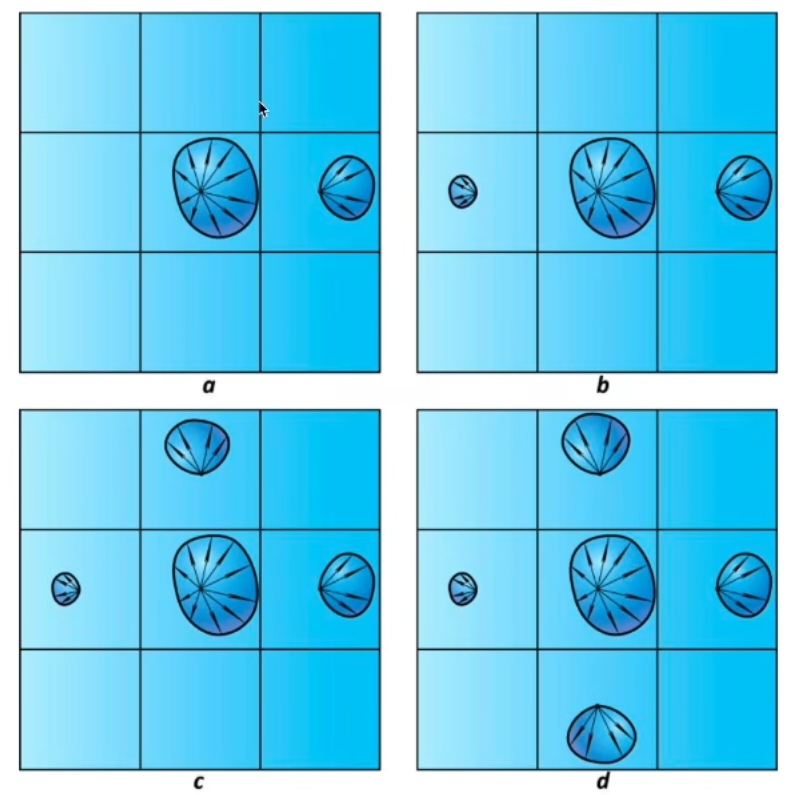
RSM 在每一个像素 $p$ 中都需要存储深度值 $d_p$,世界坐标 $x_p$,法线 $n_p$,反射光功率 $\phi _p$,如下图的可视化效果,四个 map 对应像素 p 的四个参数.

虚拟点光源
RSM 的核心思想是把直接光源照亮的区域又作为发光物(虚拟点光源)来进行计算。
第一步:先单独计算直接光照对环境的影响。
第二步:要获得直接光照亮的区域,那么该如何获得这块区域呢?其实有个很简单的办法,从光源的视角进行一次渲染就可以得到从光源视角看的区域,本质是一个 shadowmap(渲染之后我们保存位置信息,法线信息和颜色信息到纹理中)。
第三步:用第二步保存的信息用于计算间接光照,RSM 的核心就是把这个发光区域的每一个像素都看成一个光源叫做虚拟点光源(Virtual point light:VPL),然后用这所有的虚拟点光源来计算间接光照
第四步:将间接光照和直接光照融合起来(直接相加即可)。
? 那么为了计算点 $P$ 的 shading 需要知道什么?
- 哪些表面位置会被直接照到?=>使用 shadowmap
- 如何计算每个虚拟点光源对着色点 $P$ 的贡献?=>渲染方程
问题 1
Reflective Shadow Map (RSM)假设: 所有的反射物 (虚拟点光源) 都是 diffuse 的,但不要求点 $P$ 是 diffuse
虚拟点光源如果想照亮点 $P$, 观察方向是从 $P$ 点去观察虚拟点光源的, 也就是对于不同的 P 点来说出射方向是未知的, 因此是无法计算 $P$ 点的 shading 的, 为了不依赖于观察方向, 在 RSM 中我们假设,所有被当作虚拟点光源的反射物都是 diffuse,不要求点 $P$ 是 diffuse,故点 P 的反射方向仍是未知的。这样不管从 camera 看过去还是从点 $P$ 看过去所得到的结果是一样的。
如何判断虚拟点光源能否看到着色点?
渲染方程中的 V 是指虚拟点光源到着色点是否可见,如果想解决这个问题,需要为每个虚拟点光源算一次 shadow map,这个运算无法算。RSM 中忽略虚拟点光源到着色点的可见性判断,认为都是可见的
问题 2
考虑所有虚拟点光源的贡献,进行求和;并且每个虚拟点光源可以看成是一个面光源。
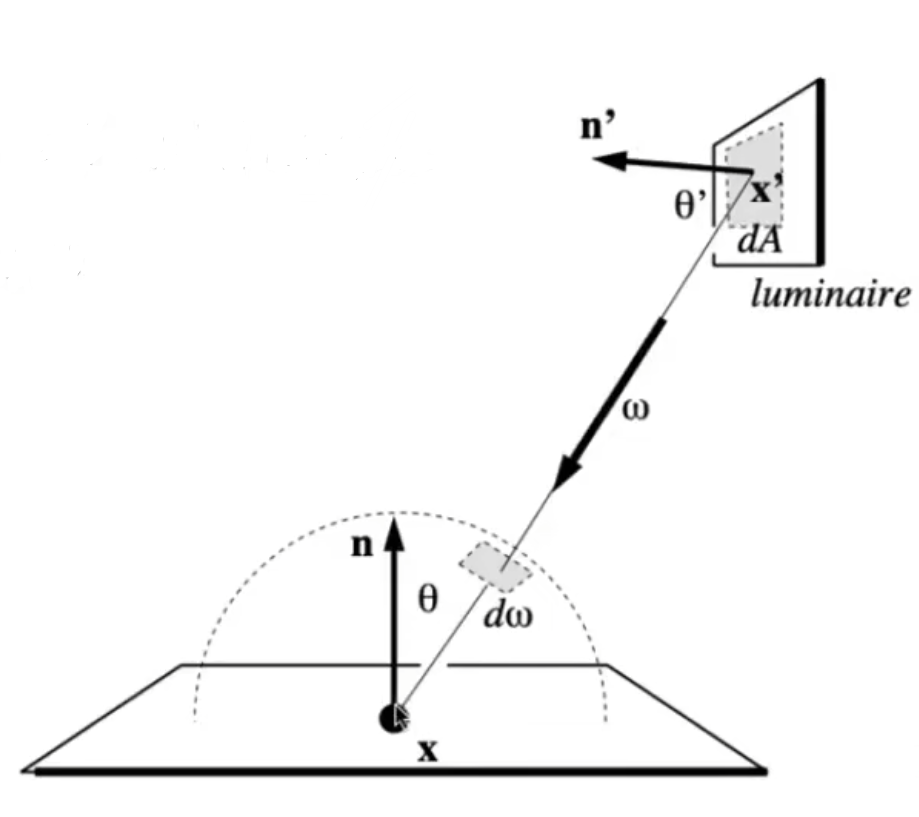
学习路径追踪时提到了一个方法 [[04 路径追踪#提高效率->直接采样光源]],在着色点采样寻找光源效率太低了,我们可以直接采样光源!直接计算光源对着色点的贡献,需要将 $d\omega$ 换成换成 $dA$,渲染方程转换如下:
$$
\begin{aligned}
L_o(\text{p},\omega_o)& =\int_{\Omega_\mathrm{patch}}L_i(\mathrm{p},\omega_i)V(\mathrm{p},\omega_i)f_r(\mathrm{p},\omega_i,\omega_o)\cos\theta_i\mathrm{d}\omega_i \
&=\int_{A_\text{patch}} L _ i ( {q}\to{p})V({p},\omega_i)f_r({p},{q}\to{p},\omega_o)\frac{\cos\theta_p\cos\theta_q}{|q-{p}|^2}\mathrm{d}A
\end{aligned}
$$
对于每个虚拟点光源点来说, 由于我们假设它的 brdf 是 diffuse 的, 因此:
- $f_{r}=\rho/\pi$
- $\displaystyle L_i=f_r\cdot\frac{\Phi}{dA}$($\Phi$ 为入射的辐射通量)
$E_p$ 表示虚拟点光源对着色点贡献的入射辐照度:
$$
E_{p}(x,n)=\Phi_{p}\frac{\max{0,\left<n_{p}|x-x_{p}\right>}\max{0,\left<n|x_{p}-x\right>}}{||x-x_{p}||^{4\textbf{ ->2}}}.\quad(1)
$$
求出了一个虚拟点光源 $p$ 对着色点所得到的 shading 结果, 再将积分域中所有的结果加在一起, 就是着色点最后被间接光照照亮所得到的 shading 值.
- 值得注意的是原文公式中的分母是 4 次方,闫老师认为是作者考虑了虚拟点光源发射的光线有衰减,这里应该是 2 次形式。(他们后来说闫老师吃键盘了, 我毕竟还没看到后面所以我先留着.) 更新: 闫老师确实吃键盘了, 但是老师没有错, paper 也没有错, 因为在分子中有两个 Xp-X,当把这两个放到分母中后,结果与我们推导的结果一致,同为 2 次方。
shadowmap 像素的贡献

由于可见性、方向性以及距离的不同,对于某一个着色点,认为 shadow map 上并不是所有的 pixel 都有贡献:
- 可见性测试项(仍然非常难算);
- 方向:比如 $X_{-1}$ 点在 shadowmap 中记录的是桌子的表面,而且这个表面的点法线方向是朝上的,因此根本不可能照亮 X 点;
- 距离:因为远处的虚拟点光源贡献很少,通常只要找距离足够近的虚拟点光源就行了。
- 为了加速这一过程, 我们认为在 shadow map 中着色点 $x$ 的位置和间接光源 $x_p$ 的距离可以近似为它们在世界空间中的距离。所以我们认为,对着色点 $x$ 影响大的间接光源在 shadow map 中一定也是接近的。
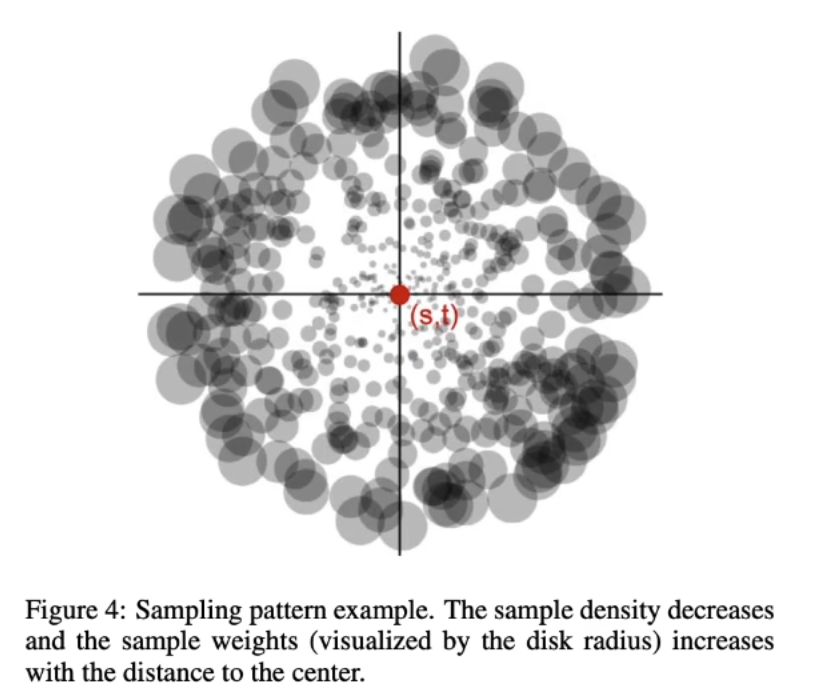
- 于是我们决定先获取着色点 $x$ 在 shadow map 中的投影位置 $(s,t)$,在该位置附近采样间接光源,多选取一点离着色点近的 VPL,并且为了弥补越往外采样数越少可能会带来的问题,引入了权重,越近了权重越小,越远的权重越大。那么对于一个 shading point 差不多找 400 个虚拟点光源来计算是比较合适的。
- 为了加速这一过程, 我们认为在 shadow map 中着色点 $x$ 的位置和间接光源 $x_p$ 的距离可以近似为它们在世界空间中的距离。所以我们认为,对着色点 $x$ 影响大的间接光源在 shadow map 中一定也是接近的。
应用:手电筒
RSM 效果通常应用于游戏中手电筒的次级光照,如图:

在此可以更加理解我上文写的对于式子的理解
屋顶某个点亮了的区域就是手电筒直接照亮区域对屋顶那个点的贡献, 屋顶点积分的时候积分域就是手电筒直接照亮的位置.
优点:
- 易于实现
缺点:
- 性能随着直接光源数的增加而降低 (因为需要计算更多的 shadow map)
- 对于间接光照,没有做可见性检查
- 有许多假设:反射物需要是 diffuse 等
- 需要在质量和采样率上做一个平衡
(鸽)实时 GI (世界空间)
LPV 光传播体积
光传播体积:Light Propagation Volumes
在 3D 空间中去传播光线, 从而利用它做出间接光照从而实现 GI.
LPV 快速且高质量
- 主要问题:
- 如果我们能获得任何一个 Shading point 上来自四周的 radiance 的话, 就可以立刻得到其间接光照
- 核心思路:
- 光在传播过程中, 辐射率 radiance 是不变的(辐照度是按距离平方衰减的)
- 核心解法:
- 将场景划分为若干个 3D 网格, 每个网格叫做 Voxel (体素), 在计算完直接光照后, 将接受到直接光照的表面看作间接光照在场景中传播的起点.
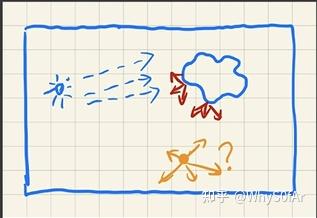
步骤
步骤:
- 找出接收直接光照的点
- 把这些点注入 (inject) 到 3D 网格中作为间接光照 (虚拟光源) 的传播起点.
- 在 3D 网格中传播 radiance
- 传播完后, 渲染场景
具体步骤:
- 生成
- 这是为了找到直接被照亮的表面
- 与 RSM 一样, 首先通过 Shadow Map 找出接受直接光照的表面或物体
- 对得到的光源数量可以通过采样一些进行简化从而降低次级光源数量, 最后获得一系列虚拟光源

- 注入
- 预先把场景划分为若干个 3D 网格 (体素),工业界使用 3D 纹理
- 把虚拟光源注入到其对应的格子内
- 一个格子内可能包含许多不同朝向的虚拟光源, 把格子内所有虚拟光源的不同朝向的辐射率算出来相加
- 由于是在空间上的分布, 也就可以看作是球面函数, 自然可以用 SH 来表示 (工业界用两阶 SH 就可以表示各个方向上的辐射率初始值)
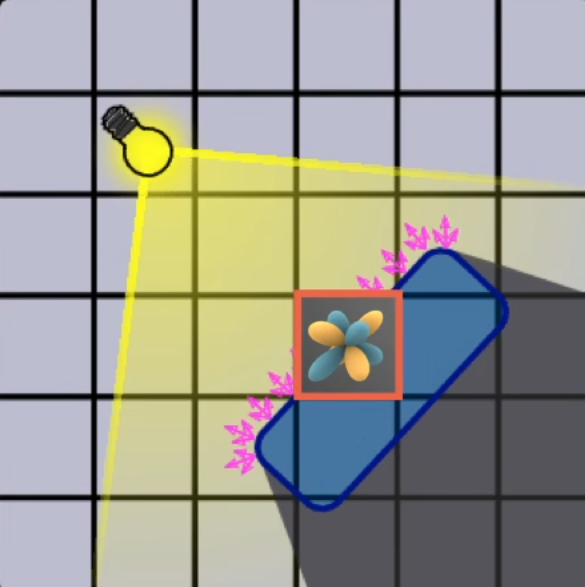
- 传播
- 由于是 3D 网格, 因此可以向六个面进行传播 (上下左右前后), 由于 radiance 是沿直线传播的, 我们认为 radiance 是从网格中心往不同方向进行传播的, 穿过哪个表面就往哪个方向传播, 比如穿过右表面的 radiance, 就传播到右边的格子里 (不考虑斜角, 比如右上方向, 我们认为是先到右边格子, 再到上面格子)
- 每个格子计算收到的 radiance, 并用 SH 表示
- 迭代四五次之后, 场景中各 voxel 的 radiance 趋于稳定
- 渲染
- 对于任意的 shading point,找到他所在的网格
- 获得所在网格中所有方向的 Radicae;
- 渲染。
问题
LPV 也有自己的问题, 那就是和 VSSM 一样的问题: 漏光(Light Leaking)
由于我们认为 radiance 是从格子正中心向四周发散的, 当遇到这种情况时,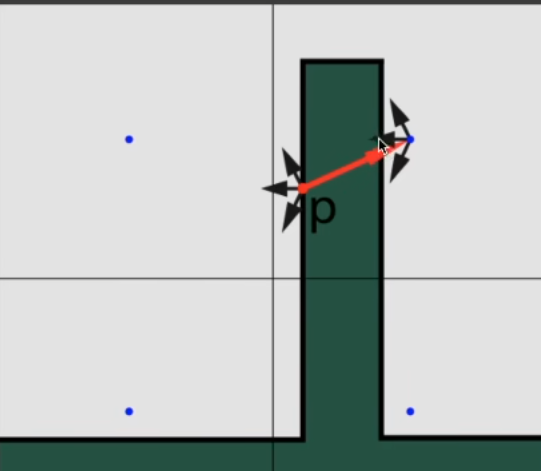
按理说点 P 反射的 radiance 是无法照亮墙壁的背后, 但是由于我们的假设, 会导致墙壁后面也被间接光照照亮, 也就是所谓的漏光现象.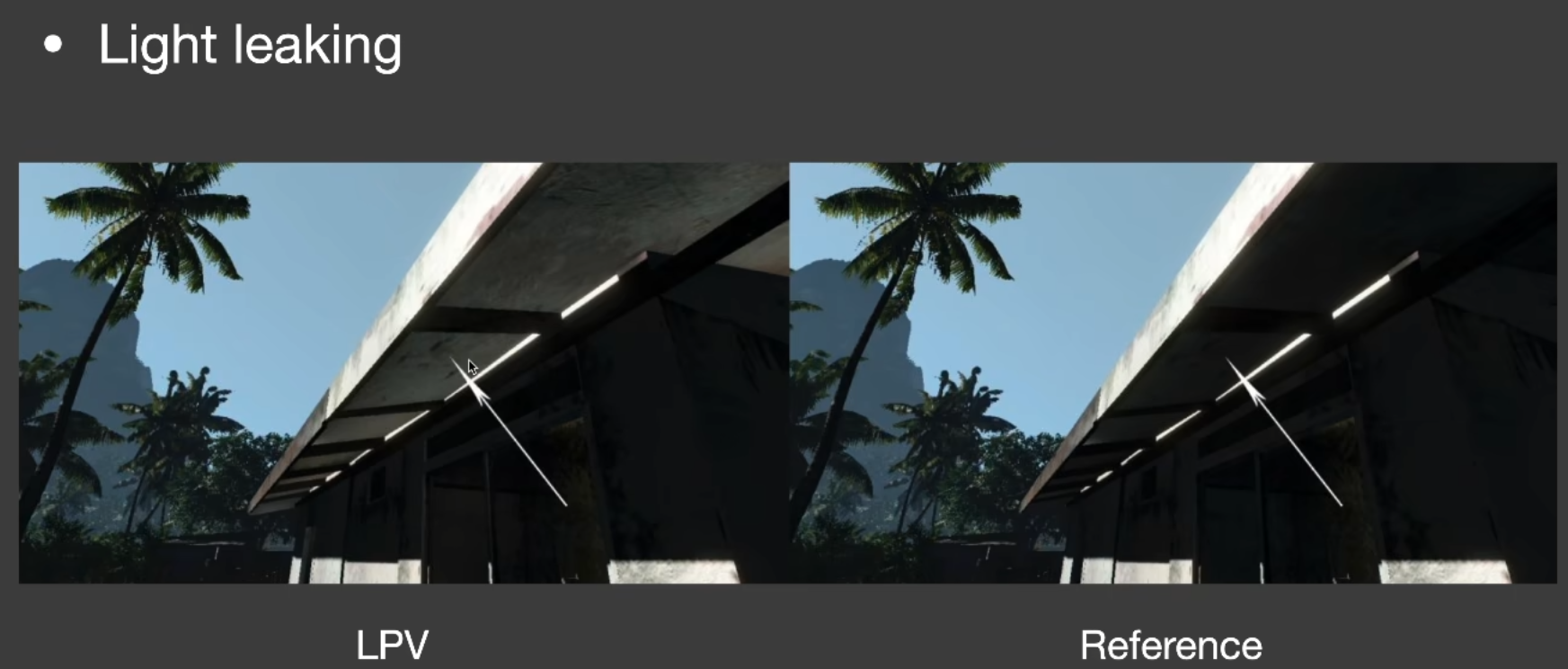
如图, 你看房屋的下部本不应该被照亮, 但由于使用了 LPV 导致了 light leaking 现象.
解决漏光现象:划分的格子足够小
但是这样会导致存储量增多, 而且传播过程中传播的格子量增多, 也就导致了速度慢。
对于两个格子之间的可见性也进行了假设,假设相邻格子都能看见,同时工业界会用不同大小的格子也就是 Cascade 层级加速结构,来优化 LPV 的方法。
VXGI 体素全局光照(待续)
体素全局光照:Voxel Global Illumination
VXGI 也是一个 2-pass 的算法, 但是与 RSM 有一些区别:
区别 1: 次级光源从 RSM 中的 Pixel 变成了 Voxel (体素)
RSM 中次级光源是像素中所包含的微小表面,这些表面是根据 Shadow Map 来划分的.
**VXGI 把场景完全离散化成了一系列微小的格子 (即体素Voxel)**,可以理解为场景是由一堆乐高堆起来的, 如图, 这些是最细的层级, 也就是最小的格子我们可以在这一层基础上去建立一层大点的格子, 依此类推从而根据场景的不同划分建立出一个 Hierachical 树形结构的体素。
区别 2: 光线从传播变为了追踪
在 LPV 中, 我们将受到直接光照的点注入到场景划分的 Voxel 之后进行传播, 只需要传播一次就可以知道场景中任何一个 shading point 收到间接光照的 radiance.
而在 VXGI 中第二趟我们从 camera 出发, 就像有一个 Camera Ray 打到每一个 pixel 上, 根据 pixel 上代表的物体材质做出不同的操作, 如果是 glossy 则打出一个锥形区域, diffuse 则打出若干个锥形区域, 打出的锥形区域与场景中一些已经存在的 voxel 相交, 这些 voxel 对于 Shading point 的贡献可以算出来, 也就是我们要对每一个 shading point 都做一个 cone tracing, 可想而知, 这个速度比起 LPV 来说是很慢的, 但是是可以优化的, 暂且不提.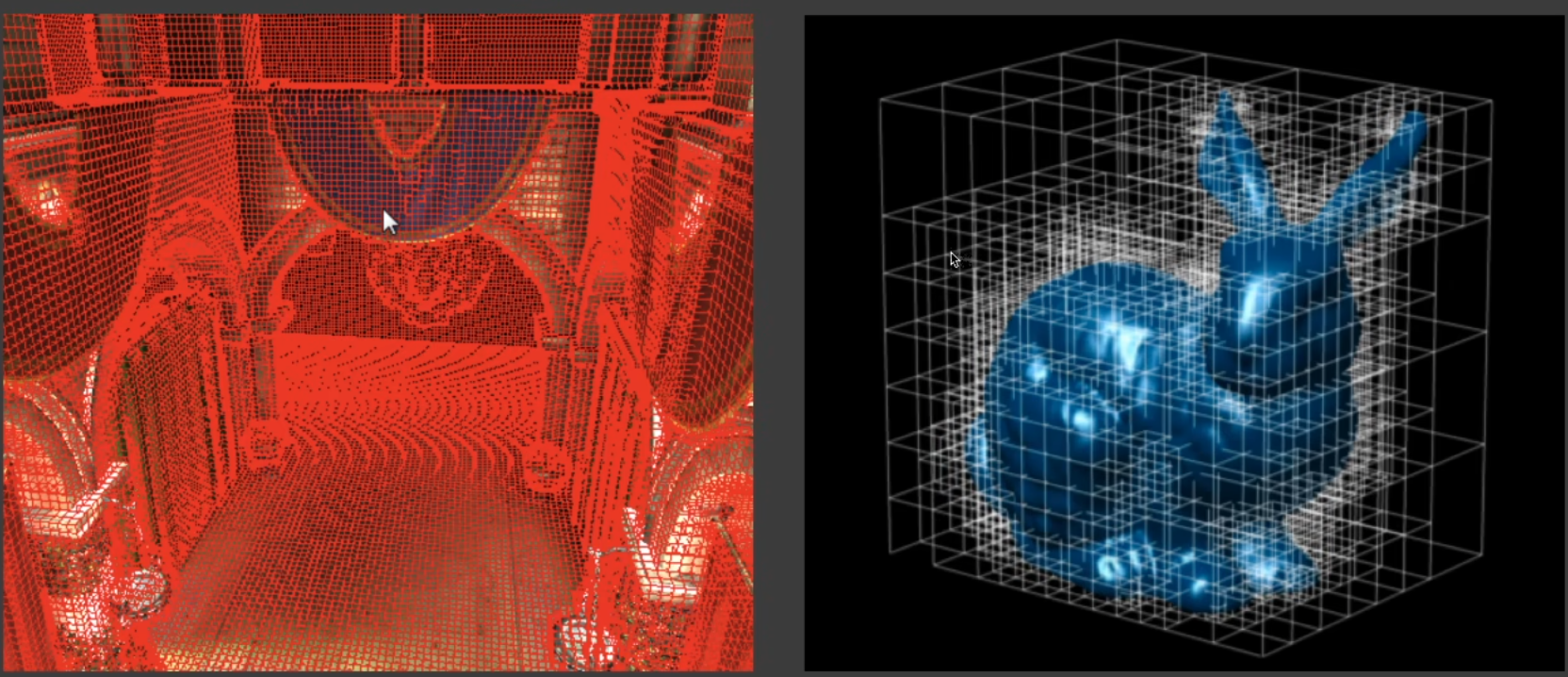
左图将场景划分为一系列的 voxel, 之后再划分成一个 Hierachical 树形结构, 右图就是 Hierachical 的体素.
具体步骤:
Pass1:Light pass
不管如何我们首先肯定是先要算直接光照找到哪些 voxel 会被照亮, 那么我们要先从接收到直接光照的 patch 开始, 不管是 RSM 还是什么先找出接受直接光照的 Patch.
但是由于场景是由 voxel 来表示的, 那么对于任何一个格子, 跟 LPV 的注入很像, 但是这里不在记录格子里表面的出射分布或者说认为表面是 diffuse 的半球分布, 也就是不再像 LPV 一样将所有的 radiance 加在一起求各方向的初始值, 那么也就是说可以支持反射物 (patch) 也是 Glossy 的.
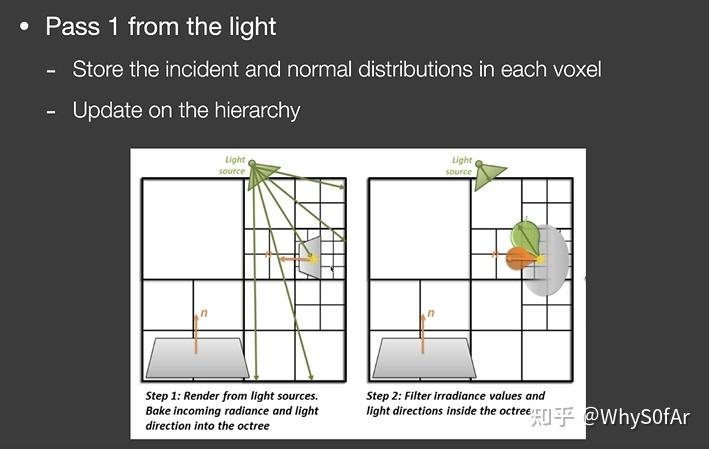
记录的是直接光源从哪些范围来(绿色部分),记录各个反射表面的法线(橙色部分),通过输入方向和法线范围两个信息然后通过表面的材质,来准确的算出出射的分布,这样就比 LPV 认为格子表面是 diffuse 再用 SH 来压缩的方法要准确,然后建立更高层级格子的这些特性。
Pass 2 : Camera pass
从这一步开始考虑场景的渲染了, 对于任何一个像素,知道了 Camera Ray 的方向,
I) 对于 Glossy 的表面,向反射方向追踪出一个锥形 (cone) 区域;
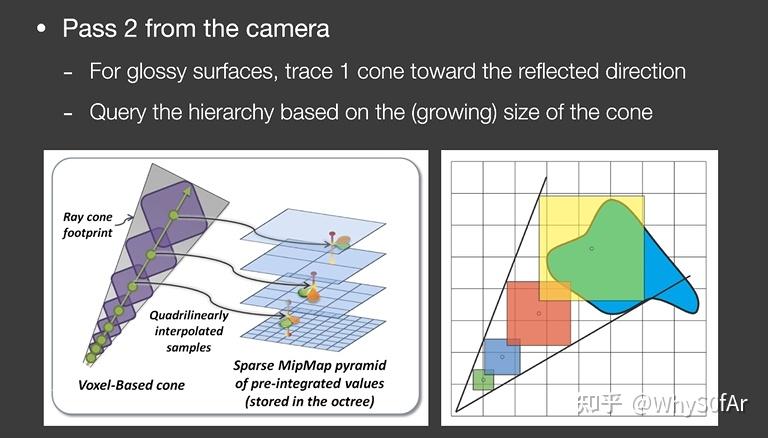
基于追踪出的圆锥面的大小,对格子的层级进行查询,就是对于场景中的所有体素都要判断是不是与这个锥形相交,如果相交的话就要把对于这个点的间接光照的贡献算出来 (我们存储了体素的光照输入方向和法线方向, 因此可以算出其输出的 radiance, 将 cone 区域内所有体素的 radiance 都算出来从而在 shading point 得到间接光照),也就是根据传播出的距离远近找对应层级的体素,然后找覆盖的范围。(论文中说查询相当于是 mipmap 的操作, 但是我个人没有看完, 等回头有时间将 vxgi 的论文好好看一遍)
II) 对于 diffuse 的情况来说, 通常考虑成若干圆锥,忽略圆锥 Tracing 时的重叠和空隙。
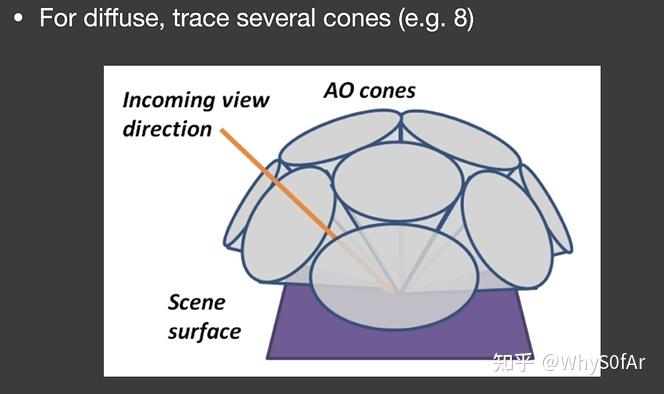
总结:
LPV 是把所有的次级光源发出的 Radiance 传播到了场景中的所有位置,只需要做一次从而让场景每个 Voxel 都有自己的 radiance,但是由于 LPV 使用的 3D 网格特性,并且采用了 SH 进行表示和压缩,因此结果并不准确,而且由于使用了 SH 因此只能考虑 diffuse 的, 但是速度是很快的。
VXGI 把场景的次级光源记录为一个层次结构,对于一个 Shading Point,我们要去通过 Corn Tracing 找到哪些次级光源能够照亮这个点。



结果的质量非常好,与光线追踪的结果非常接近,但是开销还是太大,应用受到了限制。对于 VXGI 我们需要预先对场景体素化,也是一个非常大的问题,由于每一个 Shading point 都要做一些 cone Tracing,操作已经非常像离线渲染了。
实时 GI(屏幕空间)
那么我们首先需要知道 什么是屏幕空间?
- 使用的所有信息都来自 “屏幕”,也就是做全局光照之前屏幕上能看到的信息,这些信息也就是做全局光照之前的直接光照信息;
- 相当于对这张图做一个后期处理,从而来 “弄” 出全局光照。
接下来我们开始讲屏幕空间如何去做全局光照, 首先来讲 SSAO 再讲 SSDO:
SSAO 屏幕空间环境光遮蔽
Screen Space Ambient Occlusion
在开始介绍的时候我们说过 CRY ENGINE, SSAO 最早应用的游戏是使用 CRY ENGINE2 做出来的孤岛危机一代, AKA 显卡杀手.

那么我们为什么要来搞这个环境光遮蔽呢?
首先我们来知道什么是 AO:

左边是进行了 AO 的, 右边是没有进行 AO 的, 之间的差别还是很明显的.
- 通过一系列的 contact shadow(接触阴影) 让物体与物体之间的相对位置表示的更明显, 从而让物体相对位置感更强
- AO 是非常非常容易去实现的
SSAO:
- AO 是一个对于全局光照的近似
- 在屏幕空间意味着从 camera 渲染场景得到信息, 而非是场景中的所有信息
总之,在屏幕空间对于全局光照的近似就是 SSAO.
三个重要的假设:
- 由于我们不知道间接光照是什么,因此我们假设任何一个 shading point 上来自任何方向的间接光照 (incident lighting) 是一个常数
- 虽然我们考虑了任何一个 shading point 上来自任何方向的间接光照是一样的, 但并不是每个方向都可能接收到间接光照 (incident lighting),也就是不同位置的 Visibility 是不同的。
- 假设物体是 Diffuse 的, 即使是一个 glossy 物体我们也以 diffuse 去渲染
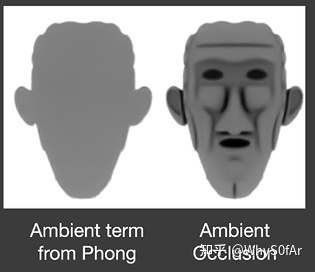
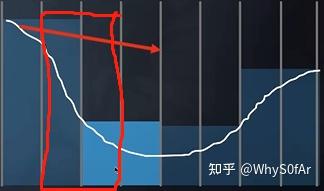
我们可以看到:
左边是任何一个 shading point 上来自任何方向的间接光照 (incident lighting) 是一个常数.
右边是我们考虑了任何一个 shading point 上不同方向的 visibility 后得到的结果.
在环境光一样的情况下考虑遮挡关系.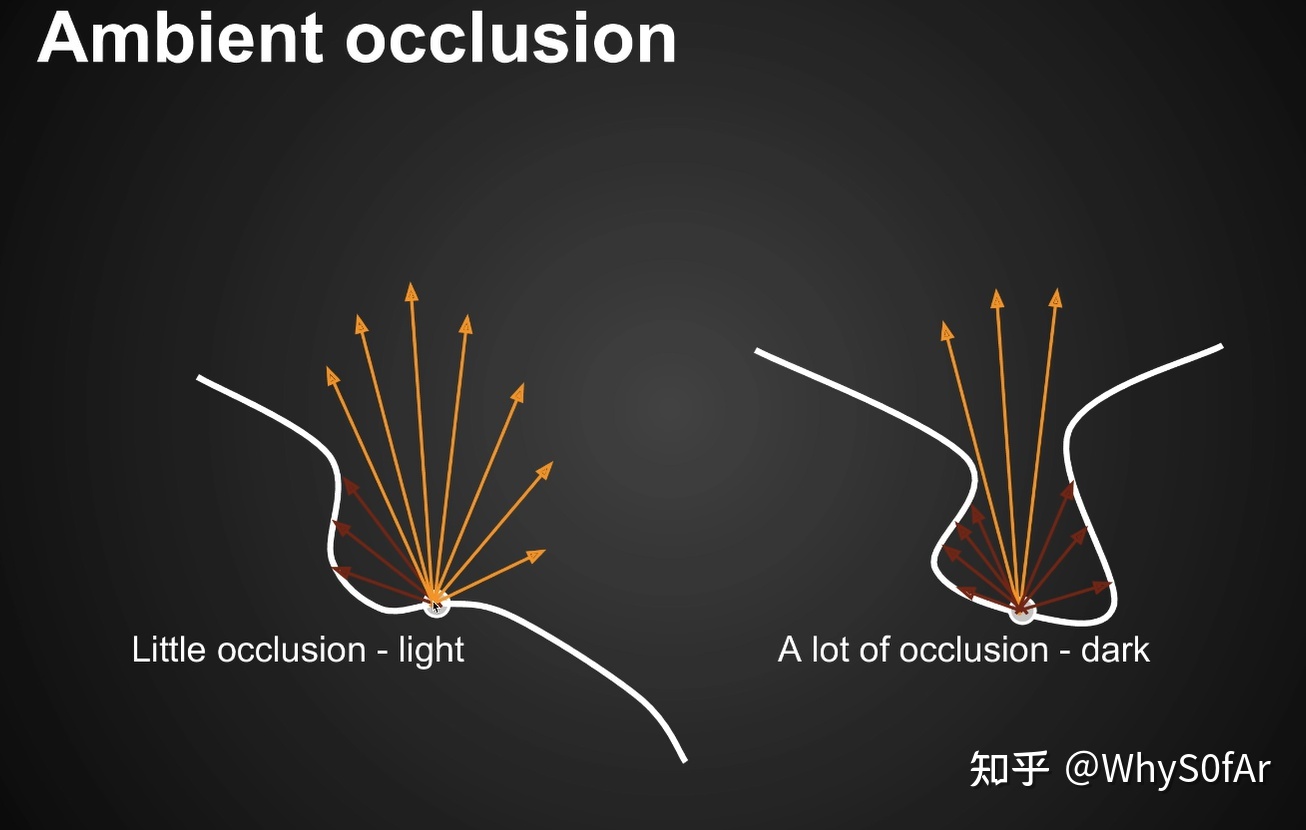
图中红色部分表示被遮挡, 黄色部分表示未被遮挡, 我们可以明显的得出一个结论, 左边的 Shading point 要比右边的亮一点.
接下来我们来理解一下它背后的理论为什么说他是一个对 GI 的近似:
回到我们的老朋友 rendering equation 来, Lighjt (蓝), brdf (黄), visibility (橙).
还记得我们之前说的 RTR 中最常用的近似吗, 把一个 product integral 中的一项拆除去并除以一个空积分进行归一化, 由于这里我们要考虑的是各个方向的 visibility, 因此把 visibility 项拆出去:


蓝色方框中分母再将立体角 $d\omega i$ 拆成 $sin\theta d \theta d \varphi$ 之后对 $\theta$ 和 $\varphi$ 分别积分得到的结果是π,整个积分结果我们称其为 $k_{A}$ ,其实际意义是从一个点往所有方向看去按 cos 加权平均的平均 visibility。
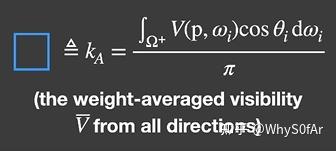
橙色方框中积分的结果,由于我们假设了所有方向的间接光照是一个常数,架设了物体是 Diffuse 的, 因此 BRDF 也是常数. 因此最终结果就是漫反射系数 × 间接光照强度 $Li$, 由于也间接光照强度 $Li$ 你可以随便指定, 漫反射系数也是你可以随便指定的, 因此就是橙色部分的结果是你自己来定义的一个数。
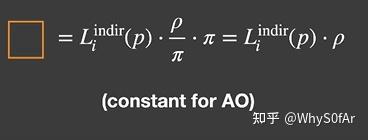
AO 就是: shading point 的加权平均 visibility * 一个你自己定义的颜色
深入理解:
- 我们可以把$f (x)$整个积分中拆出来并归一化这个操作,换成求$f (x$)在$g (x)$的覆盖范围 (Support 内) 的平均值, 由于 brdf 是 diffuse 的, 是一个常数, 间接光照也是一个常数, 因此 $g (x)$就是一个常数, 所以 AO 做这么一个拆分是完全没问题的.

- 一个比较难的理解, 在之前的公式中我们可以看到, 老师并不是对 dwi 进行积分, 而是对 cosθ dw 进行积分, 那么我们是怎么把_cosθi×_d_wi_都拆分拿出来的呢?
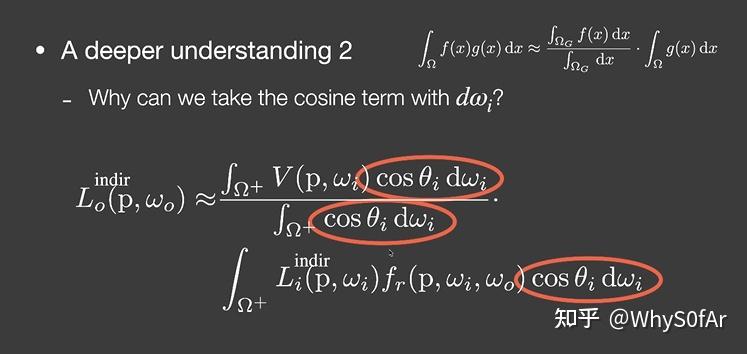
这里我们需要引入投影立体角这个概念:

立体角是单位球上的一个面积, 关于 cos 中的θ, 我们认为θ从北极开始到南极是 180 度, 那么立体角 * cosθ 得到的是什么呢?
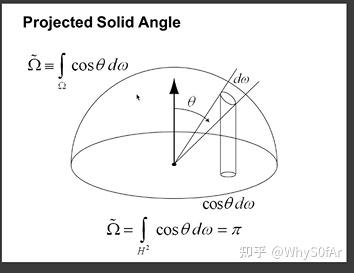
是我们把单位球上的面积投影到了单位圆上.
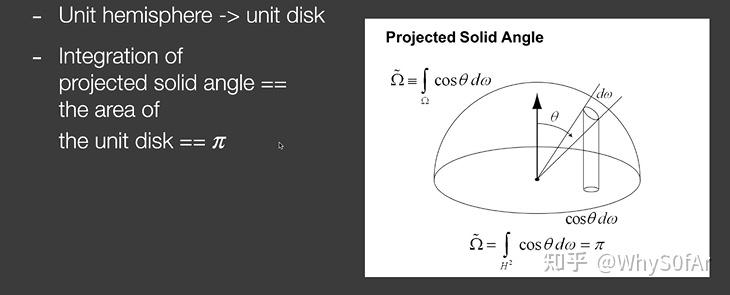
SSAO 终极简单理解:
- 间接光照是常数—Li 为常数
- BRDF 是 Diffuse 的—BRDF(fr_)是常数_ρ/π
- 因此这两项可以直接从积分里面拿出来,最后 Rendering Equation 就成了下面的形式, 也就是算 Visibility 的积分。

但是将 Brdf 和 lighting 提出来后积分里剩下的部分由于缺少了分母归一化这个操作, 所以得到的结果并不是加权平均的 visibility, 如果在一开始这么讲的话, 会不理解 kA 的来源.
那么接下来我们只需要去求得 visibility 部分就可以了, 也就是算加权平均的 visibility, 在世界空间下可以通过 ray tarcing 做,但是在屏幕空间下面我们该怎么做?

我们需要在 shading point 往不同方向 trace 判定究竟有多少方向被挡, 这样说其实是不准确的, 我们以一个极端的例子来看, 在一个封闭的屋子里, 不管你从哪一个 shading point 去 trace 哪个方向, 不论 trace 的光线会不会打到周围的物体, 我们这跟光线不会出去这个封闭的屋子, 也就是最后的结果只能是被遮挡住, 所得到的 Ambient Occlusion 只会是 0.
这是因为, 反射光肯定是在有限的距离里反射过来的, 也就是间接光照是从一定范围内来的, 不可能是从无限远处, 因此如果我们做 tracing 肯定也是在一定范围内的,这样就解决了 tracing 无限远的话一定会被遮挡住这个问题.
但是出现了新问题, 就是超出这个范围的光照就被我们忽略了, 也就是我们忽略了那些在距离外的间接光照,如果我们限制范围太大, 那么所有东西都有可能遮挡住, 如果范围太小, 我们会忽略大部分的 incident lighting. 因此我们限制在一定范围内, 这是一个 trade off, 通常会选一个合适的范围, 也就是找一个合适的球的半径 - R.
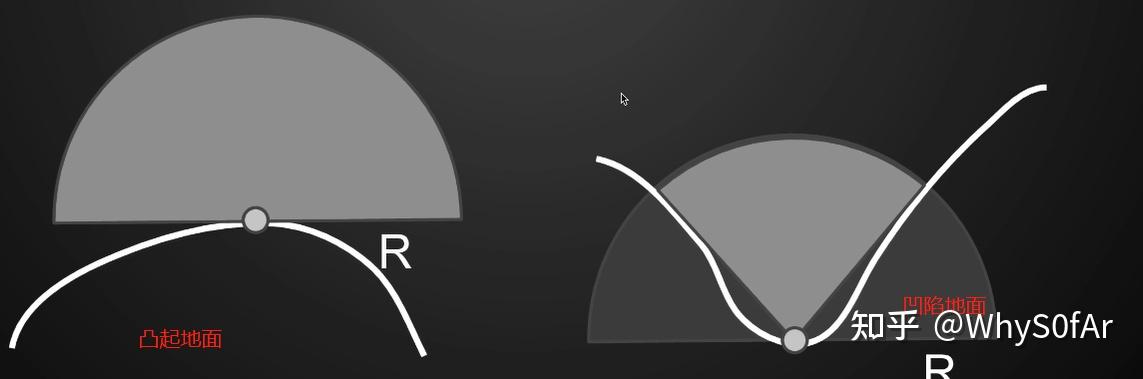
但是在 SSAO 中我们不是这么去计算 visibility 的, 它做了很聪明的假设, 他并没有去往四周 trace 光线, 因为那是一个很麻烦的事:
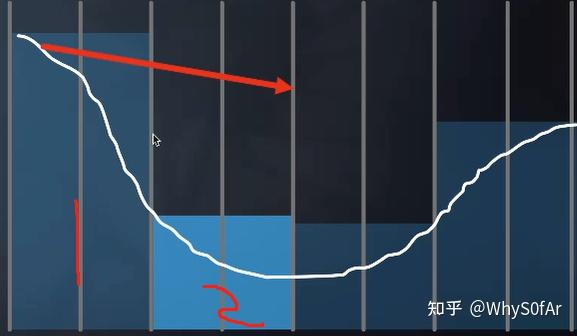
- 任何一个 Shading Point 在以 sp 为圆心, 半径为 R 的球的内部随机撒一些点, 然后判断这些点能不能被 Shading Point 直接看到;
- 从 camera 出发渲染, 我们肯定是可以得到深度图的, 而且深度图 Z-buffer 我们是可以把他看成是场景的一个简单近似,也就是我们从 camera 看到的下图中的白线, 球内部的点是可以投影到 Camera 然后找之前记录的深度, 如果深度更深, 则表示在物体内部, 被遮挡, 反之则未被遮挡.
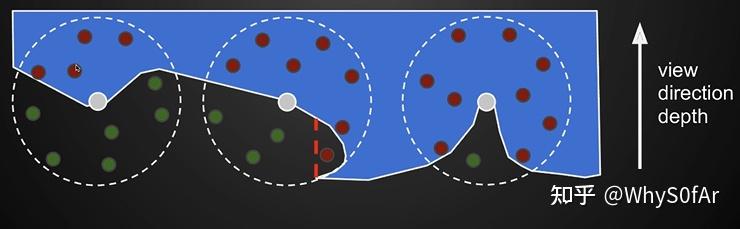
上图中蓝色区域部分表示的是场景物体, 也就是说蓝色区域外的绿点是可以被 shading point 直接看到的.
但是我们可以看到中间图的一个红点出现了问题,因为我们从 camera 看过去, 这个点比所圈部分的深度深, 因此虽然这个红点是能够被 Shading Point 看到的,但是由于是从 camera 出发,这里被判断为了看不到;
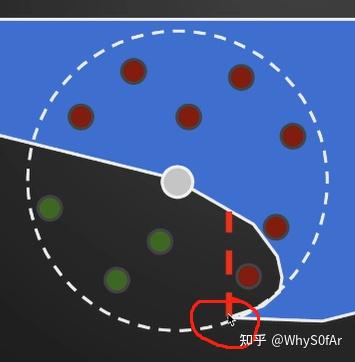
同时并没有考虑 COS,也就是没有考虑法线, 没有进行加权,因此这个假设并不是物理准确的,但是在实时渲染中看起来问题并不太大。
因为 Rendering Equation 通常只考虑法线所在的那半边,因此做这个判断也只判断法线所在的那半边也是没有问题的,也就是后面那个半球的的采样点没有用处。而由于 SSAO 的时代并不能获得场景的法线信息,因此 SSAO 采用了另一种方法来替代,也就是在整个球采样红点过半的时候才开始考虑 AO 问题。
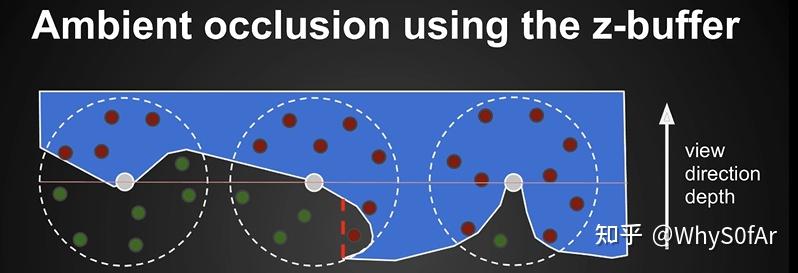
以中间的为例, 半边一共五个点, 两红三绿, 因此其 visibility 就是 0.6, 但这是未加权平均的 visibility.
由于是在场景深度上做的,因此在地板上由于临近屏幕空间中凳子的遮挡,也出现了错误的 AO。

入图中所圈部分, 我们是知道那一片的地板是不可能被石椅所遮挡的, 但是在开启了 SSAO, 由于我们是从 camera 出发去判断深度的, 所以这一块不可避免的出现了错误的 AO.
采样中的问题:

选 Sample 数量与 Pcss 一样, 也就是越多的 Sample 效果越好,但是这也会越慢
但我们可以用少量的 Sample,得到一个 noisy 的结果, 然后再这个 noisy 的结果上进行一个 denoising 来实现降噪,这些降噪的模糊和噪声在和场景中其他效果与光照叠加后就会变得非常不明显,从而获得比较好的综合效果。

但是我们上面说的是没有法线的方法,当有了场景 normal 之后,我们就知道去采样哪半球, 就可以只去算半球的情况了,同时也可以对不同的方向来加权(靠近中间大,靠近两边小),也就是 Horizon Based ambient occlusion—-HBAO.
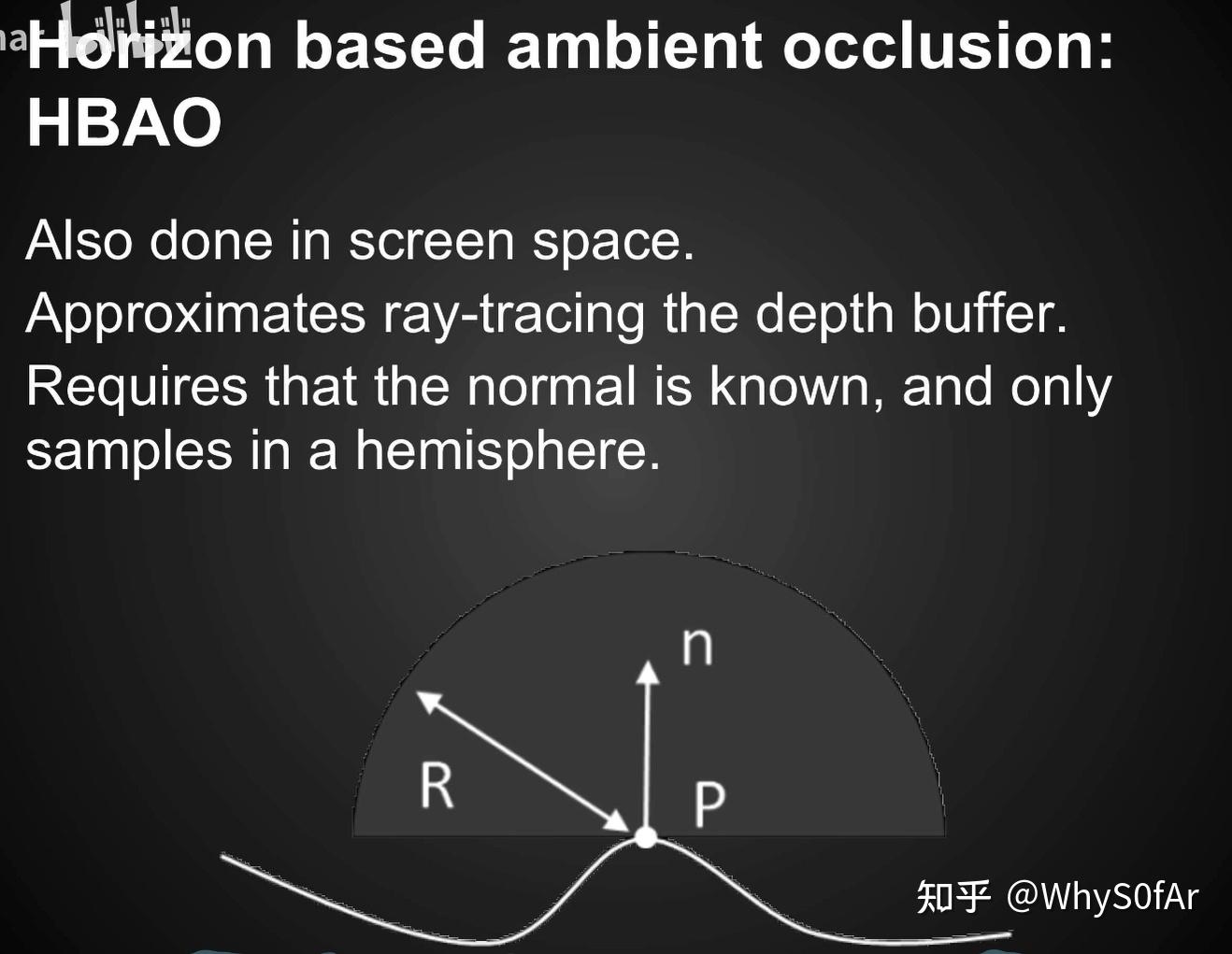
HBAO 的效果明显要比 SSAO 效果要好一点, 有效的减少了错误遮挡的情况(柱子后面尤为明显),但是要多存一个屏幕空间的法线。

HBAO 好的最重要原因就是因为只考虑了一个半球。
GAMES202 高质量实时渲染笔记 Lecture09:Real-Time Global Illumination (Screen space cont.)

本节课主要去讲述剩余的两种 Screen Space 的 GI 算法思路:SSDO 和 SSR.
SSDO 屏幕空间方向遮蔽
Screen space Direction occlusion
什么是 SSDO?

- 对 SSAO 的一个提高 / 升级;
- 比起 AO 考虑间接光照是一个常数, 在 DO 里我们更精确的考虑了间接光照。
关键思路
- 我们不去假设间接光照是固定不变的;
- RSM 中我们用 shadow map 去找到接收直接光照的点当作间接光照为其他的 Shading point 提供直接光照, 也就是说我们一定程度上是可以已经得到间接光照的信息。

通过 AO 和 DO 的对比我们可以看到, AO 能够产生变暗的效果使得物体相对感更强烈, 但 AO 并不能做到 Clolor Blending(不同颜色的 Diffuse 会互相照亮)

而我们想要的是更加真实具有 color blending 的效果

如图, 我们可以看到蓝色面上会接收到一点黄光,黄色面上也会有一点蓝光, 而并不是像 AO 一样简单的遮蔽位置整体暗一点,因此 DO 是更加精准的获得全局光照的一种方法。
- 在 SSDO 中, 我们要用直接光照的信息, 但不是从 RSM 中获得, 而是从 screen space 中得到.
做法:
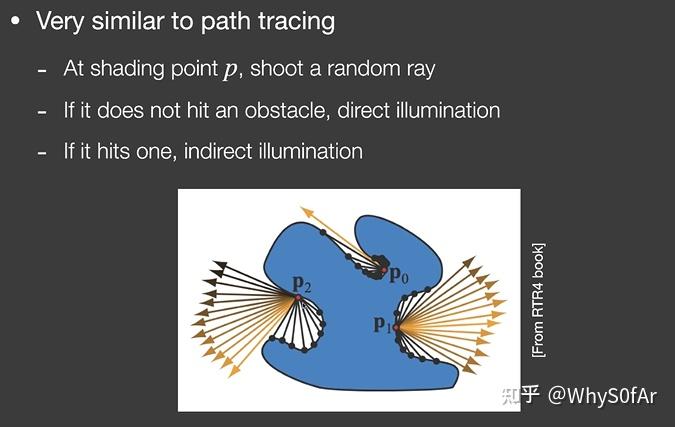
SSDO 的做法于 path tracing 很像, 假设在 Shading Point 的 P 点,随机的往某一个方向打出一根光线:
- 如果光线没碰到物体,则认为 P 点这里接收直接光照
- 如果碰到了一个点 Q, 那么算出 Q 点接受的直接光照打到 P 点的贡献, 从而求出 P 点的间接光照。
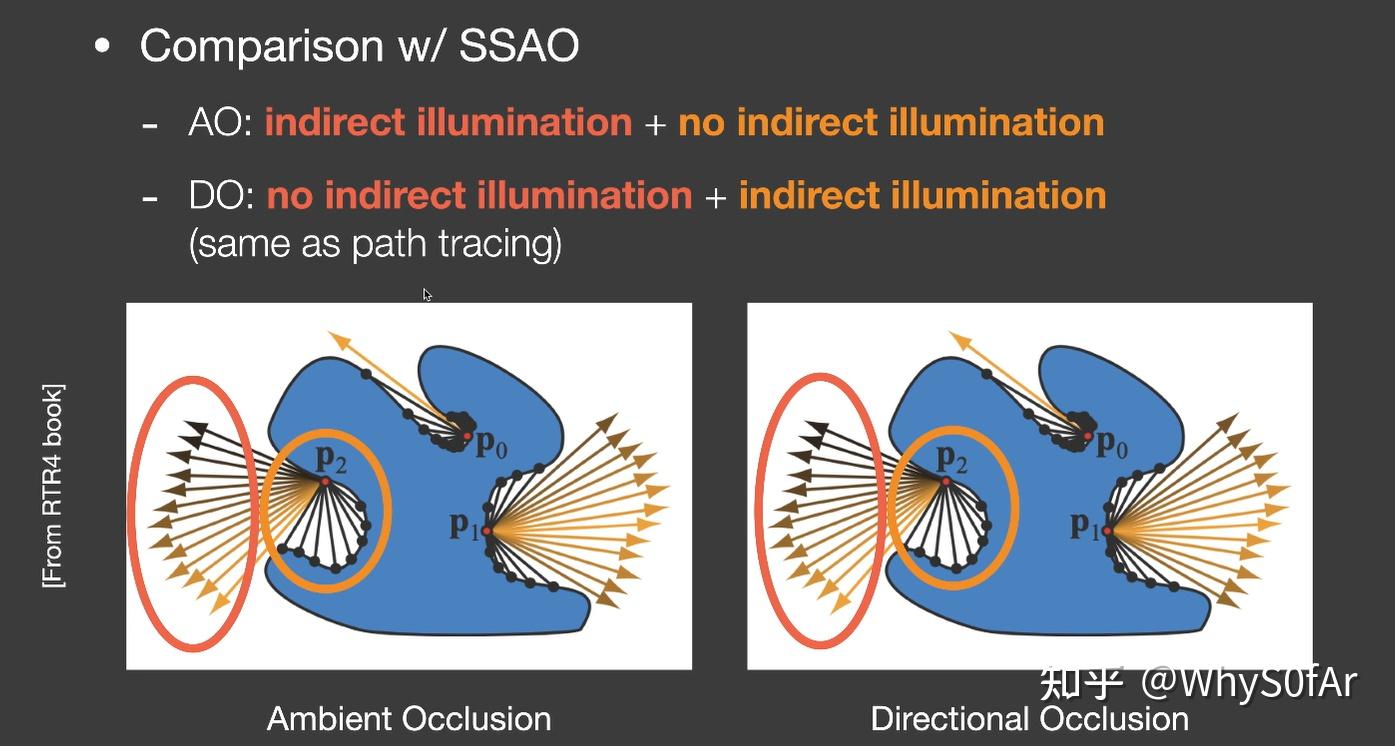
我们可以发现, SSAO 和 SSDO 是完全相反的两个假设:
AO:在 AO 中我们认为红色的框里能接收间接光照,黄色框里无法接收间接光照,然后求出加权平均的 visibility 值, 也就是假设间接光照是从比较远的地方来的;
DO:在 DO 中, 我们认为红色框里接收的是直接光照, 而黄色框里才是接收到的间接光照. 因为红色框里的光线打不到用来反射的面,因此这些方向上就不会有间接光照,黄色框里的光线能打到物体上,P 点接收到的是来自红色框的直接光照 + 黄色框里的间接光照, 也就是假设间接光照是从比较近的反射物来的。
其实这两个假设都不是完全正确的,物理真实的情况是这两种的混合:近处的是 DO,远距离是 AO,因此 AO 与 DO 也并没有矛盾。
回到渲染方程上, 将没有遮蔽的与遮蔽的方向上的光照分开考虑,那么对于 DO 如何解 Rendering Equation:
- 当 V=1 时是直接光照,而 DO 的计算是计算间接光照的,因此这个我们完全不用去计算与考虑
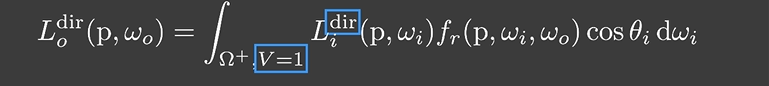
- 当 V=0 时也就是间接光照的情况,这个是我们需要关注与计算的。
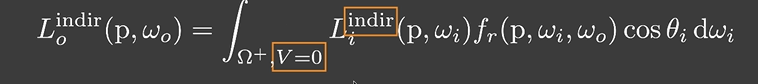
从一个 pixel 或者 patch 计算间接光照在 lecture07 - 下半部分的 RSM 中我们讲过了。
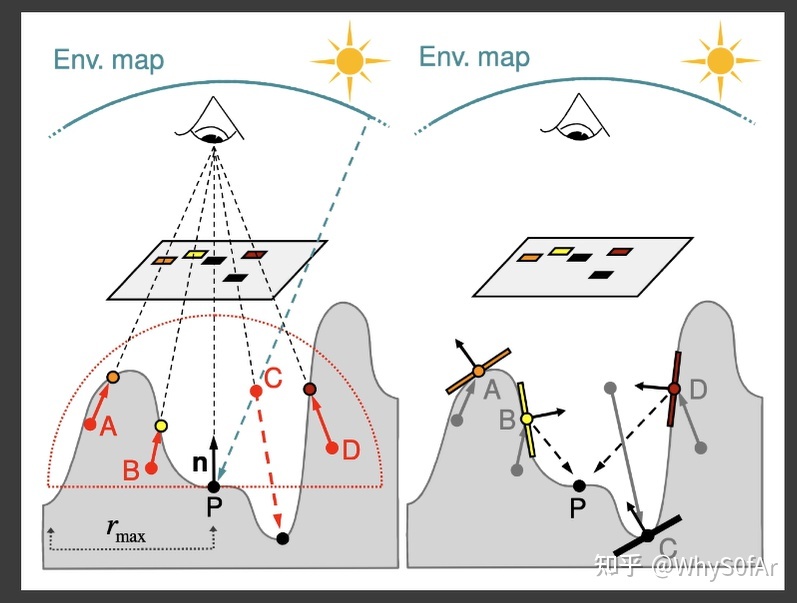
SSDO 的核心是要找哪些 patch 会被挡住,也就是对点 P 提供间接光照贡献的是哪些点,做法是与 AO 完全一样的。
我们同样考虑点 P 法线部分的半球,判断从 P 点往 A、B、C、D 四个方向看会不会被挡住,由于是屏幕空间的算法, 因此这里我们同样不考虑在 3D 场景中 A, B, C, D 四点会不会与 P 连成光线, 只考虑从 camera 看去 A, B, C, D 与 P 连成的光线会不会被挡住。
这里 A/B/D 这三个点的深度比从 camera 看去的最小深度深, 也就是说 PA, PB, PD 方向会被物体挡住, 因此会为 P 点提供间接光照。然后把我们用在 RSM 中讲的计算间接光照的方法这些点对 P 的贡献加起来。
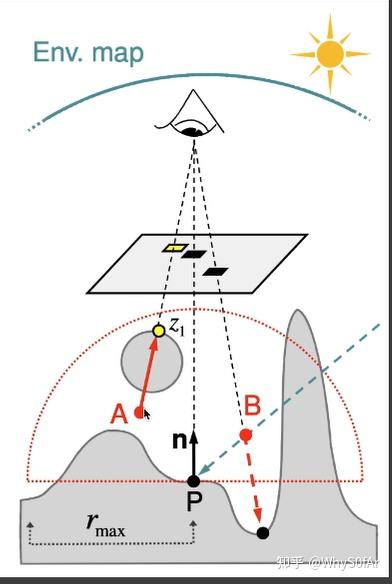
SSDO 也会出现一些问题, 如下图是假设与实际情况不同的情况,因为我们是在屏幕空间处理的, 因此在 A 点虽然会被 canmera 看不到,但是 AP 之间是不会挡住的, 实际上 A 点需要提供间接光照给 P 点, 但在 SSDO 算法中则不提供。
从计算量上来看与 SSAO 差不多,但是不同之处是,判定会被挡住的时候,会额外计算被挡住的小片的贡献,质量非常接近离线渲染。
问题:
P 点对于半球上的点可见性是通过 Camera 对这些点的可见性来近似计算的,存在于屏幕空间中丢失信息的问题,下图是一个很明显的例子,当黄色的面朝向屏幕的时候地面的 SSDO 信息是正确的,而当旋转过去之后,就看不到 SSDO 的信息了。

SSDO 只能解决一个很小范围内的全局光照,下图是接近正确的情况,而如果使用 SSDO 来计算,方块右边是追踪不到远处绿色的墙的,方块上也就不会有绿色的反光。

SSR 屏幕空间反射
Screen space reflection
老师说更愿意把他叫做 Screen space Raytracing (SSR), 只把它理解成反射的话其实是听狭隘的.
首先什么是 SSR?
(肯定不是酒吞, 茨木, 妖刀姬他们)
- 仍然是一种在 RTR 中实现 GI 的方式;
- 是在屏幕空间做光线追踪:不需要知道 3D 空间中的三角形、网格、加速结构等 3D 信息,只需要屏幕空间中已有的信息

- 由于我们认为它是 screen space raytracing, 我们考虑的是任何光线 (不单单是反射光) 与场景去做求交.
- 找到交点后, 算出对 shading point 的贡献值.

图中可以看出,白框中的反射的信息都是屏幕中已有的信息(红框)
那么任何一个点反射的信息是什么, 是从哪里得到的?
白框里反射的是红框内的场景信息, 也就是说我们并不需要 3D 场景的什么信息, 而是从屏幕空间里已有的信息得到, 也就是反射的绝大多数信息是屏幕内已有的信息,这就是屏幕空间反射的核心思路。
基础的 SSR 算法:镜面反射
假设场景中已经渲染出来了上面的部分,对于地面还没有进行渲染,如何把反射的信息加进去。

对于任何一个像素:
- 知道 shading point 的观察方向后, 可以得出其反射方向
- 从 Shading point 点沿着反射方向延长找到与屏幕的壳的交点
- 将交点的颜色作为反射的颜色记录到 shading point。
除了可以做 specular 反射, 还可以做 glossy 反射:

如果说 specular 反射只需要反射一个方向的话, 那么对于一定 roughness 的材质来说我们要根据其 BRDF 的 Lobe 来考虑, 如果 lobe 比较细, 则需要很少的光线, 如果 lobe 比较越大, 像 diffuse 那种的话我们需要射出很多根光线

即使是地面凹凸不平, 也就是在地面的各法线方向不一致的情况下, 仍然可以得到反射的结果.
也就是说当我们知道几何和 normal 时, 不论是什么物体, 我们都可以往任何一个方向去 trace
即在知道几何和法线信息后, SSR 可以做任何的光线追踪
我们来总结一下 SSR 的思路:
- 我们有一个还没有进行反射的场景, 如 shaded scene 上的地面还并没有得到反射的结果
- 得到图中的 normal 信息和深度信息
- 进行 SSR, 我们想要的是对于地面的每一个 pixel, 我们都想计算出其反射到场景中的得到的值是多少
- 得到反射的值后, 将结果加到场景中去, 也就是在地面上的黄点反射到场景的上的绿色, 进行求交算到的结果加入到黄点中
- 得到一个镜面反射的效果
反射光求交
最简单的方法是:Linear Raymarch
黄色是 shading point, 虚线是反射光, 假设 camera 在右边, 那么从 camera 看去, 场景的壳就是曲线.
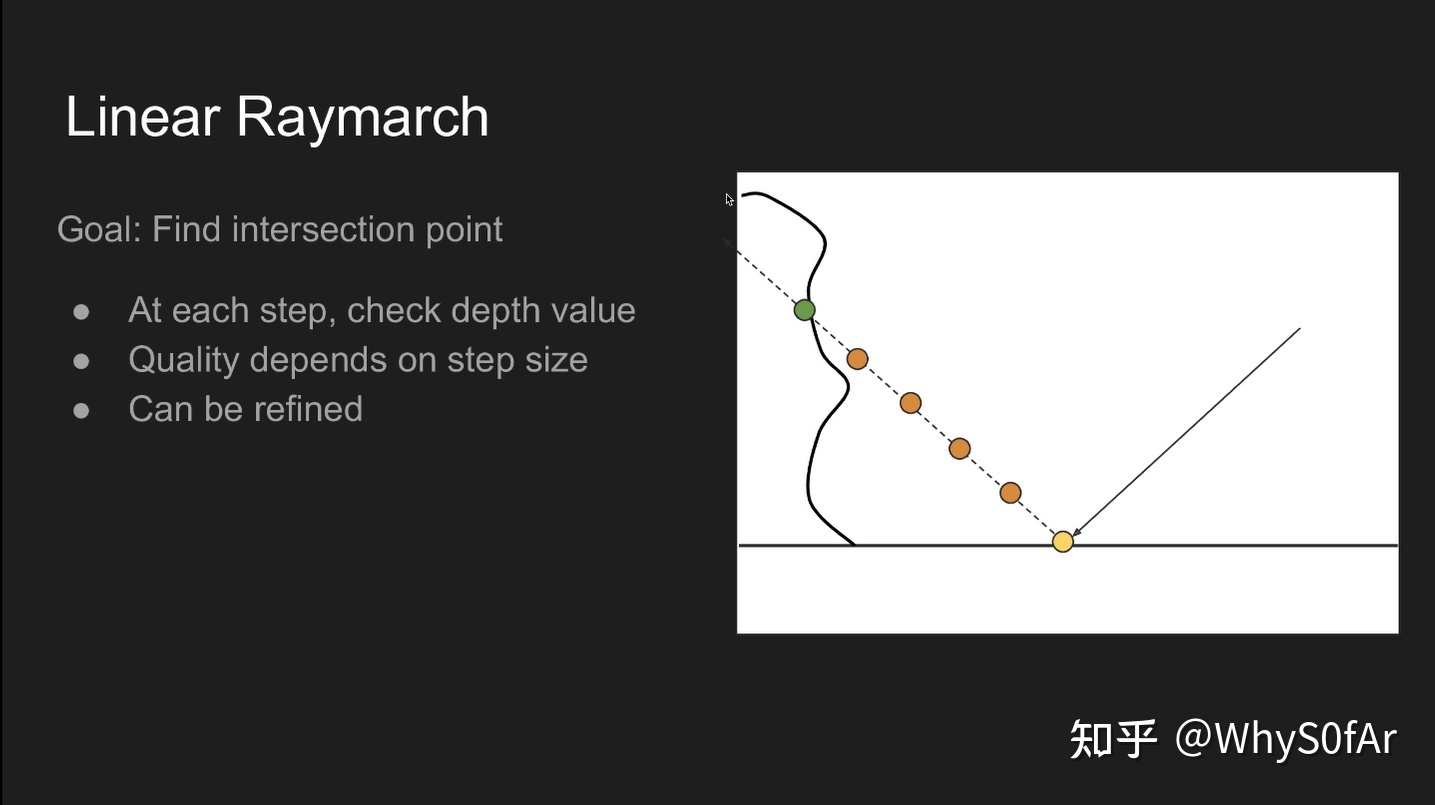
我们是为了找到反射光与场景 “壳” 的交点:
- 沿着反射方向以一个固定的步长逐步前进, 并将每次停止时的深度与壳的深度进行比较, 如果浅于壳, 则继续前进, 比壳深, 则停止求交, 也就是我们用深度来进行可见性判断
- 质量取决于步长的大小,步长小越精准,同时计算量也越大,因此步长太大太小都不行,在没有 SDF 的情况下,步长只能是一个定值。
由于步长是由我们来决定的, 太长太短都有其各自的问题, 因此我们引入另一种动态决定步长的方法:
分层光线追踪
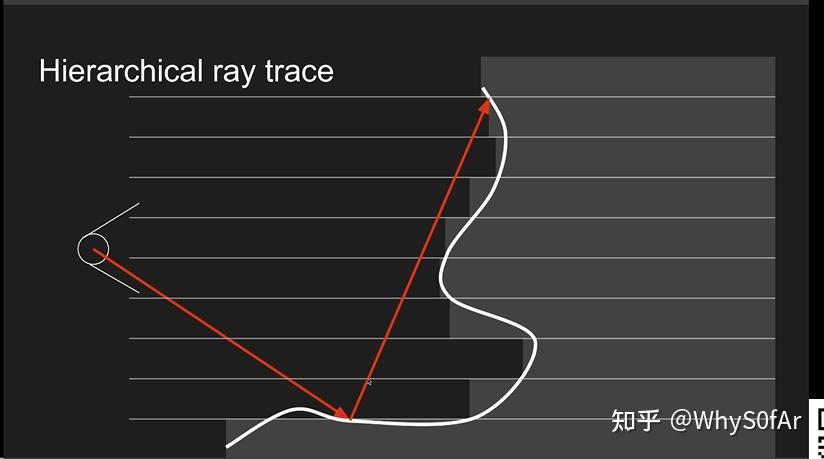
我们可以看到右边那条是反射光, 我们认为一个像素是一格, 我们在只 trace 一根反射光线的情况下,, 如果按一格一格的走, 每一个 fragment shader 都要做深度比较, 那么八格就是八次, 很浪费时间, 而且在这个图上, 我们就算一次走四格都不会与物体相交, 如果我们可以快速的得到一次往前走几格这个信息的话是很美妙的.
为了能得到这个信息我们需要做一个准备工作, 把场景的深度图, 做一个 mip-map, 但这个跟平常的 mip-map 不一样:
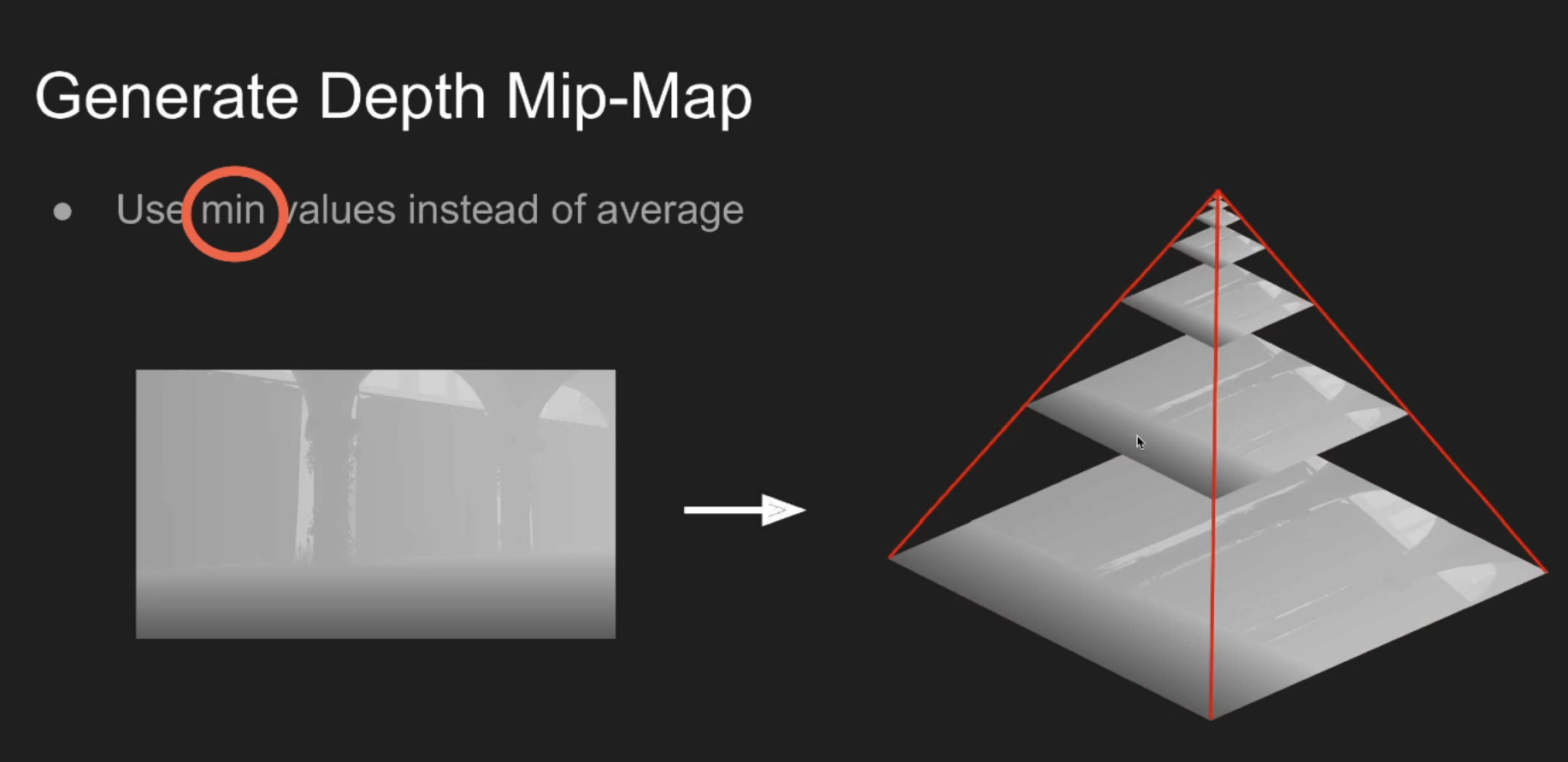
高一级的 Mipmap 存的并不是周围四个像素的深度平均,而是四个像素中深度的最小值

也就是鼠标所指的这一层的一个像素对应的是下图中四个像素中的深度最小值.
为什么要做深度图 mipmap 呢?

- 在 3D 空间做光线追踪时, 为了加速光线与场景求交,我们通常会做一个加速的层次结构(BVH/KD-tree)
- 在屏幕空间同样做一个类似加速结构,可以快速跳过不可能相交的像素;
- 如果我们用最小值操作的 mip-map 会得到一个保守逻辑:
- 如果一根光线与 mip-map 中的上层结点不相交, 那他肯定也不会与这个结点的子节点相交.
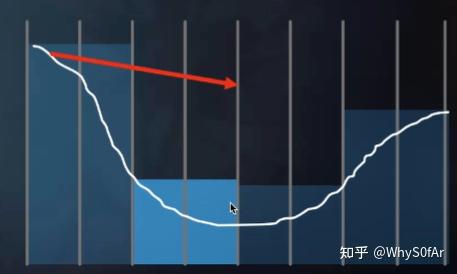
我们知道 mip-map 是一个 2 维的东西, 这里是 1 维的表示, 一个格子表示一个像素, 一共有八个格子.
- level 0:每个格进行判断
- Level 1:每两个格进行判断
- level 2:每四个格进行判断是
- 我们这里先以 level 1 为例子.
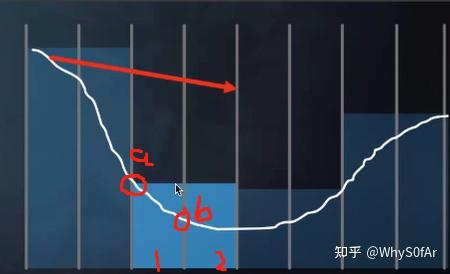
对于像素 1, 他记录的最浅深度为 a, 对于像素 2 它记录的最浅深度为 b.
对于这一层来说由于我们要的是最小值而不是平均, 因此深度取到了 a.
由于这根光线不会与蓝色层所表示的最小深度 a 相交, 因此就不可能与层里的 1 或 2 相交了.
这就是他的一个基本逻辑, 从而让我们可以快速的跳过很多格子
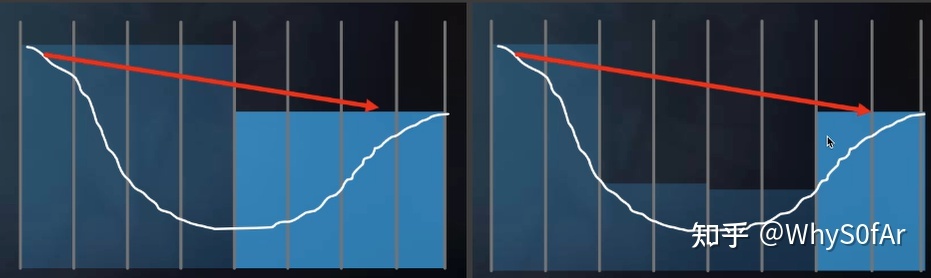
这里是 level 2, 当光线能够与右边部分相交时, 也就是说他能够与其的两个字节点相交, 因此我们要去判断与哪个子节点相交, 由于左边的最小深度不符合, 因此与右边的相交.
也就是我们对场景的壳从深度方面做了一个加速结构, 我们来看一下他的伪代码:
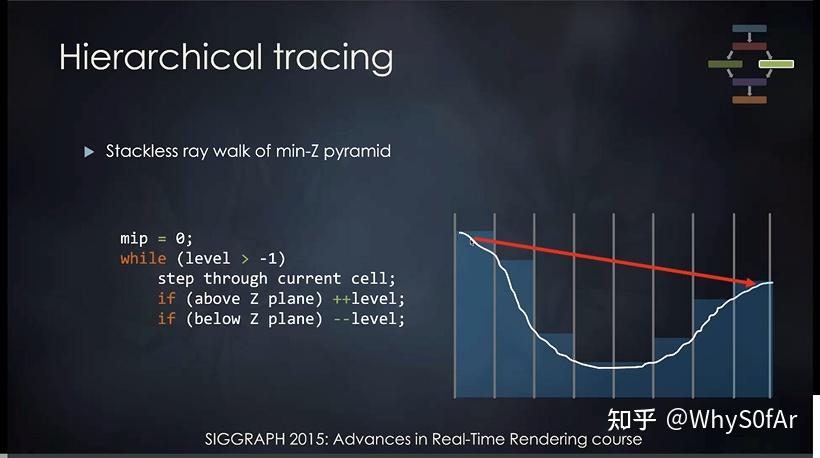
- 先走一个格子 (最小的步长),发现没有交点, 那么胆子大一点
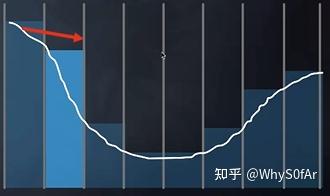
- 然后在原来的基础上再走两格 (level 1 包含的格子),发现还没交点, 胆子再大一点
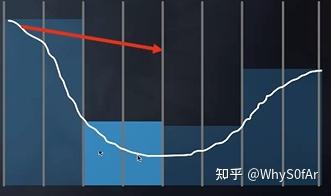
- 继续走 4 格 (level 2),有了交点;
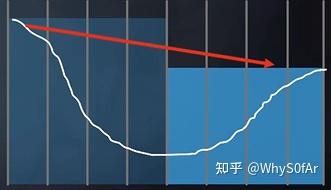
- 考虑更精细的层 (退回 level 1),发现还是有交点

- 由于这里在考虑 level 1 情况时交点出现在了左半边,因此退回 level 0 先判断与左边有没有交点,这时候发现没有交点,进入 Level 1;
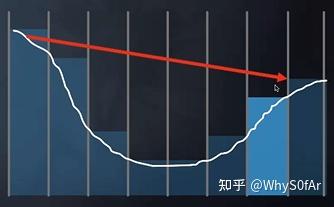
- 再往前走 2 格发现有交点,并且交点在左半边;
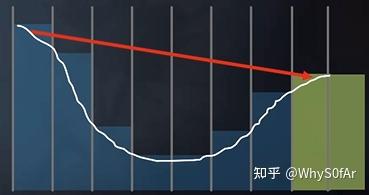
- 这时候就要退回 Level 0, 向前走一格最终发现了交点,求交结束。
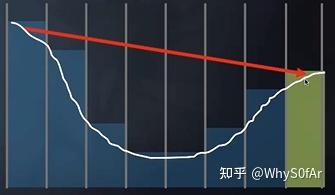
停下来的两个条件:
- 找到了交点
- 一直没找到交点
Mipmap 可以做范围查询,可以做正方形查询,但是做不了准确的起点不在 2 的 K 次方上的深度的查询。
也就是红色方框区域的最小深度, 我们硬要求的话, 我们需要算出 1 和 2 的最小深度, 然后进行插值才能得到它的最小深度.
我们来回顾一下:
由于我们不知道以一个多长的固定的步长来逐步前进求交点, 因此我们用高一级的 Mipmap 存的并不是周围四个像素的深度平均,而是四个像素中深度的最小值来动态的决定步长, 从而可以快速的求到任何光线与场景壳的交点.
但是 SSR 仍然有屏幕遮挡的问题:
不在屏幕中的信息是不会被反射的,丢失正常的反射信息。

我们可以看到手指那边得到了一个可笑的结果, 这就是 SSR 的问题, 他只会反射出 camera 所看到的, 而不是 3D 场景中真实存在的所有, 这也是我们学到的 screen space 的三个算法的一个通病, 整体看来只有 SSDO 要稍微好点.
还有一个就是屏幕边缘信息的缺失问题:

我们可以知道地板上的红色部分是有反射的, 但是黄色部分由于是在屏幕外, 因为得不到反射, 但是实际上他应该是有反射的.
这种问题可以根据反射光走的距离做一个衰减减少违和感。
至此我们完成了屏幕空间光线追踪的部分, 但是我们还没完成如何计算 shading.
这部分与路径追踪的方法完全相同,仅仅是把光线与场景求交变成了光线与 “壳” 求交,因此路径追踪的算法在这里是可以直接使用的。
对于任何一个 shading point,看到的 radicance 就是对半球进行积分, 如果是 specular 的物体, 那么相当于光线打到物体的哪里, 就用它所发出的 radiance 就可以.
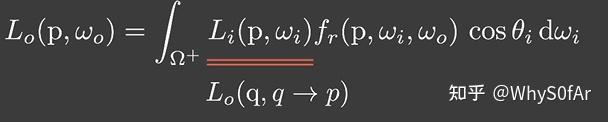
如果是 glossy 情况下, 同样的用蒙特卡洛多采样几根光线, 不管怎么所打到的物体反射过来的 radiance, 一定就是 shading point 点接收到的 incident radiance.
这里我们同样需要假设反射物 / 次级光源是 Diffuse 的情况, 地板之类的接收物可以是任何物体.
问题:
- Flux Intensity 是否存在平方反比衰减的问题?
- 不存在,这里做的是 BRDF sampling,并不是某个指定次级光源到 shading point,因此并不存在平方反比衰减的情况。
- 是否能够处理好次级光源与 shading point 的可见性的问题?
- 由于是路径追踪 Tracing 计算出来的,看到的一定是能够看见的,因此是没有这个问题的。
屏幕空间反射中的自然特殊现象:
由于结果是 tracing 出来的,因此很多现象是自然就能做到的,并不用做 trick,类似很多模糊等现象可以直接实现。
① Sharp and blurry reflection:Glossy 物体反射的模糊现象。

② Contact hardening:对于物体来说,近处的物体反射清晰,远处反射模糊,当反射物是 Glossy 时反射的 lobe 是一个锥形,当距离越远锥形的截面越越大,也就会发生模糊现象。

③ Specular elongation:反射在垂直方向被拉长的现象,在雨天常见的现象,当我们认为地面是各向同性的,也就是法线分布是一个圆,反射出去的 lobe 就是一个椭圆。

④ Per-piex roughness and normal:对于不同的法线与粗糙度不同的现象。

SSR 总结
优点:
- 可以很快的做 glossy 与 specular 的反射
- 质量很好
- 没有 spikes 尖点与遮蔽的问题
缺点:
- 在 Diffuse 物体上并不是非常高效
- 丢失屏幕外的信息, 但这个是屏幕空间的局限性, 而不是光线追踪的问题
 微信
微信 支付宝
支付宝









