[!NOTE] D3D规定
[!NOTE] 龙书规定
本书中所使用的术语“标架”(frame)、“参考系”(frame of reference)、“空间”(space)和“坐标系”(coordinate System)皆表示相同的意义。
normalize 的不同译法:标准化,归一化,规范化,规格化,单位化…… 译者按:区间、范围为归一化,名词向量或空间为规范化 (把一个向量的长度变为单位长度称为向量的规范化,方法是将向量的每个分量除以该向量的模,结果得到一个单位向量)正交(orthogonal)和垂直(perpendicular)为同义词
总链接: DirectXMath 库函数 - Win32 apps | Microsoft Learn
库向量函数 P16:DirectXMath 库矢量负载函数 - Win32 apps | Microsoft Learn
库矩阵函数 P44:DirectXMath 库矩阵函数 - Win32 apps | Microsoft Learn
库四元数函数 P661: DirectXMath 库四元数函数 - Win32 apps | Microsoft Learn
库平面函数 P731: DirectXMath 库平面函数 - Win32 apps | Microsoft Learn
0 简介 该数学库采用了 SIMD 流指令拓展 2(SSE2)指令集,它借助 128 位宽的单指令多数据(SIMD) 寄存器,利用一条 SIMD 指令即可对 4 个 32 位浮点数或整数进行运算 。也就是说,我们可以用 1 条 SIMD 加法指令取代 4D 向量中 4 条普通的标量指令,从而直接算出 4 D 向量的加法结果。3D 和 2D 向量用不到的部分置 0 并忽略。
nums 1 2 #include <DirectXMath.h> #include <DirectXPackedVector.h>
DirectXMath 关联的头文件:
DirectXMath.h,命名空间 DirectXDirectXPackedVector.h,包含相关的数据结构,命名空间 DirectX::PackedVector
x86平台需要打开 vs 的 SSE2指令集。
注: 将XM_CALLCONV调用约定注解加在非构造函数名之前时,它会根据编译器的版本确定出对应的调用约定属性。
1 向量 向量类型 总结一下:
向量类型定义: typedef __m128 XMVECTOR ,这里的 __m128 是一种特殊的 SIMD 类型。必须通过此类型才可充分利用 SIMD 技术。 XMVECTOR 类型的数据按 16 字节对齐,对于局部变量和全局变量是自动实现的。
对于类中的数据成员,使用 XMFLOAT2(2D 向量)、XMFLOAT3 (3D 向量)和 XMFLOAT4 (4D 向量)类型。
在运算之前, 通过加载函数(loading function)将 XMFLOATn 类型转换为 XMVECTOR 类型。
用 XMVECTOR 实例来进行运算。
通过存储函数(storage function)将 XMVECTOR 类型转换为 XMFLOATn 类型。
加载和存储方法 将数据从 XMFLOATn 类型加载到 XMVECTOR 类型:
nums 1 2 3 4 5 6 7 8 XMVECTOR XM_CALLCONV XMLoadFloat2 (const XMFLOAT2 *pSource) ;XMVECTOR XM_CALLCONV XMLoadFloat3 (const XMFLOAT3 *pSource) ;XMVECTOR XM_CALLCONV XMLoadFloat4 (Const XMFLOAT4 *PSource) ;
将数据从 XMVECTOR 类型存储到 XMFLOATn 类型:
nums 1 2 3 4 5 6 void XM_CALLCONV XMStoreFloat2 (XMFLOAT2 *pDestination,FXMVECTOR V) void XM_CALLCONV XMStoreFloat3 (XMFLOAT3 *pDestination,FXMVECTOR V) void XM_CALLCONV XMStoreFloat4 (XMFLOAT4 *pDestination,FXMVECTOR V)
当我们只希望从 XMVECTOR 实例中得到某一个向量分量或将某一向量分量转换为 XMVECTOR 类型时,相关的存取方法如下:
nums 1 2 3 4 5 6 7 8 9 float XM_CALLCONV XMVectorGetX (FXMVECTOR V) float XM_CALLCONV XMVectorGetY (FXMVECTOR V) float XM_CALLCONV XMVectorGetZ (FXMVECTOR V) float XM_CALLCONV XMVectorGetW (FXMVECTOR V) XMVECTOR XM_CALLCONV XMVectorSetX (FXMVECTOR V, float x) ;XMVECTOR XM_CALLCONV XMVectorSetY (FXMVECTOR V, float y) ;XMVECTOR XM_CALLCONV XMVectorSetZ (FXMVECTOR V, float z) ;XMVECTOR XM_CALLCONV XMVectorSetW (FXMVECTOR V, float w) ;
参数的传递
[!NOTE] 调用约定库内部结构 - Win32 apps | Microsoft Learn
如果将 XMVECTOR 对象作为参数传递,这些对象定义为在 16 字节边界上对齐,则根据目标平台的不同调用要求集:__m128 值。标准是 __fastcall,它传递堆栈上的所有 __m128 值。
较新的 Visual Studio 编译器支持 __vectorcall 调用约定,该约定最多可将 XMVECTOR 实例的六个 __m128 值作为参数传递给 SSE/SSE2 寄存器中的函数。如果有足够的空间,它还可以通过 SSE/SSE2 寄存器传递异类矢量聚合 (也称为 XMMATRIX) 。
为了提高效率,可以将 XMVECTOR 类型的值作为函数参数,直接传送至 SSE/SSE 2 寄存器(register)里,而不存于栈(stack)内。
此方式传递的参数数量取决于用户使用的平台和编译器,因此为了代码通用性,我们将使用以下规则传递 XMVECTOR 参数:
●前 3 个 XMVECTOR 参数应当用类型 FXMVECTOR;XMVECTOR 参数应当用类型 GXMVECTOR;XMVECTOR 参数应当用类型 HXMVECTOR;XMVECTOR 参数应当用类型 CXMVECTOR;
nums 1 2 3 4 5 6 7 8 9 10 11 typedef const XMVECTOR& FXMVECTOR;typedef const XMVECTOR& GXMVECTOR;typedef const XMVECTOR& HXMVECTOR;typedef const XMVECTOR& CXMVECTOR;typedef const XMVECTOR FXMVECTOR;typedef const XMVECTOR GXMVECTOR;typedef const XMVECTOR HXMVECTOR;typedef const XMVECTOR& CXMVECTOR;
在声明具有 XMMATRIX 参数的函数时,要注意 1 个 XMMATRIX 应计作 4 个 XMVECTOR 参数这一点之外,其他的规则与传入 XMVECTOR 类型的参数时相一致。 FXMVECTOR 参数不超过两个,则第一个 XMMATRIX 参数应当为 FXMMATRIX 类型,其余的 XMMATRIX 参数均应为 CXMMATRIX 类型。
nums 1 2 3 4 5 6 7 typedef const XMMATRIX& FXMMATRIX;typedef const XMMATRIX& CXMMATRIX;typedef const XMMATRIX FXMMATRIX;typedef const XMMATRIX& CXMMATRIX;
需要遵守的规定
传递 MVECTOR 参数的规则仅适用于“输入”参数 。“输出”的 MVECTOR 参数应该始终使用 XMVECTOR& 或 XMVECTOR*,不会占用 SSE/SSE2 寄存器,所以它们的处理方式与非 MVECTOR 类型的参数一致。
由于__vectorcall的限制,建议不要对 C++ 构造函数使用 GXMVECTOR 或 HXMVECTOR 。 只需对前三个 XMVECTOR 值使用 FXMVECTOR,然后对其余值使用 CXMVECTOR。
由于__vectorcall的限制,建议不要对 C++ 构造函数使用 FXMMATRIX 。 只需使用 CXMMATRIX。
必须使用 XM_CALLCONV 批注来确保函数 根据编译器和体系结构使用适当的调用约定(__fastcall 与 __vectorcall)
由于__vectorcall 的限制,不要对 构造函数使用 XM_CALLCONV。
常向量 XMVECTOR 类型的常量实例用 XMVECTORF32 类型表示,运用初始化 语法的时候就要使用该类型。XMVECTORF32 是一种按 16 字节对齐的结构体。
nums 1 static const XMVECTORF32 g_vHalfVector = {0.5f ,0.5f ,0.5f ,0.5f };
另外,也可以通过 XMVECTORUU32 类型来创建由整形数据构成的 XMVECTOR 常向量:
nums 1 static const XMVECTORF32 vGrabY ={0x00000000 ,0x00000000 ,0x00000000 ,0x00000000 };
重载运算符 XMVECTOR 类型针对向量的加法运算、减法运算和标量乘法运算,都分别提供了对应的重载运算符。
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 XMVECTOR XM_CALLCONV operator + (FXMVECTOR V); XMVECTOR XM_CALLCONV operator - (FXMVECTOR V); XMVECTOR& XM_CALLCONV operator += (XMVECTOR& V1, FXMVECTOR V2); XMVECTOR& XM_CALLCONV operator -= (XMVECTOR& V1, FXMVECTOR V2); XMVECTOR& XM_CALLCONV operator *= (XMVECTOR& V1, FXMVECTOR V2); XMVECTOR& XM_CALLCONV operator /= (XMVECTOR& V1, FXMVECTOR V2); XMVECTOR& operator *= (XMVECTOR& V, float S); XMVECTOR& operator /= (XMVECTOR& V, float S); XMVECTOR XM_CALLCONV operator + (FXMVECTOR V1, FXMVECTOR V2); XMVECTOR XM_CALLCONV operator - (FXMVECTOR V1, FXMVECTOR V2); XMVECTOR XM_CALLCONV operator * (FXMVECTOR V1, FXMVECTOR V2); XMVECTOR XM_CALLCONV operator / (FXMVECTOR V1, FXMVECTOR V2); XMVECTOR XM_CALLCONV operator * (FXMVECTOR V, float S); XMVECTOR XM_CALLCONV operator * (float S, FXMVECTOR V); XMVECTOR XM_CALLCONV operator / (FXMVECTOR V, float S);
杂项 DirectXMath 库定义了一组与 π 有关的常用数学常量近似值:
nums 1 2 3 4 5 6 const float XM_PI = 3.141592654f ;const float XM_2PI = 6.283185307f ;const float XM_1DIVPI = 0.318309886f ;const float XM_1DIV2PI = 0.159154943f ;const float XM_PIDIV2 = 1.570796327f ;const float XM_PIDIV4 = 0.785398163f ;
下列内联函数实现了弧度和角度间的互相转化:
nums 1 2 3 4 inline float XMConvertToRadians (float fDegrees) return fDegrees * (XM_PI / 180.0f ); }inline float XMConvertToDegrees (float fRadians) return fRadians * (180.0f / XM_PI); }
DirectXMath 库还定义了求出两个数间较大值及较小值的函数:
nums 1 2 template <class T> inline T XMMin (T a, T b) return (a < b) ? a : b; }template <class T> inline T XMMax (T a, T b) return (a > b) ? a : b; }
Setter 函数 DirectXMath 库提供了下列函数,以设置 XMVECTOR 类型中的数据:
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 XMVECTOR XM_CALLCONV XMVectorZero () ;XMVECTOR XM_CALLCONV XMVectorSplatOne () ;XMVECTOR XM_CALLCONV XMVectorSet (float x, float y, float z, float w) ;XMVECTOR XM_CALLCONV XMVectorReplicate (float Value) ;XMVECTOR XM_CALLCONV XMVectorSplatX (FXMVECTOR V) ;XMVECTOR XM_CALLCONV XMVectorSplatY (FXMVECTOR V) ;XMVECTOR XM_CALLCONV XMVectorSplatZ (FXMVECTOR V) ;
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <windows.h> #include <DirectXMath.h> #include <DirectXPackedVector.h> #include <iostream> using namespace std;using namespace DirectX;using namespace DirectX::PackedVector;ostream& XM_CALLCONV operator <<(ostream& os, FXMVECTOR v) { XMFLOAT3 dest; XMStoreFloat3 (&dest, v); os << "(" << dest.x << ", " << dest.y << ", " << dest.z << ")" ; return os; } int main () cout.setf (ios_base::boolalpha); if (!XMVerifyCPUSupport ()) { cout << "directx math not supported" << endl; return 0 ; } XMVECTOR p = XMVectorZero (); XMVECTOR q = XMVectorSplatOne (); XMVECTOR u = XMVectorSet (1.0f , 2.0f , 3.0f , 0.0f ); XMVECTOR v = XMVectorReplicate (-2.0f ); XMVECTOR w = XMVectorSplatZ (u); cout << "p = " << p << endl; cout << "q = " << q << endl; cout << "u = " << u << endl; cout << "v = " << v << endl; cout << "w = " << w << endl; return 0 ; }
向量函数 DirectXMath 库提供了下面的函数来执行各种向量运算。我们主要围绕 3D 向量的运算函数进行讲解,类似的运算还有 2D 和 4D 版本。 除了表示维度的数字不同以外,这几种版本的函数名皆同。
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 XMVECTOR XM_CALLCONV XMVector3Length ( FXMVECTOR V) XMVECTOR XM_CALLCONV XMVector3LengthSq ( FXMVECTOR V) XMVECTOR XM_CALLCONV XMVector3Dot ( FXMVECTOR V1, FXMVECTOR V2) XMVECTOR XM_CALLCONV XMVector3Cross ( FXMVECTOR V1, FXMVECTOR V2) XMVECTOR XM_CALLCONV XMColorModulate ( FXMVECTOR c1, FXMVECTOR c2) XMVECTOR XM_CALLCONV XMVector3Normalize ( FXMVECTOR V) XMVECTOR XM_CALLCONV XMVector3Orthogonal ( FXMVECTOR V) XMVECTOR XM_CALLCONV XMVector3AngleBetweenVectors ( FXMVECTOR V1, FXMVECTOR V2) void XM_CALLCONV XMVector3ComponentsFromNormal ( XMVECTOR* pParallel, XMVECTOR* pPerpendicular, FXMVECTOR V, FXMVECTOR Normal) bool XM_CALLCONV XMVector3Equal ( FXMVECTOR V1, FXMVECTOR V2) bool XM_CALLCONV XMVector3NotEqual ( FXMVECTOR V1, FXMVECTOR V2)
[!NOTE] 注意XMVECTOR ,而得到的标量结果则被复制到 XMVECTOR 中的各个分量之中。如点积函数 XMVector3Dot ,此函数返回的向量为 $\left(\begin{array}{cc}\nu_1\cdot\nu_2,\nu_1\cdot\nu_2,\nu_1\cdot\nu_2,\nu_1\cdot\nu_2\end{array}\right)$ 这样做的原因之一是,将标量和 SIMD 向量的混合运算次数降到最低,使用户除了自定义的计算之外全程都使用 SIMD 技术,以提升计算效率。
DirectXMath 库也提供了一些估算方法,精度低但速度快。如果愿意为了速度而牺牲一些精度,则可以使用它们。下面是两个估算方法的例子:
nums 1 2 3 4 5 XMVECTOR XM_CALLCONV XMVector3LengthEst ( FXMVECTOR V) XMVECTOR XM_CALLCONV XMVector3NormalizeEst ( FXMVECTOR V)
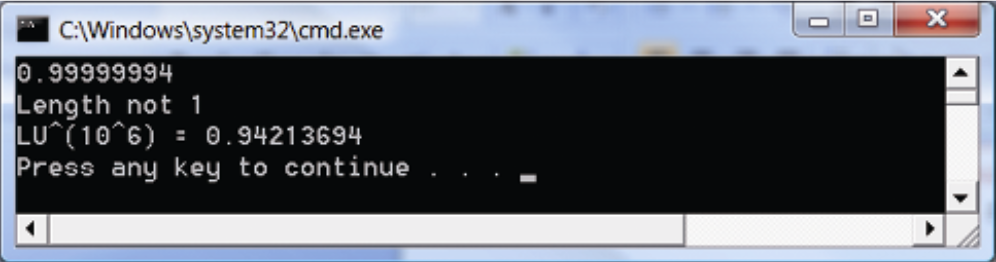
浮点数误差 在用计算机处理与向量有关的工作时,我们应当了解以下的内容。在比较浮点数时,一定要注意浮点数存在的误差。 我们认为相等的两个浮点数可能会因此而有细微的差别。例如,已知在数学上规范化向量的长度为 1,但是在计算机程序中的表达上,向量的长度只能接近于 1。此外,在数学中,对于任意实数 $p$ 有 $1^p=1$。但是,当只能在数值上逼近 1 时,随着幂 p 的增加,所求近似值的误差也在逐渐增大。由此可见,数值误差是可积累的 。下面这个小程序可印证这些观点:
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <windows.h> #include <DirectXMath.h> #include <DirectXPackedVector.h> #include <iostream> using namespace std;using namespace DirectX;using namespace DirectX::PackedVector;int main () cout.precision (8 ); if (!XMVerifyCPUSupport ()) { cout << "directx math not supported" << endl; return 0 ; } XMVECTOR u = XMVectorSet (1.0f , 1.0f , 1.0f , 0.0f ); XMVECTOR n = XMVector3Normalize (u); float LU = XMVectorGetX (XMVector3Length (n)); cout << LU << endl; if (LU == 1.0f ) cout << "Length 1" << endl; else cout << "Length not 1" << endl; float powLU = powf (LU, 1.0e6 f); cout << "LU^(10^6) = " << powLU << endl; }
为了弥补浮点数精确性上的不足,我们通过比较两个浮点数是否近似相等来加以解决。 在比较的时候,我们需要定义一个 Epsilon 常量,它是个非常小的值,可为误差留下一定的“缓冲”余地。如果两个数相差的值小于 Epsilon,我们就说这两个数是近似相等的。Epsilon 是针对浮点数的误差问题所指定的容差(tolerance) 。下面的函数解释了如何利用 Epsilon 来检测两个浮点数是否相等:
nums 1 2 3 4 5 6 const float Epsilon = 0.001f ;bool Equals (float lhs, float rhs) return fabs (lhs - rhs) < Epsilon ? true : false ; }
对此,DirectXMath 库提供了 XMVector3NearEqual 函数,用于以 Epsilon 作为容差,测试比较的向量是否相等:
nums 1 2 3 4 5 6 7 8 XMFINLINE bool XM_CALLCONV XMVector3NearEqual ( FXMVECTOR U, FXMVECTOR V, FXMVECTOR Epsilon)
2 矩阵 矩阵类型 DirectXMath 以定义在 DirectXMath.h 头文件中的 XMMATRIX 类来表示 4x4 矩阵(为了叙述清晰起见,这里进行了若干细节上的调整):
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #if (defined(_M_IX86) || defined(_M_X64) || defined(_M_ARM)) && defined (_XM_NO_INTRINSICS_)struct XMMATRIX #else __declspec(align (16 )) struct XMMATRIX #endif { XMVECTOR r[4 ]; XMMATRIX () {} XMMATRIX (FXMVECTOR R0, FXMVECTOR R1, FXMVECTOR R2, CXMVECTOR R3) { r[0 ] = R0; r[1 ] = R1; r[2 ] = R2; r[3 ] = R3; } XMMATRIX (float m00, float m01, float m02, float m03, float m10, float m11, float m12, float m13, float m20, float m21, float m22, float m23, float m30, float m31, float m32, float m33); explicit XMMATRIX (_In_reads_(16 ) const float *pArray) XMMATRIX& operator = (const XMMATRIX& M) { r[0 ] = M.r[0 ]; r[1 ] = M.r[1 ]; r[2 ] = M.r[2 ]; r[3 ] = M.r[3 ]; return *this ; } XMMATRIX operator + () const { return *this ; } XMMATRIX operator - () const ; XMMATRIX& XM_CALLCONV operator += (FXMMATRIX M); XMMATRIX& XM_CALLCONV operator -= (FXMMATRIX M); XMMATRIX& XM_CALLCONV operator *= (FXMMATRIX M); XMMATRIX& operator *= (float S); XMMATRIX& operator /= (float S); XMMATRIX XM_CALLCONV operator + (FXMMATRIX M) const ; XMMATRIX XM_CALLCONV operator - (FXMMATRIX M) const ; XMMATRIX XM_CALLCONV operator * (FXMMATRIX M) const ; XMMATRIX operator * (float S) const ; XMMATRIX operator / (float S) const ; friend XMMATRIX XM_CALLCONV operator * (float S, FXMMATRIX M); };
综上所述,XMMATRIX 由 4 个 XMVECTOR 实例所构成,并借此来使用 SIMD 技术。此外,XMMATRIX 类还为矩阵计算提供了多种重载运算符。
除了各种构造方法之外,还可以使用 XMMatrixSet 函数来创建 XMMATRIX 实例:
nums 1 2 3 4 5 XMMATRIX XM_CALLCONV XMMatrixSet ( float m00, float m01, float m02, float m03, float m10, float m11, float m12, float m13, float m20, float m21, float m22, float m23, float m30, float m31, float m32, float m33)
加载和存储方法 就像通过 XMFLOAT2 (2D),XMFLOAT3 (3D)和 XMFLOAT4 (4D)来存储类中不同维度的向量一样,DirectXMath 文档也建议我们用 XMFLOAT4X4 来存储类中的矩阵类型数据成员。
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 struct XMFLOAT4X4 { union { struct { float _11, _12, _13, _14; float _21, _22, _23, _24; float _31, _32, _33, _34; float _41, _42, _43, _44; }; float m[4 ][4 ]; }; XMFLOAT4X4 () {} XMFLOAT4X4 (float m00, float m01, float m02, float m03, float m10, float m11, float m12, float m13, float m20, float m21, float m22, float m23, float m30, float m31, float m32, float m33); explicit XMFLOAT4X4 (_In_reads_(16 ) const float *pArray) float operator () (size_t Row, size_t Column) const return m[Row][Column]; } float & operator () (size_t Row, size_t Column) return m[Row][Column]; } XMFLOAT4X4& operator =(const XMFLOAT4X4& Float4x4); };
通过下列方法将数据从 XMFLOAT4X4 内加载到 XMMATRIX 中:
nums 1 2 inline XMMATRIX XM_CALLCONV XMLoadFloat4x4 (const XMFLOAT4X4* pSource)
通过下列方法将数据从 XMMATRIX 内存储到 XMFLOAT4X4 中:
nums 1 2 inline void XM_CALLCONV XMStoreFloat4x4 (XMFLOAT4X4* pDestination, FXMMATRIX M)
矩阵函数 DirectXMath 库包含了下列与矩阵相关的实用函数:
nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 XMMATRIX XM_CALLCONV XMMatrixIdentity () ; bool XM_CALLCONV XMMatrixIsIdentity ( FXMMATRIX M) XMMATRIX XM_CALLCONV XMMatrixMultiply ( FXMMATRIX A, CXMMATRIX B) XMMATRIX XM_CALLCONV XMMatrixTranspose ( FXMMATRIX M) XMVECTOR XM_CALLCONV XMMatrixDeterminant ( FXMMATRIX M) XMMATRIX XM_CALLCONV XMMatrixInverse ( XMVECTOR* pDeterminant, FXMMATRIX M)
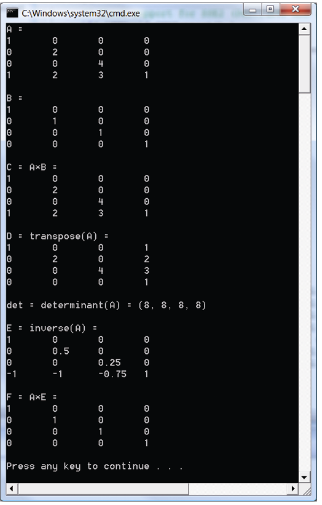
示例 nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <windows.h> #include <DirectXMath.h> #include <DirectXPackedVector.h> #include <iostream> using namespace std;using namespace DirectX;using namespace DirectX::PackedVector;ostream& XM_CALLCONV operator << (ostream& os, FXMVECTOR v) { XMFLOAT4 dest; XMStoreFloat4 (&dest, v); os << "(" << dest.x << ", " << dest.y << ", " << dest.z << ", " << dest.w << ")" ; return os; } ostream& XM_CALLCONV operator << (ostream& os, FXMMATRIX m) { for (int i = 0 ; i < 4 ; ++i) { os << XMVectorGetX (m.r[i]) << "\t" ; os << XMVectorGetY (m.r[i]) << "\t" ; os << XMVectorGetZ (m.r[i]) << "\t" ; os << XMVectorGetW (m.r[i]); os << endl; } return os; } int main () if (!XMVerifyCPUSupport ()) { cout << "directx math not supported" << endl; return 0 ; } XMMATRIX A (1.0f , 0.0f , 0.0f , 0.0f , 0.0f , 2.0f , 0.0f , 0.0f , 0.0f , 0.0f , 4.0f , 0.0f , 1.0f , 2.0f , 3.0f , 1.0f ) XMMATRIX B = XMMatrixIdentity (); XMMATRIX C = A * B; XMMATRIX D = XMMatrixTranspose (A); XMVECTOR det = XMMatrixDeterminant (A); XMMATRIX E = XMMatrixInverse (&det, A); XMMATRIX F = A * E; cout << "A = " << endl << A << endl; cout << "B = " << endl << B << endl; cout << "C = A*B = " << endl << C << endl; cout << "D = transpose(A) = " << endl << D << endl; cout << "det = determinant(A) = " << det << endl << endl; cout << "E = inverse(A) = " << endl << E << endl; cout << "F = A*E = " << endl << F << endl; return 0 ; }
3 变换 nums 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 XMMATRIX XM_CALLCONV XMMatrixScaling ( float ScaleX, float ScaleY, float ScaleZ)XMMATRIX XM_CALLCONV XMMatrixScalingFromVector ( FXMVECTOR Scale) XMMATRIX XM_CALLCONV XMMatrixRotationX ( float Angle) XMMATRIX XM_CALLCONV XMMatrixRotationY ( float Angle) XMMATRIX XM_CALLCONV XMMatrixRotationZ ( float Angle) XMMATRIX XM_CALLCONV XMMatrixRotationAxis ( FXMVECTOR Axis, float Angle) XMMATRIX XM_CALLCONV XMMatrixTranslation ( float OffsetX, float OffsetY, float OffsetZ)XMMATRIX XM_CALLCONV XMMatrixTranslationFromVector ( FXMVECTOR Offset) XMVECTOR XM_CALLCONV XMVector3TransformCoord ( FXMVECTOR V, CXMMATRIX M) XMVECTOR XM_CALLCONV XMVector3TransformNormal ( FXMVECTOR V, CXMMATRIX M)
构建透视投影矩阵
nums 1 2 3 4 5 6 7 XMMATRIX XM_CALLCONV XMMatrixPerspectiveFovLH ( float FovAngleY,float Aspect, float NearZ, float FarZ)
4 颜色运算 分量式乘法 nums 1 2 3 XMVECTOR XM_CALLCONV XMColorModulate ( FXMVECTOR c1, FXMVECTOR c2)
格式转换 32 位颜色转换 128 位颜色: 通过将整数范围 $[0,255]$ 映射到实数区间 $[0,1]$
$$
由于在 XMCOLOR 中通常将 4 个 8 位颜色分量封装为一个 32 位整数值(例如,一个 unsigned int 类型的值),因此在 32 位颜色与 128 位颜色互相转换的过程中常常需要进行一些额外的位运算(提取出每个量)。对此,DirectXMath 库中定义了一个获取 XMCOLOR 类型实例并返回其相应 XMVECTOR 类型值的函数:
nums 1 XMVECTOR XM_ CALLCONV PackedVector::XMLoadColor (const XMCOLOR*psource) ;
XMCOLOR 类中使用的格式位 ARGBXMVECTOR 转换至 XMCOLOR:nums 1 2 void XM_ CALLCONV PackedVector::XMStorecolor (XMCOLOR* pDestination, FXMVECTOR V)
一般来说,128 位颜色值常用于高精度的颜色运算(例如位于像素着色器中的各种运算)。在这种情况下,由于运算所用的精度较高,因此可有效降低计算过程中所产生的误差。



 微信
微信 支付宝
支付宝



