
C++精粹
零、预处理器
确保头文件多次包含仍能安全工作的常用技术是预处理器,预处理器是在编译之前执行的一段程序,任何以 # 开头的东西,都被称为预处理器命令或者预处理器指令。如 #include ,当预处理器看到 #include 标记时就会用指定的头文件内容代替 #include 。
头文件保护符
下面来说 # pargma once
pragma 本质上是一个被发送到编译器或预处理器的预处理指令。
pragma once 阻止我们单个头文件多次被 include 在同一个 cpp 文件里。
1 | //新方法 |
include 用于告诉编译器,包含文件的路径是什么,有两种写法:
#include< >: 在所有 include 路径中搜索文件#include" ":引用相对路径,现在也有#include< >的功能,作用范围更大
宏 macro
#define #宏 #macro
预处理阶段 :当编译 C++ 代码时,首先预处理器会检查一遍 C++ 所有的以 # 符号开头(这是预编译指令符号)的语句,当预编译器将这些代码评估完后给到编译器去进行实际的编译。
宏和模板的区别:发生时间不同,宏是在预处理阶段就被评估了,而模板会被评估的更晚一点。
用宏的目的:写一些宏将代码中的文本替换为其他东西(纯文本替换)**(不一定是简单的替换,是可以自定义调用宏的方式的)
1
2
3
4
5
6
7
//这里可以不用放分号,如果放分号就会加入宏里面了
int main() {
WAIT;
//等效于std::cin.get(),属于纯文本替换
//但单纯做这种操作是很愚蠢的,除了自己以外别人读代码会特别痛苦
}宏的用法之一:宏是可以发送参数的
1 |
|
- 宏可以辅助调试
在 Debug 模式下会有很多日志的输出,但是在 Release 模式下就不需要日志的输出了。正常的方法可能会删掉好多的输出日志的语句或者函数,但是用宏可以直接取消掉这些语句
利用宏中的 #if,#else,endif 来实现。如:
1 |
|
如果在 Debug (PR_DEBUG == 1) 模式下,则会打印日志,如果在 Release (PR_DEBUG == 0) 模式,则在预处理阶段就会把日志语句给删除掉。
利用 #if 0 和 #endif 删除一段宏.
1 |
|
续行符 \
普通代码行后面编译器自动判断续行的,宏定义则不行。
宏定义规定必须用一行完成:
1 |
这一行定义是没有问题的,但是这样代码很不容易被理解,如果写成:
1 |
|
# 和 ##
单个 #:
在 C 语言的宏中,# 的功能是将其后面的宏参数进行字符串化操作,简单说就是对他所引用的宏变量通过替换后再其左右各加上一个双引用。
例子:
1 |
|
两个 ##:## 被称为连接符,用来将两个 Token 链接成一个 Token. 注意这里的连接的对象是 Token 就行,而不一定是宏的变量。比如你要做一个菜单项命令名和函数指针组成的结构体的数组,并且希望在函数和菜单项命令名直接有直观的名字上的关系,那么下面的代码就非常实用
1 | struct command |
... 变参宏
... 在 C 语言中被称为变参宏
1 |
这里 ## 这个连接符充当的作用就是当 __VA_ARGS__ 为空的时候,消除前面的那个逗号。
一、变量和基本类型
1 对象
对象:具有某种数据类型的内存空间
- 基本上,当我们编写了一个类并且到了我们实际开始使用该类的时候,就需要实例化它 (除非它是完全静态的类)
- 实例化类有两种选择,这两种选择的区别是内存来自哪里,我们的对象实际上会创建在哪里。
- 应用程序会把内存分为两个主要部分:堆和栈。还有其他部分,比如源代码部分,此时它是机器码。
栈分配
1 | // 栈中创建 |
- 什么时候栈分配?几乎任何时候,因为在 C++ 中这是初始化对象最快的方式和最受管控的方式。
- 什么时候不栈分配? 如果创建的对象太大,或是需要显示地控制对象的生存期,那就需要堆上创建 。
堆分配
1 | // 堆中创建 |
- 当我们调用 new Entity 时,实际发生的就是我们在堆上分配了内存,我们调用了构造函数,然后这个 new Entity 实际上会返回一个 Entity 指针,它返回了这个 entity 在堆上被分配的内存地址,这就是为什么我们要声明成 Entity * 类型。
- 如果你使用了 new 关键字,那你就要用 delete 来进行清理。
new操作符
- new 的主要目的是分配内存,具体来说就是在堆上分配内存。
- 如果你用 new 和 **
[]来分配数组,那么也用delete[]。 - new 主要就是找到一个满足我们需求的足够大的内存块,然后返回一个指向那个内存地址的指针。
1 | int* a = new int; //这就是一个在堆上分配的4字节的整数,这个a存储的就是他的内存地址. |
- 在 new 类时,该关键字做了两件事
- 分配内存
- 调用构造函数
1 | Entity* e = new Entity();//1.分配内存 2.调用构造函数 |
- new 是一个操作符,就像加、减、等于一样。它是一个操作符,这意味着你可以重载这个操作符,并改变它的行为。
- 通常调用 new 会调用隐藏在里面的 C 函数 malloc,但是 malloc 仅仅只是分配内存然后给我们一个指向那个内存的指针,而 new 不但分配内存,还会调用构造函数。同样,delete 则会调用 destructor 析构函数。
- new 支持一种叫 placement new 的用法,这决定了他的内存来自哪里, 所以你并没有真正的分配内存。在这种情况下,你只需要调用构造函数,并在一个特定的内存地址中初始化你的 Entity,可以通过 new() 然后指定内存地址,例如:
1 | int* b = new int[50]; |
2 变量
初始化
区分初始化和赋值:
- 初始化不是赋值,初始化的含义是创建变量时赋予其一个初始值,而赋值的含义是把已创建对象的当前值擦除,而以一个新值来替代。
- 只有对象被创建才会出现初始化,而赋值操作并不应用于对象的创建过程中。
- 构造函数体中进行的是赋值(下图首先执行默认构造函数为变量设置初始值,然后在对他们赋予新值。)
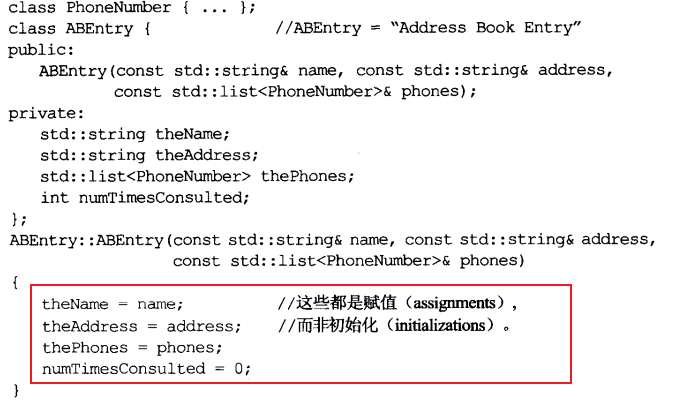
- C++规定对象的成员函数的初始化动作发生在进入构造函数本体之前。一个比较好的写法是在构造函数成员初始化列表中列出所有成员变量。

只需要调用一次 copy 构造,通常效率更高(对于内置类型,初始化和赋值成本相同)
区分初始化类型
- 拷贝初始化: 使用等号
=(赋值运算符)初始化变量 - 直接初始化: 不使用等号,使用
() - 列表初始化:使用
{}
- 拷贝初始化: 使用等号
区分拷贝构造函数和拷贝赋值运算符运算符:[[#拷贝构造和拷贝赋值的区别]]
1 | TestClass obj1(10,'.') //直接初始化, 调用构造函数 |
注:obj2 与 obj3 的创建所调用的函数是一样的,调用复制函数的原因却有所不同。因为直接初始化是根据参数来调用构造函数的,obj2 是根据括号中的参数(一个本类的对象),来直接确定为调用拷贝构造函数,这跟函数重载时,会根据函数调用时的参数来调用相应的函数是一个道理;
而对于 obj3 则不同,它的调用并不是像 obj2 时那样是根据参数来确定要调用拷贝构造函数的,它只是因为初始化必然要调用复制构造函数而已。它理应要创建一个临时对象,但只是这个对象却已经存在,所以就省去了这一步,然后直接调用拷贝构造函数,因为拷贝初始化必然要调用拷贝构造函数,所以 obj3 的创建仍是拷贝初始化。
初始化方式的选择
初始值只有一个时,使用直接初始化 或拷贝初始化都行。如果初始化多个值,一般只使用直接初始化。如果非要用拷贝初始化的方式,就要显式创建一个临时对象用于拷贝。
1
string str = string(10,'c');
如果提供的是一个【C++11】类内初始值,则只能使用拷贝初始化或使用花括号的形式初始化,不能使用圆括号。
如果提供的是初始元素值的列表,则只能把初始值都放在花括号里进行列表初始化,而不能放在圆括号里。
1
2vector<string> v1{“a”, "an", "the"}; //正确的列表初始化
vector<string> v1(“a”, "an", "the"); //错误
列表初始化
【C++11】使用花括号进行列表初始化
当用于内置类型的变量时,花括号初始化形式有一个重要特点:如果我们使用列表初始化且初始值存在丢失信息的风险,则编译器将报错
1 | long double ld = 3.1415926536; |
默认初始化
- 内置变量(包括内置变量的数组类型)默认初始化值由定义的位置决定:定义于函数体外的变量被初始化为 0,定义在函数体内部的内置变量将不被初始化,其值是未定义的(如果试图拷贝或访问会引发错误)。
- const 变量规定初始化必须有初始值,否则编译器错误
- static 变量(包括 static 数组)默认初始化为 0。
- 类、结构体的默认初始化由其构造函数决定
声明和定义
C++支持分离式编译机制,该机制允许将程序分割为若干个文件,每个文件可被独立编译。为了支持分离式编译,C++将声明和定义区分开来,声明使得名字未程序所知,一个文件如果想用别处定义的名字就必须包含对这个名字的声明,而定义负责创建与名字关联的实体。
变量、函数能且只能被定义一次,但是可以多次被声明。
- 函数声明:这个符号、这个函数是存在的。
- 函数定义:这个函数到底是什么。
- 变量声明:告诉编译器变量的名称和类型,不分配内存,不赋初始值
- 变量定义:为变量分配内存,为变量赋初值
如果想声明一个变量而非定义它,就在变量名前加关键字 extern,且不要显式初始化变量:
1 | extern int a; //只声明不定义 |
函数声明(又称函数原型)建议放在头文件中
extern 关键字
#extern
extern 可以置于变量声明或者函数声明前,以标示变量或者函数的定义在别的文件中,编译器遇到此变量和函数时会在其他文件中寻找其定义。
通过为变量和函数添加 extern 声明,可以让编译器把“寻找定义”这件事情推迟到链接阶段,而不会在编译阶段报“没有定义”的错误。
- 声明函数或全局变量的作用范围,其声明的函数和变量可以在本文件或其他文件中使用。
- extern “C”:兼容 C 语言,详情 [[#extern “C”]]
- C++ 中的函数声明默认被隐式的
extern关键字修饰
使用在其它文件中定义的全局变量/函数
“用到未被定义的变量/函数”这种情况一般出现在使用在其它文件中定义的变量/函数时。
使用场景:需要在 a.cpp 文件中使用在 b.cpp 中定义的全局变量/函数:
一般而言,C++全局变量的作用范围仅限于当前的文件,但同时 C++也支持分离式编译,允许将程序分割为若干个文件被独立编译。在一个文件中定义了变量和函数,在其他文件中要使用它们,可以有两种方式:
- 使用头文件,然后声明它们,然后其他文件去包含头文件
- 使用 extern,引用不在同一个文件中的变量或者函数。
1 |
|
1 |
|
在 C++中我们通常在头文件中声明变量和函数,我们可以将上述 A.cpp 文件中的声明移动到A.h 头文件中,并在 A.cpp 中 include 该头文件。
1 |
|
1 |
|
注意此时变量 i 和函数 func 已经在 B.cpp 中定义。其他任何地方不能重复定义。
const 变量多文件编程
C++ const常量在多文件编程中的3种用法 - 朴素贝叶斯 - 博客园 (cnblogs.com)
已知:
![[#const 变量]]
那么如何让 const 变量在其他文件使用?
由于 const 变量无法分离声明和定义,最简单的方法是将 const 定义在头文件中,其他 cpp 文件包含即可,但这违反了多文件编程的规定:在头文件中声明,在 cpp 文件中定义。
**有些情况下我们想要只在一个文件中定义 const,而在其他多个文件中声明并使用它,要使 const 变量能够在其他的文件中访问,必须地指定它为 extern。(将 const 改为外部链接)
1 |
|
1 |
|
extern “C”
告诉编译器按着 C 的函数命名规则去翻译指定的C++函数,以此兼容 C 语言。
如果不用 extern C,由于 C++ 和 C 语言在编译和链接时使用的命名规则不同,这会导致 C++ 代码无法调用 C 语言编写的函数或变量(链接时找不到符号)。
简单解释一下什么是函数的命名规则:对于 C++ 语言,由于需要支持重载,所以一个函数的链接名(Linkage Name)是由函数的名称、参数类型和返回值类型等信息组成的,用于在编译和链接时唯一标识该函数。
函数的链接名的生成规则在不同的编译器和操作系统上可能有所不同,一般是由编译器自动处理,不需要手动指定。
而 C 语言的链接函数名规则又和上面三个 C++ 不一样,通过在 C++ 代码中使用 extern “C” 关键字,可以将 C++ 编译器的命名规则转换为 C 语言的命名规则,从而使得 C++ 代码可以调用 C 语言的函数或变量。
extern “C” 的语法格式如下:
1 | // C 语言代码:test.c |
需要注意 extern “C” 关键字只对函数的名称和调用约定起作用,对于函数的参数类型和返回值类型没有影响。
所以,在使用 extern “C” 声明函数时,需要保证函数的参数类型和返回值类型与 C 语言的定义相同,否则可能会导致编译错误或运行时错误。
优点
extern 关键字在 C++ 中有几个优点,尤其在多文件项目中使用时:
- 避免重复定义: 当在多个源文件中需要共享全局变量或函数时,
extern关键字帮助避免了重复定义的问题。通过在头文件中声明并在一个源文件中定义,其他源文件可以通过extern关键字访问而不会导致重复定义错误。 - 提高可维护性: 使用
extern显式声明全局变量或函数,可以提高代码的可维护性。通过头文件的声明,程序员可以清晰地了解哪些变量和函数是在其他文件中定义的,这有助于代码的理解和维护。 - 分离接口和实现:
extern关键字有助于分离接口和实现。头文件中包含的声明提供了对外部功能的接口,而实际定义则可以隐藏在实现文件中,这符合良好的软件设计原则。 - 支持模块化设计: 在大型项目中,使用
extern可以支持模块化设计。模块化设计将代码分割成小的、独立的模块,每个模块可以在单独的源文件中进行定义,而extern允许这些模块之间共享数据和功能。
总体来说,extern 关键字有助于管理和组织多文件项目,提高代码的可读性和可维护性。
3 类型
指针
对计算机来说内存就是一切。x86 即 32 位地址为 32 位(8 位 16 进制数,4 * 8 = 32),那么对应指针就是 4 字节;x64 则为 64 位地址(16 位 16 进制数),则对应指针 8 字节。
- 指针是一个存储变量内存首地址的整数,指针自身也是一个变量也有自己的内存地址,所以可以使用诸如
**、***等多级指针。 - 解引用时,编译器怎么知道该从首地址开始取多少个字节呢?
- 编译器会根据指针的所指元素的类型去判断应该取多少个字节。
1 | int main() |
指针的类型要和他所指向的对象严格匹配,有两种例外:
- 允许令一个指向常量的指针指向一个非常量对象
1
2double dval = 3.14; //dval不是常量
const double *ctpr = &dval; //正确,但是不能通过cptr改变dval的值 - 存在继承关系的类。我们可以将基类的指针或引用绑定到派生类对象上(动态多态)
[!command] 建议:初始化所有指针
使用未经初始化的指针是引发运行时错误的一大原因。和其他变量一样,访问未经初始化的指针所引发的后果也是无法预计的。通常这一行为将造成程序崩溃,而且一旦崩溃,要想定位到出错位置将是特别棘手的问题。
在大多数编译器环境下,如果使用了未经初始化的指针,则该指针所占内存空间的当前内容将被看作一个地址值。访问该指针,相当于去访问一个本不存在的位置上的本不存在的对象。糟糕的是,如果指针所占内存空间中恰好有内容,而这些内容又被当作了某个地址,我们就很难分清它到底是合法的还是非法的了。
因此建议初始化所有的指针,并且在可能的情况下,尽量等定义了对象之后再定义指向它的指针。如果实在不清楚指针应该指向何处,就把它初始化为nullptr或者0,这样程序就能检测并知道它没有指向任何具体的对象了。
引用
根本上,引用通常只是指针一种形式,只是在指针上的语法糖(Syntactic sugar)。
也可以理解成变量的别名
当我们使用术语“引用”时,通常指的是“左值引用”
1 | int main() |
- 引用必须被初始化,一旦定义了引用,就无法将其绑定到其他对象
- 引用本身不是对象,引用本身不占有内存空间(自身没有地址),所以不能定义引用的引用,也不能定义指向引用的指针(指针自身占有内存空间,所以存在对指针的引用)
- 引用只能绑定在对象上,而不能与字面值或某个表达式的计算结果绑定在一起
- 引用的类型要与之绑定的对象严格匹配,有两种例外情况:
- 在初始化常量引用时允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可(编译器内部进行自动转换)。允许为一个常量引用绑定非常量的对象、字面值,甚至是一个一般表达式
1
2
3
4
5int i = 42;
const int &r1 = i;
const int &r2 = 42;
const int &r3 = r1 * 2;
int &r4 = r1 * 2;
- 在初始化常量引用时允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可(编译器内部进行自动转换)。允许为一个常量引用绑定非常量的对象、字面值,甚至是一个一般表达式
编译器内部转换的过程
1 | double dval = 3.14; |
- 存在继承关系的类。我们可以将基类的指针或引用绑定到派生类对象上(动态多态)
const 关键字
#const
[!NOTE] 重点
- const 变量只能由常量引用或常量指针绑定,非 const 变量既可以由普通引用/指针绑定,也可以由常量引用/指针绑定。
- 顶层 const: 对象本身是 const 。底层 const:指针所指的对象或引用绑定的对象是一个常量
- [[#拷贝操作的区别]]
- 非 const 指针可以转换为 const 指针,反之不行
- 当用实参初始化形参时会忽略掉顶层 const。即当形参为
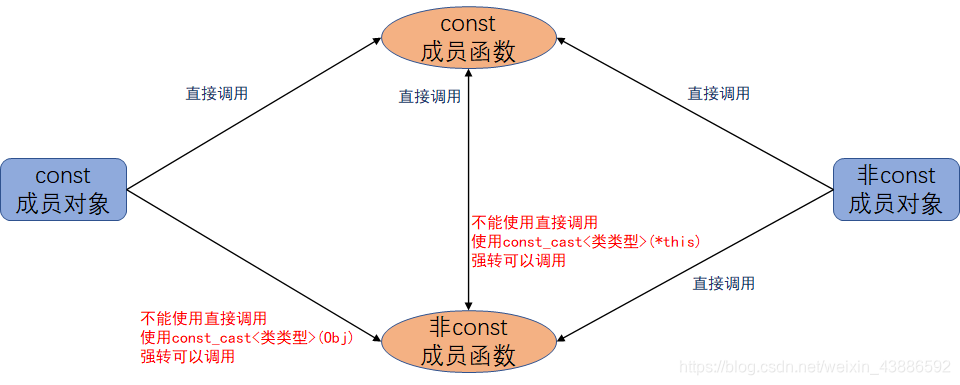
const int x时,传给它常量或非常量对象都是可以的。- 非 const 对象(成员函数)即可以调用 const 对象(成员函数),也可以调用非 const 对象(成员函数)
- const对象(成员函数)只能调用const对象(成员函数),想调用非const对象(成员函数)就需要强转
const 变量
const变量必须在声明时进行初始化。一旦被初始化,其值就不能再被修改。- 默认情况下,
const变量被设定为仅在文件内有效,多个文件中出现了同名的const变量时,等同于在不同文件中分别定义了独立的变量( const 默认为内部链接)。可以使用extern关键字修改为外部链接。
const 变量与常量的关系
首先我们要明确什么是常量:
- 常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面值常量。
- 常量可以是任何的基本数据类型,可分为整型数字、浮点数字、字符、字符串和布尔值。
- 常量就像是常规的变量,只不过常量的值在定义后不能进行修改。
也就是诸如123, 3.141596, true/false/, 'A'这些都是常量。常量是本来就存在的,我们也不能将通过修改将 1 作为 2 使用。
在 C++ 中,有四种简单的定义常量的方式:
- 使用
#define预处理器。 - 使用枚举
- 使用
const关键字。 - 使用
constexpr关键字
1 |
|
注意,我们不能把这里的 lenth 叫做常量,它只是一个只读变量!
使用 const 关键字只在编译期间保证该变量被使用时的不变性,无法保证运行期间的行为。 程序员直接修改 const 变量会得到一个编译错误,但是使用间接指针修改内存,只要符合语法则不会得到任何错误和警告。因为编译器无法得知你是有意还是无意的修改,但是既然定义成 const,那么程序员就不应当修改它,不然直接使用变量定义好了。
常量引用
指向常量的引用:常量对象只能用常量引用绑定!
const int &
1 | const int ci = 1024; |
[!comment] 建议
如果函数无须改变引用形参的值,最好将其声明为常量引用
常量指针
指向常量的指针:类似于常量引用,存放常量对象的地址必须使用常量指针。
const int(同 int const)
对于常量指针,const写在类型之前和类型之后是等价的:
1 | void f1(const Widget* pw); |
可以改变指针指向的地址, 不能再去修改指针指向的内容
1 | const int* a = new int; |
- 常量指针也没有规定所指的对象必须是一个常量,所谓指向常量的指针仅仅要求不能通过该指针改变对象的值,没有规定那个对象的值能不能通过其他途径改变。
指针常量
指针本身是常量
int* const
可以改变指针指向的内容, 不能再去修改指针指向的地址
1 | int* const a = new int; |
const int* const
指针和被指对象都是常量
既不可以改变指针指向的内容, 也不能再去修改指针指向的地址
顶层const、底层const
- 顶层 const:对象本身是个常量
- 底层 const:指针所指的对象或引用绑定的对象是一个常量
1 | int i = 0; |
拷贝操作的区别
顶层const和底层const在执行对象的拷贝操作时区别明显
顶层 const 不受影响:拷入或拷出的对象是否是常量没什么影响
1
2i = ci; //正确:拷贝ci的值,ci是一个顶层const
p2 = p3; //正确:p2 p3指向的类型相同,p3顶层const的部分不影响。底层 const 有限制:执行对象的的拷贝操作时,**拷入和拷出的对象必须具有相同的底层 const 资格,或两个对象的数据类型必须能够转换(非 const 指针可以转换为 const 指针 ,反之不行):
1 | int *p = p3; //错误:p3包含底层const的定义,而p没有 |
const形参和实参
和其他初始化过程一样,当用实参初始化形参时会忽略掉顶层const。即当形参有const时,传给它常量或非常量对象都是可以的。
1 | void fcn(const int i) { }; //因为忽略了const,所以这句等价于fcn(int i) |
常量表达式
常量表达式(const expression)是指值不会改变并且在编译期就能得到计算结果的表达式。
哪些是常量表达式? #常量表达式
- 字面值常量
- 整型和浮点型字面值:12、3.14等
- 字符和字符串字面值:’a’、”hello world!”等
- 转义序列:转义序列均以反斜线作为开始,如换行符\n等
- 指定字面值的类型:1E、3.15L等
- 布尔字面值:true、bool
- 指针字面值:nullptr
- 用常量表达式初始化的 const 对象
一个对象是不是常量表达式由他的数据类型和初始值共同决定
- 数据类型必须为 const
- 初始值可以在编译期获取
1
2
3
4const int a = 20; //a是
const int b = a + 1; //b是
int c = 27; //c不是,因为不是const int
const int d = get_size(); //d不是,因为初始值get_size()必须在运行时才能获取,不符合在编译过程中获取。
【C++11】constexpr 变量
#constexpr
将变量声明为 constexpr 类型,由编译器来验证变量的值是否是一个常量表达式。声明为 constexpr 的变量一定是一个常量,而且必须用常量表达式初始化
1 | constexpr int a = 20; |
声明constexpr的数据类型必须是“字面值类型”
字面值类型
- 算术类型(包含字符、整形数、布尔值、浮点数)
- 引用和指针(初始值必须是nullptr或0或存储与某个固定地址中的对象)
- [[#字面值常量类]]
- 枚举类型
【C++11】constexpr函数
不能使用普通函数作为constexpr变量的初始值,允许定义一种特殊的constexpr函数,这种函数可以在编译时计算器结果。
[!info] 定义遵循的约定
- 函数的返回类型及所有形参的类型都得是字面值类型
- 函数体中必须有且只有一条return语句
1 | constexpr int new_func() |
执行初始化任务时,编译器把对 constexpr 函数的调用替换成结果值,并且constexpr 函数被隐式指定为内联函数,得以在编译过程中展开。
constexpr函数体内可以包含其他语句,只要这些语句在运行时不执行任何操作就行,例如空语句、类型别名以及using声明。- 允许
constexpr函数返回值并非一个常量
[!bug] 把内联函数和constexpr函数放在头文件内
和其他函数不一样,内联函数和 constexpr 函数可以在程序中多次定义,不过对于某个给定的内联函数或者 constexpr 函数来说,它的多个定义必须完全一致,因此通常定义在头文件中。
constexpr指针
限定符constexpr只对指针有效,与指针所指的对象无关
1 | const int *a = nullptr; //指向整型常量的指针,底层const |
const成员函数
#const成员函数const 的第三种用法,他和变量没有关系,而是用在方法名的后面 ( 只有类才有这样的写法 )
本质上是将this指针类型改变为常量指针,因此不能修改类的成员变量。
![[#4 this指针]]
1 | class Entity |
然后有时我们就会写两个 Getx 版本,一个有 const 一个没有,然后上面面这个传 const Enity & 的方法就会调用 const 的 GetX 版本。
所以,我们把成员方法标记为 const 是因为如果我们真的有一些 const Entity 对象,我们可以调用 const 方法。如果没有 const 方法,那 const Entity & 对象就掉用不了该方法。
[!NOTE]
如果实际上没有修改类或者它们不应该修改类,总是标记你的方法为 const,否则在有常量引用或类似的情况下就用不了你的方法。
注意: const 对象只能调用 const 成员函数
mutable关键字
#mutable
mutable 意为“可变的”,与 constant(即 C++中的 const) 是相反词。
被 const 修饰的函数无法改变类成员变量,把类成员标记为 mutable(可变数据成员),意味着类中的 const 方法可以修改这个成员。即一个 const 成员函数可以改变一个可变数据成员的值。
需要注意的是:mutable 不能修饰 const 和 static 类型的变量。
1 | class Entity |
inline 内联函数
#inline
在 C++ 中,可以在定义函数时,在返回值类型前面加上 inline 关键字。增加了 inline 关键字的函数称为“内联函数”。
内联函数和普通函数的区别在于:当编译器处理调用内联函数的语句时,不会将该语句编译成函数调用的指令,而是直接将整个函数体的代码插人调用语句处,就像整个函数体在调用处被重写了一遍一样。
有了内联函数,就能像调用一个函数那样方便地重复使用一段代码,而不需要付出执行函数调用的额外开销。很显然,使用内联函数会使最终可执行程序的体积增加。以时间换取空间,或增加空间消耗来节省时间,这是计算机学科中常用的方法。
- 内联函数中的代码应该只是很简单、执行很快的几条语句。如果一个函数较为复杂,它执行的时间可能上万倍于函数调用的额外开销,那么将其作为内联函数处理的结果是付出让代码体积增加不少的代价,却只使速度提高了万分之一,这显然是不划算的。
- **另外,需要注意的是,调用内联函数的语句前必须已经出现内联函数的定义(即整个函数体),而不能只出现内联函数的声明。
- 有时函数看上去很简单,例如只有一个包含一两条语句的循环,但该循环的执行次数可能很多,要消耗大量时间,那么这种情况也不适合将其实现为内联函数。
[!warning]
注意将函数定义为 inline 对编译器来说只是一个建议,编译器可以选择忽略该建议。例如递归函数的内联通常会被编译器忽略,因为编译器无法预知递归深度,且会造成代码膨胀。
⭐定义在类内部的成员函数是默认 inline 的
1 | class A |
如果在类中未给出成员函数定义,而又想内联该函数的话,那在类外要加上 inline,否则就认为不是内联的。
将成员函数的定义体放在类声明之中虽然能带来书写上的方便,但不是一种良好的编程风格,上例应该改成:
1 | // a.cpp |
总结:加上 inline 的函数在调用时和普通函数不同,相当于把这段函数展开后复制到执行语句前,减少了时间上的开销,增大了空间开销。C++ 用 inline 关键字较好地解决了函数调用开销的问题。
【C++11】using类型别名
1 | typedef int zhengxing; //zhengxing是int的类型别名 |
【C++11】auto类型说明符
让编译器通过初始值推算变量类型,所以auto定义的变量必须有初始值
在函数返回值 / 范围 for 循环 等情况中使用 auto 时,有 5 种用法
auto:拷贝auto&:左值引用,只能接左值(和常量右值)auto&&:万能引用,能接左值和右值const auto&:const 万能引用,能接左值和右值const auto&&:常量右值引用,只能接右值
很多人直接就写 auto&&,但尽量分场景使用
auto:用于你想修改右值的情形auto&:用于你想修改左值的情形auto&&:用于泛型编程中的转发const auto&:用于只读const auto&&:基本没用,基本可被const auto&替代(比const auto&多一个语义:一定得是右值。然而这没什么用,因为你都不对其进行修改,是左还是右没什么影响)
看下边的例子
1 | vector<ElementType> arr; |
也就是说,4 种情形后边代表的语义是不一样的
比如明明不需要修改值的场合却用了 auto&&赋予了修改权限
所以一般情况下,我默认选择的是 const auto&,如果发现需要修改,再选择 auto&或auto(函数返回值如果是右值,是不用标记为 && 的,并且赋值处也不需要写上 &&,编译器会把这个部分优化掉)
在泛型编程的转发情况中,选择 auto&&(非转发情况就跟上边的一样)
auto&& 还有一种特殊情况,就是需要区分是左值引用还是右值引用的情形(这属于超级高级的优化了)
1 | auto&& result = foo(); |
类型别名
除auto之外类型名过长的时候也可以使用 using 或 typedef 方法:
1 | using DeviceMap = std::unordered_map<std::string, std::vector<Device*>>; |
【C++11】decltype类型指示符
#decltype
decl/type:declare type(声明类型)
作用:并返回操作数的数据类型
从表达式的类型推断出要定义的变量的类型,但是不用该表达式的值初始化变量。
1 | decltype(func()) sum = x; //sum的类型就是函数func()的返回类型 |
如果decltype使用的表达式是一个变量,则返回该变量的类型
1 | const int a = 0, &b = a; |
如果decltype使用的表达式是不是一个变量,则返回表达式结果对应的类型。
1 | //decltype的结果可以是引用类型 |
[!bug] 多层括号
decltype((i))(注意是双层括号)的返回结果永远是引用,而decltype(i)的返回结果只有当i本身是引用时才是引用
枚举enum
#enum #枚举
- 枚举类型(enumeration )将一组整型常数组织在一起。
- 默认情况下,编译器设置第一个 枚举变量值为 0,下一个为 1,以此类推(也可以手动给每个枚举量赋值),且 未被初始化的枚举值的值默认将比其前面的枚举值大 1。 )
分类:
【C++11】限定作用域的枚举类型,默认成员类型位int
1
2
3
4//限定作用域的枚举类型
//关键字enum class + 枚举类型名 + {枚举成员};
enum class color{red, yellow, green};
enum struct color{red, yellow, green}; //等价不限定作用域的枚举类型,无默认类型,分配一个足够容纳枚举值的类型
1
2
3
4
5//不限定作用域的枚举类型,省略关键字class或struct
enum color{red, yellow, green};
//未命名的、不限定作用域的枚举类型
enum {red = 1, yellow = 2, green = 3};
在限定作用域的枚举类型中,枚举成员的名字遵循常规的作用域准则,并且在枚举类型的作用域外是不可访问的。
与之相反,在不限定作用域的枚举类型中,枚举成员的作用域与枚举类型本身的作用域相同:
1 | enum color {red, yellow, green}; //不限定作用域的枚举类型 |
【C++11】指定enum的大小
只能指定不同大小的整型!
1 | enum example : unsigned char //将类型指定成unsigned char,枚举变量变成了8位整型,减少内存使用。 char型是大小为1字节(8位)的整型 |
【C++11】枚举类型的前置声明
提前声明 enum,前置声明必须指定其成员的类型
1 | //不限定作用域的枚举类型intValues的前置声明 |
枚举的定义和初始化
可利用新的枚举类型 example 声明这种类型的变量 example Dd,可以在定义枚举类型时定义枚举变量:
1 | //普通定义+初始化 |
与基本变量类型不同的地方是,在不进行强制转换的前提下,只能将定义的枚举量赋值给该种枚举的变量 (非绝对的,可用强制类型转换将其他类型值赋给枚举变量)
1 | Dd = Bb; //ok |
枚举量可赋给非枚举变量
1 | int a = Aa; //ok.枚举量是符号常量,赋值时编译器会自动把枚举量转换为int类型。 |
对于枚举,只定义了赋值运算符,没有为枚举定义算术运算 ,但能参与其他类型变量的运算
1 | Aa++; //非法! |
可以通过强制转换将其他类型值赋给枚举变量
1 | Dd = example(2); |
枚举应用
枚举和 switch 是最好的搭档:
1 | enum enumType{ |
位域
类可以将其(非static)成员定义为位域(bit-field), 位域的类型必须是整型或枚举类型(通常声明为unsigned int)。
位域的声明形式是在成员名字之后紧跟一个冒号以及一个常量表达式,该表达式用于指定成员所占的二进制位数:
1 | struct <位域结构名> |
位域,就是把一个字节中的二进制位划分为不同的区域,并说明每个区域的位数。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
有些信息在存储时,并不需要占用一个完整的字节,而只需要占一个或几个二进制位。例如在存放一个开关量时,只有 0 和 1 两种状态,只需要用一位二进制位即可。这样可以节省内存
ue 中通常用位域表示 bool,字段后面都加了 :1,连续八个这种类型的变量才占一个字节,而一个 bool 就要占一字节。
1 | uint32 bPending: 1 |
注意事项:
一个位域必须存储在同一个字节中,不能跨字节存储。如一个字节所剩空间不能存储下一个位域的时候,应从下一个字节开始存储。也可以有意使某个位域从下一单元开始,如:
1
2
3
4
5
6
7struct Demo
{
int a : 4;
int : 0;//空域
int b : 6;//从第二个字节开始存放
};
//在这个位域定义中,a占第一个字节的4bit,这个字节的另4bit填0表示不使用,b从第二个字节开始,占4bit。由于位域不允许跨两个字节,因此位域的长度不能大于一个字节的长度,也就是说位域的不能超过8bit;
位域可以无位域名,这时它只用作填充或调整位置。无名的位域是不能使用的。例如:
二、字符串和数组
数组
- C++ 数组就是表示一堆的变量组成的集合,一般是一行相同类型的变量。
初始化数组
1 | int a[] = {0,1,2,} |
[!bug] 不允许拷贝和赋值
不能将数组的内容拷贝给其他数组作为其初始值,也不能用数组为其他数组赋值
1 | int a[] = {0,1,2}; |
数组的特殊性
字符数组:用字符串字面值对数组初始化,使用这种方式时注意字符串字面值的结尾处还有一个’\0’空字符,这个空字符也被拷贝到字符数组中去。
1 | const char a[6] = “abcdef”; //错误,没有空间存放空字符,数组大小至少为7 |
直接使用数组名字时,编译器自动将其转换为指向数组首元素的指针。
1 | string nums[] = {"one","two"."three"}; |
当使用decltype关键字时,转换不会发生:
1 | //返回的仍是数组类型 |
数组的下标是 size_t 无符号类型,定义在 cstddef 头文件中,内置的下标运算符所用的索引值是有符号类型,可以处理负数下标,只是我们用负数作为下标的情况比较少。
而标准库类型限定使用下标必须是无符号类型
【C++11】标准库函数begin和end
数组的指针也是迭代器。数组的begin和end函数与容器中的begin和end成员函数类似,但数组不是类,所以这里的begin和end不是成员函数,直接调用即可
1 | int ia[] = {1,2,3,4,5}; |
两个指针相减的结果是一种名为ptrdiff_t的带符号类型。
栈数组和堆数组
- 不能把栈上分配的数组(字符串)作为返回值,除非你传入的参数是一个内存地址。
- 如果你想返回的是在函数内新创建的数组,那你就要用 new 关键字来创建。
- 栈数组
int example[5];堆数组int* another = new int[5];
1 | int main() |
上述的两个数组在内存上看都是一样的,元素都是 5 个 2;
那为什么要使用 new 关键字来动态分配,而不是在栈上创建它们呢?最大的原因是因为生存期, 因为 new 分配的内存,会一直存在,直到你手动删除它。
如果你有个函数要返回新创建的数组,那么你必须要使用 new 来分配,除非你传入的参数是一个内存地址。
字符串
#char
- 字符型变量用于显示单个字符
- 字符型变量并不是把字符本身放到内存中存储,而是将对应的ASCII编码放入到存储单元
1 | int main() { |
c++中的string是字符串类,const char * 是字符串常量指针。
c_str()
虽然 C++ 提供了 string 类来替代C语言中的字符串,但是在实际编程中,有时候必须要使用C风格的字符串(例如打开文件时的路径),为此,string 类为我们提供了一个转换函数 c_str(),该函数能够将 string 字符串转换为C风格的字符串,并返回该字符串的 const 指针(const char*)。请看下面的代码:
1 | //为了使用C语言中的 fopen() 函数打开文件,必须将 string 字符串转换为C风格的字符串。 |
C++ 字符串字面量
- 字符串字面量就是双引号中的内容。
- 字符串字面量是存储在内存的只读部分的,不可对只读内存进行写操作。
- C++11 以后,默认为
const char*, 否则会报错。
1 | char* name = "cherno";//Error! |
- 从 C++11 开始,有些编译器比如 Clang,实际上只允许你编译
const char*, 如果你想从一个字符串字面量编译 char, 你必须手动将他转换成char*
1 | char* name = (char*)"cherno"; //Ok! |
- 别的一些字符串
基本上,char 是一个字节的字符,char16_t 是两个字节的 16 个比特的字符(utf16),char32_t 是 32 比特 4 字节的字符(utf32),const char 就是 utf8. 那么 wchar_t 也是两个字节,和 char16_t 的区别是什么呢?事实上宽字符的大小,实际上是由编译器决定的,可能是一个字节也可能是两个字节也可能是 4 个字节,实际应用中通常不是 2 个就是 4 个(Windows 是 2 个字节,Linux 是 4 个字节),所以这是一个变动的值。如果要两个字节就用 char16_t,它总是 16 个比特的。
1 | const char* name = "lk"; |
string_literals
1 |
|
string_literals 中定义了很多方便的东西,这里字符串字面量末尾加 s,可以看到实际上是一个操作符函数,它返回标准字符串对象(std::string)
然后我们就还能方便地这样写等等:
1 | std::wstring name0 = L"hbh"s + L" hello"; |
string_literals 也可以忽略转义字符
1 |
|
printf
用于格式化输出字符串
1 | printf("The number is: %d", num); |
常用%c char 字符%d 有符号十进制整数(d 代表了”decimal”十进制)%f 浮点数、十进制记数法(默认输出六位小数,使用 %.2f 指定为指定为两位小数)%s 字符串
其他:%a 浮点数、十六进制 bai 数字和 p-记法(C99)%e 浮点数、e-记数法%g 根据数值不同自动选择%f 或%e.%i 有符号十进制数(与%d 相同)%o 无符号八进制整数%p 指针%u 无符号十进制整数%x 使用十六进制数字 0f 的无符号十六进制整数%% 打印一个百分号
等等
使用案例:
输出整数
1 | printf("%d",-12)//有符号 |
输出小数(默认输出六位小数)
1 | printf("%f",12.3) |
输出字符
1 | printf("%s","ww") |
按照指定位数输出整数
1 | printf("%2d\n",1234);//指定位数小于实际位数,按照实际位数输出 |
按照指定位数输出小数
1 | printf("%1.3f\n",123.456);//整数部分指定位数小于实际位数,按照实际位数输出 |
添加填充
1 | printf("%08d",123);//默认以0填充 |
三、表达式
1 左值与右值 (lvalue and rvalue)
[!NOTE] 简单总结
当一个对象被用作左值的时候,用的是对象的地址(在内存中的位置)
当一个对象被用作右值的时候,用的是对象的值(内容)
左值有地址和值,可以出现在赋值运算符左边或者右边。
右值只有临时值,无地址,只能在右边
左值:
有地址 数值 有存储空间的值,往往长期存在; 左值是由某种存储支持的变量;左值有地址和值,可以出现在赋值运算符左边或者右边。左值引用:
- 非 const 的左值引用只接受左值
- const 左值引用。兼容右值和左值。
为什么?
右值:
是临时量,无地址(或者说有地址但访问不到,它只是一个临时量) 没有存储空间的短暂存在的值 。右值引用:
右值引用只能引用右值,不能绑定到左值,可以通过 const 引用或者右值引用延长右值的生命周期在给函数形参列表传参时,有四种情况:
1 |
|
右值引用
常规引用称为”左值引用“
”右值引用“就是必须绑定到右值的引用,通过&&获得。
”右值引用“只能绑定到右值(右值是临时的,没有地址),因此可以自由的将右值引用的资源“移动” 到另一个对象中。
1 | int i = 42; |
右值引用的优势:
如果我们知道传入的是一个临时对象的话,那么我们就不需要担心它们是否活着,是否完整,是否拷贝。我们可以简单地偷它的资源,给到特定的对象,或者其他地方使用它们。因为我们知道它是暂时的,它不会存在很长时间。而如果如上使用 const string& str,虽然可以兼容右值,但是却不能从这个字符串中窃取任何东西!因为这个 str 可能会在很多函数中使用,不可乱修改!(所以才加了 const)
2 递增递减运算符
[!comment] 建议:除非必须,否则不用递增递减运算符的后置版本
前置版本避免了不必要的工作,它把值加1后直接返回了改变了的运算对象。后置版本需要将原始值存储下来以便于返回这个未修改的内容,如果我们不需要修改前的值,那么后置版本的操作就是一种浪费。
现代编译器中它门的性能差距非常小,可以忽略不计。
在 C++ 中,前置递增运算符(++i)和后置递增运算符(i++)是用于增加变量值的运算符。它们的区别在于它们返回的值和执行的顺序。
前置递增运算符(++i):
- 先将变量递增,然后返回递增后的值。
- 例如,
int i = 5; int a = ++i;,a的值为 6,i的值也为 6。
后置递增运算符(i++):
- 先返回变量原始值,然后再将变量递增。
- 例如,
int i = 5; int a = i++;,a的值为 5,而i的值会在语句结束之后变为 6。
需要注意的是,在表达式中使用这两种递增运算符时可以产生不同的结果。例如:
1 | int i = 5; |
3 箭头操作符->
1. 特点:
- 箭头运算符必须是类的成员。
- 一般将箭头运算符定义成了 const 成员,这是因为与递增和递减运算符不一样,获取一个元素并不会改变类对象的状态。
2. 对箭头运算符返回值的限定
箭头运算符的重载永远不能丢掉成员访问这个最基本的含义。当我们重载箭头时,可以改变的是箭头从哪个对象当中获取成员,而箭头获取成员这一事实则永远不变。
对于形如 point->mem 的表达式来说,point 必须是指向类对象的指针或者是一个重载了 operator-> 的类的对象。 根据 point 类型的不同,point->mem 分别等价于
1 | point->mem; |
重载的箭头运算符必须返回类的指针或者自定义了箭头运算符的某个类的对象。
3. 三种应用场景
可用于指针调用成员:p->x 等价于 (* p).x (最常见的情况)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Entity
{
public:
int x;
};
int main()
{
Entity e;
Entity* ptr = &e;
//两种方式等价
(*ptr).x=2;
ptr->x = 2;
}重载箭头操作符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class Entity
{
private:
int x;
public:
void Print()
{
std::cout << "Hello!" << std::endl;
}
};
class ScopedPtr
{
private:
Entity* m_Ptr;
public:
ScopedPtr(Entity* ptr): m_Ptr(ptr) { }
~ScopedPtr()
{
delete m_Ptr;
}
Entity* operator->() //重载操作符
{
return m_Ptr;
}
};
int main() {
{
ScopedPtr entity = new Entity();
entity->Print();
}
std::cin.get();
}
进一步, 可以写为 const 版本的:
1 |
|
- 可用于计算成员变量的 offset:
引自 B 站评论:
因为 “指针 -> 属性” 访问属性的方法实际上是通过把指针的值和属性的偏移量相加,得到属性的内存地址进而实现访问。 而把指针设为 nullptr(0),然后 -> 属性就等于 0 + 属性偏移量。编译器能知道你指定属性的偏移量是因为你把 nullptr 转换为类指针,而这个类的结构你已经写出来了 (float x,y,z),float4 字节,所以它在编译的时候就知道偏移量 (0,4,8),所以无关对象是否创建
1 | struct vec2 |
4 sizeof 运算符
返回一条表达式或一个类型所占的字节数,结果是 size_t 类型的常量表达式。
1 | // 两种形式: |
5 强制类型转换
c 风格强制类型转换
直接用括号进行转换,可以实现 cast 相同功能,缺点是表现形式不清晰,不容易 debug。
- 形式一:C 语言风格的转型语法:
1 | (T)expression //将expression转换为T类型 |
- 形式二: 函数风格的转型:
1 | T(expression) ////将expression转换为T类型 |
上面两种形式并无差别,只是小括号摆放位置不同。
static_cast
static_cast 用于进行比较 “自然” 和低风险的转换
- 基本类型如整型和浮点型、字符型之间的互相转换。
- 指针/引用类型之间的转换,不执行运行时类型检查,可能不安全。
任何具有明确定义的类型转换,只要不包含底层 const,都可以使用 static_cast。
1 | double dPi = 3.1415926; |
reinterpret_cast
reinterpret:重新解释
reinterpret_cast 用于进行各种不同类型的指针之间强制转换。
通常为运算对象的位模式提供较低层次上的重新解释。危险,不推荐。
1 | int *ip; |
const_cast
const_cast<T> 中的类型必须是指针、引用,用于去除指针或引用的 const 或 volatile 属性。
使用场景:const 对象(或 const 成员函数)调用非 const 成员函数,必须将 const 去掉才能调用。
1 | class MyClass { |
使用 const_cast 可能导致未定义的行为,因此应谨慎使用。
运行时类型识别
RTTI 即通过运行时类型识别,程序能够使用基类的指针或引用来检查着这些指针或引用所指的对象的实际派生类型。
C++ 是一种静态类型语言。在静态类型语言中,变量的类型在编译时确定,,不能在运行时更改。然而由于面向对象程序设计中多态性的要求,C++中的指针或引用(Reference)本身的类型,可能与它实际代表(指向或引用)的类型并不一致。有时我们需要将一个多态指针转换为其实际指向对象的类型,就需要知道运行时的类型信息,这就产生了运行时类型识别的要求。
运行时类型识别(run-time type identification,RTTI)由两个运算符实现:
- typeid运算符,用于返回表达式的类型
- dynamic_cast运算符,用于将基类的指针或引用安全地转换成派生类的指针或引用。
dynamic_cast
[!NOTE] 总结
- 子类向父类转换(向上转换)可以使用
static_cast或dynamic_cast。向上转换始终是安全的,没必要使用dynamic_cast,它会增加运行时的开销。我们通常使用隐式转换即可。- 父类向子类转换(向下转换)必须使用
dynamic_cast,且要保证父类有虚函数。
dynamic_cast运算符,用于将基类的指针或引用安全地转换成派生类的指针或引用, 如果转换失败会返回空指针(对于指针)或std::bad_cast异常(对于引用)。- 使用时需要保证是多态,即只能用于基类含有虚函数的类。
- 支持运行时类型识别。
适用于以下情况:我们想使用基类对象的指针或引用执行某个派生类操作并且该操作不是虚函数。
使用形式:
其中,type 必须是一个类类型,并且通常情况下该类型含有虚函数。
1 | dynamic cast<type*> (e) //e必须是一个有效的指针 |
在上面的所有形式中,e 的类型必须符合以下三个条件中的任意一个:
- e 的类型是目标 type 的公有派生类
- e 的类型是目标 type 的公有基类
- e 的类型就是目标 type 的类型。
如果符合,则类型转换可以成功。否则,转换失败。
1 |
|
[!NOTE]
可以对一个空指针执行 dynamic_cast,结果是所需类型的空指针
typeid运算符
typeid运算符允许向程序表达式提问:你的对象是什么类型?
1 | typeid(e) //e可以是任意表达式或类型的名字 |
typeid运算符可以作用于任意类型的表达式。和往常一样,顶层const被忽略,如果表达式是一个引用,则typeid返回该引用所引对象的类型。不过当typeid作用于数组或函数时,并不会执行向指针的标准类型转换。也就是说,如果我们对数组a执行typeid(a),则所得的结果是数组类型而非指针类型。
- 当运算对象不属于类类型或者是一个不包含任何虚函数的类时,typeid 运算符指示的是运算对象的静态类型。
- 而当运算对象是定义了至少一个虚函数的类的左值时,typeid 的结果直到运行时才会求得。
通常我们使用typeid比较两条表达式的类型是否相同,或者比较一条表达式的类型是否与指定类型相同:
1 | Derived *dp = new Derived; |
type_info 类
type_info 类的精确定义随着编译器的不同而略有差异。不过,C++标准规定 type_info 类必须定义在 typeinfo 头文件中,并且至少提供表 19.1 所列的操作。
除此之外,因为 type_info 类一般是作为一个基类出现,所以它还应该提供一个公有的虚析构函数。当编译器希望提供额外的类型信息时, 通常在 type_info 的派生类中完成。type_info 类没有默认构造函数,而且它的拷贝和移动构造函数以及赋值运算符都被定义成删除的。因此,我们无法定义或拷贝 type_info 类型的对象,也不能为 type_info 类型的对象赋值。创建 type_info 对象的唯一途径是使用 typeid 运算符。type_info 类的 name 成员函数返回一个 C 风格字符串,表示对象的类型名字。对于某种给定的类型来说,name 的返回值因编译器而异并且不一定与在程序中使用的名字一致。对于 name 返回值的唯一要求是,类型不同则返回的字符串必须有所区别。例如:
1 | int arr [10]; |
type_info 对象是在编译的时候决定其内容的,作为静态数据存在于最终生成的目标代码里。编译器会在静态存储空间里为这些 type_info 对象分配空间,并生成代码来初始化它们的内容。
类型转换函数(类型转换运算符)
又称类型转换运算符,使用类型转换函数可以将该类类型转换为其他类型。
用法:P514
一个类型转换函数必须是类的成员函数,他不能声明返回类型,形参列表也必须为空。类型转换函数通常是 const 函数。operator type () const
6 运算符优先级
从上到下优先级递减
四、控制流
switch
执行多条件分支语句
注意1:switch语句中表达式类型只能是整型或者字符型
注意2:case里如果没有break,那么程序会一直向下执行总结:与if语句比,对于多条件判断时,switch的结构清晰,执行效率高,缺点是switch不可以判断区间
1 | switch(表达式) |
1 | int main() |
for
1 | //语法形式 |
语句头多重定义
init-statement可以定义多个对象,但是只能由一条声明语句,因此,所有变量的基础类型必须相同。
1 | //init-statement定义了两个对象:i和sz |
省略语句头的某些部分
for语句头能省略掉init-statement、condition、expression中的任何一个(或全部)。
省略condition:等价于在条件部分写了一个true,所以循环体内必须有语句负责退出循环,否则将会无限循环。
省略expression:要求condition部分或者循环体必须有改变迭代变量的值。
1 | vector<int> v; |
【C++11】范围for
1 | //range for语法 |
1 | //遍历string对象中的每个字符 |
do while
与while的区别在于do…while会先执行一次循环语句,再判断循环条件。
1 | do |
break
终止离他最近的while、do while、for或swtich语句,并从这些语句之后的第一条语句开始执行。
break使用的时机:
- 出现在switch条件语句中,作用是 终止case 并跳出switch
- 出现在循环语句中,作用是跳出 当前 的循环语句
- 出现在嵌套循环中,跳出 最近的 内层循环语句
continue
终止最近的循环中的当前迭代,并立即开始下一次迭代。
五、函数
函数就是我们写的代码块,被设计为用来执行特定的任务。在 class 中这些代码块则被称为方法 method。
这里所说函数单独指类外的。
每次调用函数,编译器生成一个 call 指令(类外的,因此没有什么动态绑定,也暂时不考虑内联)。这基本上意义着,在一个运行的程序中,为了调用一个函数,我们需要创建一个堆栈结构,这意味着我们必须把像参数这样的东西推进堆栈。我们还需要一个叫做返回地址的东西压入堆栈。然后我们要做的是跳到二进制执行文件的不同部分,以便开始执行我们的函数指令。
为了将 push 进去的结果返回,然后我们得回去到最初调用函数之前。跳跃和执行这些都需要时间,所以它会减慢我们的程序。
而对于 main 函数,返回值是 int,并且只有 main 函数可以不 return——它会自动假设返回 0.(这是现代 C 和 C++ 的一个特性)
1 空形参列表
1 | //形参列表可以为空,下列两种方式等价 |
2 main 处理命令行选项
有时我们需要给main传递实参,一种常见的情况是用户通过设置一组选项来确定函数所要执行的操作。
例如,假定main函数位于可执行文件prog内,我们可以向程序传递下面的选项:
1 | prog -d -o ofile date0 |
这些命令通过两个(可选的)形参传递给main函数
1 | int main(int argc, char *argv[]) {......} |
当实参传递给main函数之后,argv的第一个元素指向程序的名字或者一个空字符串,接下里的元素依次传递命令行提供的是实参,最后一个指针之后的元素值保证为0
例子中,argc的值等于5,argv应该包含如下的C风格字符串:
1 | argv[0] = "prog"; //指向程序的名字或者一个空字符串 |
[!warning]
当使用 argv 中的实参时,一定要记得可选的实参从 argv[1]开始;argv[0]保证是程序的名字,而非用户输入
深入理解argc和argv
argc 是 argument count的缩写,表示传入main函数的参数个数;
argv 是 argument vector的缩写,表示传入main函数的参数序列或指针,并且第一个参数argv[0]一定是程序的名称,并且包含了程序所在的完整路径,所以确切的说需要我们输入的main函数的参数个数应该是argc-1个;
简单用法示例,新建工程键代码:
1 |
|
argv是指向指针的指针,main函数的第二个参数替换为 char** argv,两者是等价的。
在编译环境下按F5运行,输出如下: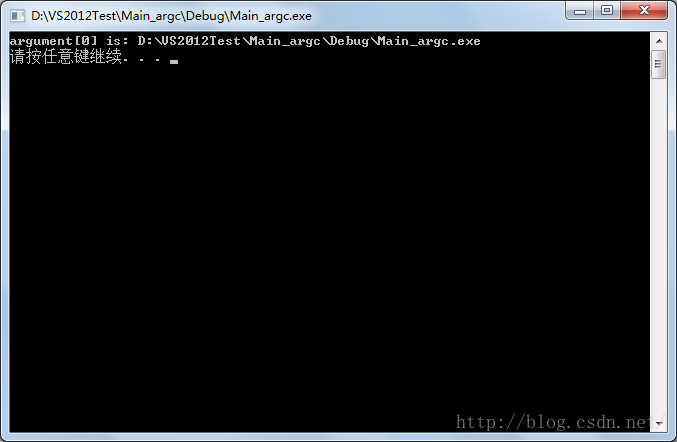
可见,在没有参数传入的情况下,保存程序名称的第一个变量argv[0]依然存在。
传参数给main函数有两种方法,第一种方式是在编译环境中设置,以vs2012为例,右击项目—>属性—>配置属性—>调试—>命令参数,在命令参数中输入,每个参数之间用空格隔开。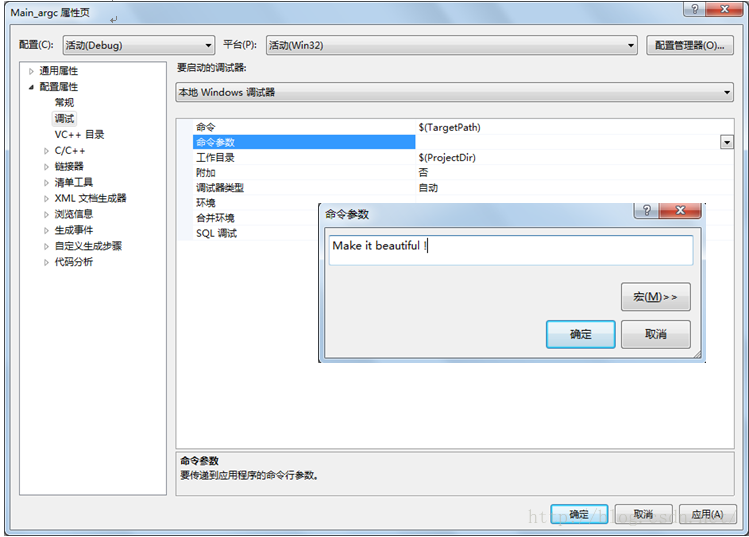
之后点击确定并应用,运行之后显示如下: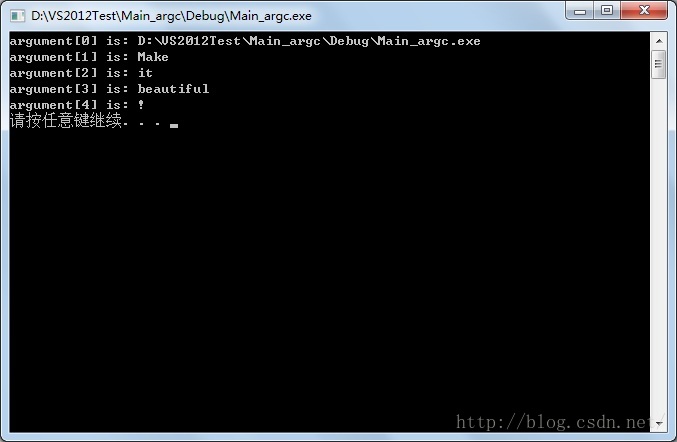
第二种方式也是经常会用到的方式是通过命令提示符传入。首先需要打开命令提示符窗口,点击开始菜单在“搜索程序和文件”里输入命令“cmd”或者直接按快捷键 Windows+R,在弹出的对话框里输入“cmd”即可打开命令提示符窗口:
打开命令提示符窗口后需要输入生成的exe文件所在的完整路径,一个简便的方法是把exe文件直接拖入提示符窗口即可,之后输入传入参数,以空格分隔,之后回车,显示如下: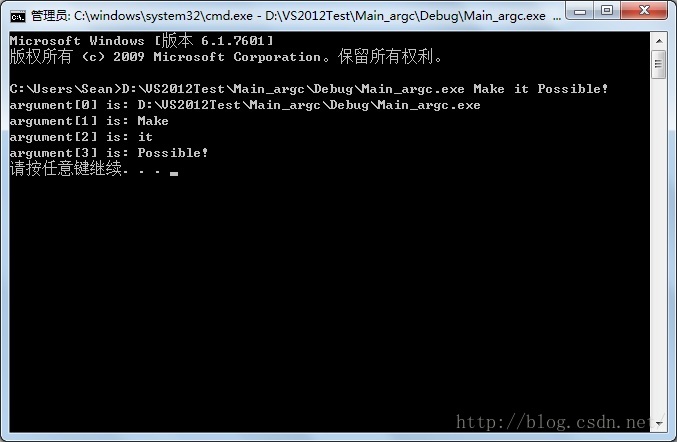
如果你坚持要手工输入完整路径的话,你会发现等你“Ctrl+C”路径后,在提示符窗口中按“Ctrl+V”却不能粘贴,这时候可以在窗口中右键单击一下试试,你会发现右键菜单里的粘贴功能还是有效的。
下一个例子演示使用opencv显示一幅图片:
1 |
|
注意读入的参数是argv[1],在命令提示符窗口运行: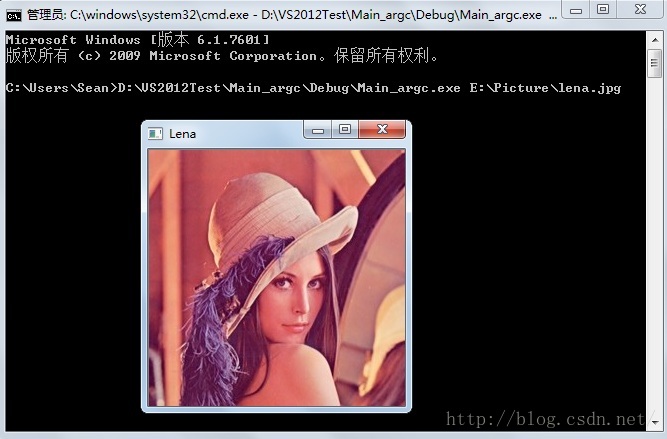
最后说明一下:一般编译器默认使用argc和argv两个名称作为main函数的参数,但这两个参数如此命名并不是必须的,你可以使用任何符合C++语言命名规范的变量名作为入参,效果是一样的:
1 |
|
3 【C++11】 含有可变形参的函数
编写处理不同数量形参的函数,C++11有两种方法:
- 如果所有实参类型相同,可以使用
initialize_list的标准库类型 - 如果实参类型不同,可以编写可变参数模板P618
还有一种特殊的形参类型(省略符 .....),可以用它传递可变数量的形参,这种功能一般只用于与 C 函数交互得接口程序。
initialize_list 初始化列表
如果函数的实参数量未知但是全部实参的类型相同,可以使用 initialize_list 类型的形参。initialize_list 是一种标准库类型,用于表示某种特定类型的值的数组。
initialize_list 对象中的元素永远是常量值
1 | //例子:输出错误信息 |
如果想向 initializer_list 形参中传递一个值的序列, 则必须把序列放在一对花括号内:
1 | // expected和actual是string对象 |
省略符形参
省略符形参是为了便于 C++程序访问某些特殊的 C 代码而设置的, 这些代码使用了名为 varargs 的 C 标准库功能。通常,省略符形参不应用于其他目的。你的 C 编译器文档会描述如何使用 varargs。
[!bug] Title
省略符形参应该仅仅用于 C 和 C++通用的类型。特别应该注意的是,大多数类类型的对象在传递给省略符形参时都无法正确拷贝。
省略符形参只能出现在形参列表的最后一个位置,它的形式无外乎以下两种:
1 | void foo (parm_list, ...); |
第一种形式指定了 foo 函数的部分形参的类型,对应于这些形参的实参将会执行正常的类型检查。省略符形参所对应的实参无须类型检查。在第一种形式中,形参声明后面的逗号是可选的。
4 【C++11】尾置返回类型
任何函数的定义都能使用尾置返回,但是这种形式对于返回类型比较复杂的函数最有效,比如返回类型是数组的指针或者数组的引用。
下面的例子是返回一个指向维度为10的数组指针的函数定义方法:
1 | int (*func(int i))[10] |
下面逐层理解上述例子的含义:
func(int i)表示调用函数时,需要一个int类型的参数;* func(int i)表示对调用func的结果执行解引用的操作;(* func(int i))[10]表示解引用之后得到一个维度为10的数组;int (* func(int i))[10]表示数组的数据类型为int;
若使用尾置返回类型,上述函数的定义可以写成:
尾置返回类型跟在形参列表后面并以一个 -> 符号开头。为了表示函数真正的返回类型跟在形参列表之后,我们在本应该出现返回类型的地方放置一个 auto:
1 | // func接受了一个int类型的实参,返回了一个指针,该指针指向一个含有10个整数的数组 |
因为我们把函数的返回类型放在了形参列表之后,所以我们可以很清晰地看到func函数返回的是一个指针,并且该指针指向了一个含有10个整数的数组。
尾置返回类型的另一个好处是我们可以在函数返回类型中使用函数形参相关的信息:
1 | template<typename Container, typename Index> //可以工作,但是需要改良 |
在 authAndAccess 函数中,我们使用 c 和 i 指定返回类型。如果我们按照传统语法把函数返回类型放在函数名称之前,c 和 i 就未被声明所以不能使用。
5 默认实参
- 局部变量不能作为默认实参
- 调用含有默认实参的函数时,可以包含该实参,也可以省略该实参
- 设计时尽量让不怎么使用默认值的参数出现在前面
1
2
3
4
5
6
7
8
9
10//函数具有默认实参
string screen(int height = 24, int width = 80, char background = ' ');
//函数调用时实参按位置解析,默认实参负责填补函数调用缺少的尾部实参
string window;
window = screen(); // 等价于screen(24, 80, ' ')
window = screen(66); // 等价于screen(66, 80, ' ')
window = screen(66,256); // 等价于screen(66, 256, ' ')
window = screen(66,256,'#'); // 等价于screen(66, 256, '#')
window = screen( , , "S") // 错误,只能从尾部填充
6 函数指针
#函数指针
1 | bool lengthCompare(const string &, const string &); |
[!NOTE] Title
(*pf)两端的括号必不可少,如果不写括号,则pf是一个返回值为bool指针类型的函数bool *pf(const string &, const stirng &);
使用函数指针
当把函数名作为一个值使用时,该函数自动转换成指针
1 | pf = lengthCompare; //pf指向lengthCompare函数 |
可以直接使用函数指针调用该函数,无须提前解引用
1 | bool b = pf("hello","world"); |
函数指针作为参数
函数指针可以作为一个参数传递给另一个函数。这时函数指针的使用就像普通的常量和变量一样。
当函数指针作为参数传递的时候,这时接收参数传递的函数通常需要根据这个指针调用这个函数。作为参数传递的函数指针通常表示 回调函数(Callback Functions)。
[!NOTE] 回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。
1 | typedef int (*FuncPtr)(int, int); |
为什么要首先使用函数指针
和数组类似,不能定义函数类型的形参,但是形参可以是指向函数的指针,这样就能将一个函数作为另一个函数的形参。
1 | void Print(int val) { |
优化:lambda
lambda 本质上是一个普通的函数,只是它不像普通函数这样声明,它是我们的代码在过程中生成的,用完即弃的函数,不算一个真正的函数,是匿名函数 。
格式:[] ({形参表}) {函数内容}
1 | void ForEach(const std::vector<int>& values, void(*function)(int)) { |
7【C++11】lambda 表达式
#lambda
lambada 即 λ 的读音
可以理解为一个临时函数,适用于那种只在一两处使用的简单操作。
如果一个需要多次使用的功能,最好还是用函数。
普通函数的不同:
- lambda可以定义在函数内部
- 可以忽略参数列表和返回类型,但必须包含捕获列表和函数体
- 当我们需要为一个lamba定义返回类型时,必须使用尾置返回类型。
- 不能有默认参数
[捕获列表](参数列表)->返回类型 {函数体}[capture list](parameter list)->return type { function body }
1 | //可以忽略参数列表和返回类型,但必须包含捕获列表和函数体 |
捕获列表
捕获列表 是一个 lambda 所在函数中定义的局部变量的列表(通常为空)
显式捕获:[name]显示列出所在函数的变量
隐式捕获:让编译器根据lambda体中的代码推断我们要使用哪些变量
注意 identifier_list 是个列表:可以指定多个显示捕获变量
[!NOTE] 捕获外部变量
lambda只有在其捕获列表中捕获一个它所在函数中的局部变量,才能在函数体中使用该变量。捕获列表只用于局部非static变量,lambda可以直接使用局部static变量和在它所在函数之外声明的名字。
1 | struct S2 |
事例:
1 |
|
结合 std:: function 捕获局部变量:
1 | //lambda可以使用外部(相对)的变量,而[]就是表示打算如何传递变量 |
可变lambda
默认情况下,对一个通过值捕获的变量,lambda 表达式中认为该变量是只读的,无法改变其值(引用捕获则可以改变)。如果我们希望能改变被值捕获的变量的值,就必须在函数体前加上关键字 mutable。
1 | int main() |
指定lambda返回类型
[!NOTE] lambda返回类型
如果lambda的函数体只有一个return语句,则返回类型从返回的表达式的类型推断。如果lambda的函数体有多个return语句,则要求所有return的表达式类型相同。
如果lambda的函数体没有return语句,则返回类型为void。
1 | //将序列中的负数都改为正数 |
底层实现
当我们定义一个 lambda 表达式后,编译器会自动生成一个类,在该类中对 () 运算符进行重载,实际 lambda 函数体的实现就是这个函数对象(仿函数)的 operator()的实现。
在调用 lambda 表达式时,参数列表和捕获列表的参数,最终都传递给了仿函数的 operator()。
8【C++11】 bind 参数绑定
#bind
如果 lambda 的捕获列表为空,通常可以用函数来代替它。但是,对于捕获局部变量的 lambda,用函数来替换它就不是那么容易了。
例如,我们用在 find_if 调用中的 lambda 比较一个 string 和一个给定大小。我们可以很容易地编写一个完成同样工作的函数:
1 | bool check_size (const string &s, string::size_type sz) |
但是,我们不能用这个函数作为 find_if 的一个参数。find_if 接受一个一元谓词,因此传递给 find_if 的可调用对象必须接受单一参数。假设传递给 find_if 的 lambda 使用捕获列表来保存 sz。为了用 check_size 来代替此 lambda,必须解决如何向 sz 形参传递一个参数的问题。
我们可以解决向 check_size 传递一个长度参数的问题,方法是使用一个新的名为 bind 的标准库函数,它定义在头文件 functional 中。
bind 函数
可以将 bind 函数看作一个通用的函数适配器,接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
1 | //调用bind的一般形式: |
newCallable本身是一个可调用对象arg_list是一个逗号分隔的参数列表,对应给定的callable的参数。- 即当我们调用
newCallable时,newCallable会调用callable, 并传递给它arg_list中的参数。
arg_list 中的参数可能包含形如 _n 的名字,其中 n 是一个整数。这些参数是“占位符”, 表示 newCallable 的参数,它们占据了传递给 newCallable 的参数的“位置”。
- 数值
n表示生成的可调用对象中参数的位置:_1为 newCallable 的第一个参数,_2为第二个参数,依此类推。 arg_list中使用占位符的位置需要我们传入参数,若使用给定值,则不用传参。_n都定义在std::placeholders命名空间:std::placeholders::_n
函数参数绑定
作为一个简单的例子,我们将使用 bind 生成一个调用 check_size 的对象,如下所示,它用一个定值作为其大小参数来调用 check_size:
1 | // check6是一个可调用对象,接受一个string类型的参数 |
此bind 调用只有一个占位符,表示check6只接受单一参数。占位符出现在arg_list 的第一个位置,表示 check6的此参数对应 check_size 的第一个参数。此参数是一个const string&。因此,调用check6必须传递给它一个string类型的参数,check6会将此参数传递给check_size。
1 | string s = "hello"; |
使用 bind,我们可以将原来基于 lambda 的 find_if 调用:
1 | auto wc= find_if(words.begin(), words.end (),[sz] (const string &a) |
替换为如下使用 check_size 的版本:
1 | auto wc = find_if(words.begin(), words.end( ),bind(check_size,_1, sz)); |
此 bind 调用生成一个可调用对象,将 check_size 的第二个参数绑定到 sz 的值。当 find_if 对 words 中的 string 调用这个对象时,这些对象会调用 check_size,将给定的 string 和 sz 传递给它。因此,find_if 可以有效地对输入序列中每个 string 调用 check_size,实现 string 的大小与 sz 的比较。
与 function 类型联用
1 |
|
修正参数的值
1 | using namespace std::placeholders; |
重排参数顺序
例如,假定 f 是一个可调用对象,它有 5 个参数,则下面对 bind 的调用:
1 | //g是一个有两个参数的可调用对象 |
生成一个新的可调用对象,它有两个参数,分别用占位符 _2 和 _1 表示。这个新的可调用对象将它自己的参数作为第三个和第五个参数传递给 f。f 的第一个、第二个和第四个参数分别被绑定到给定的值 a、b 和 c 上。
传递给 g 的参数按位置绑定到占位符。即,第一个参数绑定到_1,第二个参数绑定到_2。因此,当我们调用 g 时,其第一个参数将被传递给 f 作为最后一个参数,第二个参数将被传递给 f 作为第三个参数。实际上,这个 bind 调用会将 g(_1,_2) 映射为 f(a,b,_2,c,1) 即,对 g 的调用会调用 f, 用 g 的参数代替占位符,再加上绑定的参数 a、b 和 c。例如,调用 g(X,Y) 会调用 f(a,b,Y,c,X)
下面是用 bind 重排参数顺序的一个具体例子,我们可以用 bind 颠倒 isShroter
的含义:
1 | //按单词长度由短至长排序 |
在第一个调用中,当 sort 需要比较两个元素 A 和 B 时,它会调用 isShorter (A, B)。
在第二个对 sort 的调用中,传递给 isShorter 的参数被交换过来了。因此,当 sort 比较两个元素时,就好像调用 isShorter (B, A)一样。
ref 函数:绑定引用参数
#ref
默认情况下,bind 的那些不是占位符的参数被拷贝到 bind 返回的可调用对象中。但是,与 lambda 类似,有时对有些绑定的参数我们希望以引用方式传递,或是要绑定参数的类型无法拷贝。
例如,为了替换一个引用方式捕获 ostream 的 lambda:
1 | //os是一个局部变量,引用一个输出流 |
原因在于 bind 拷贝其参数,而我们不能拷贝一个 ostream。如果我们希望传递给 bind 一个对象而又不拷贝它,就必须使用标准库 ref 函数:
1 | for_each (words.begin(),words.end(), bind(print,ref(os),1,'')); |
函数 ref 返回一个对象,包含给定的引用,此对象是可以拷贝的。标准库中还有一个 cref 函数,生成一个保存 const 引用的类。与 bind 一样,函数 ref 和 cref 也定义在头文件 functional 中。
bind1st () 和 bind2nd ()
bind1st() 和 bind2nd(),只能绑定第一个或第二个参数,局限性太强,在 C++11 里已经弃用了,建议使用新标准的 bind(),用法更灵活更方便。
下面先说明 bind1st() 和 bind2nd() 的用法
bind1st() 和 bind2nd() 都是把二元函数转化为一元函数,方法是绑定其中一个参数。bind1st() 是绑定第一个参数。bind2nd() 是绑定第二个参数。
1 |
|
结果:
1 | There are 4 elements that are less than 40. |
less() 是一个二元函数,less(a, b) 表示判断 a<b 是否成立。
所以 bind2nd(less<int>(), 40) 相当于 x<40 是否成立, 用于判定那些小于 40 的元素。bind1st(less<int>(), 40) 相当于 40<x 是否成立, 用于判定那些大于 40 的元素。
上面的例子使用 bind() 可以写成下面的形式:
1 |
|
结果:
1 | There are 4 elements that are less than 40. |
六、面向对象 OOP
[!NOTE] 面向对象程序设计(object-oriented programming)核心思想
- 数据抽象:将类的接口与实现分离
- 继承:定义相似的类型并对相似关系建模
- 动态绑定(又称运行时绑定):在运行时选择函数的版本,使用相同的代码处理不同类型的对象。
[!NOTE]
当我们使用基类的引用或(指针)调用一个虚函数时,将发生动态绑定。
0 类
类成员
定义在类内部的成员函数是默认inline 的
类成员指针
成员指针是指可以指向类的非静态成员的指针。
成员指针的类型囊括了类的类型以及成员的类型。当初始化一个这样的指针时,我们令其指向类的某个成员,但是不指定该成员所属的对象:直到使用成员指针时,才提供成员所属的对象。
1 |
|
数据成员指针
成员指针包含成员所属的类。再 * 之前添加classname::表示指针可以指向classname的成员:
1 | //p可以指向一个常量(非常量)Person对象的age成员 |
与成员访问运算符.和->类似,也有两种成员指针访问运算符:·* 和->* ,这两个运算符使得我们可以解引用指针并获得该对象的成员:
1 | //使用成员指针访问运算符.*,解引用指针 p 获取成员变量 (类似成员访问运算符.) |
成员函数指针
指向类的成员函数,语法和数据成员指针一样
举例:
由于访问控制规则,数据成员一般为私有的,我们通常无法直接访问 age,如果想访问,可以定义一个函数,令其返回值是指向该成员的指针:
1 | class Screen |
成员指针函数表
具有相同参数和返回类型的函数成员可以存入一个[[#函数表]]中。
1 | //每个函数负责将光标向指定方向移动 |
将成员函数用作可调用对象
和普通的函数指针不同,成员指针不是一个可调用对象,不支持函数调用运算符()。
1 | auto fp = &string::empty; //fp指向string的empty函数 |
从指向成员函数的指针获取可调用对象
方法一: 是使用标准模板库[[#【C++11】function类型]]
1 | vector<string*> pvec; |
方法二: 使用【C++11】mem_fn生成一个可调用对象
标准库功能men_fn让编译器负责推断成员的类型,可以从成员指针生成一个可调用对象。和function不同的是,men_fn可以根据成员指针的类型推断可调用对象的类型,而无须用户显式指定:
1 | find_if (svec.begin(),svec.end(),mem_fn(&string:empty)); |
方法三: 使用 [[2 STL标准库#【C++11】参数绑定 bind 函数]] 从成员函数生成一个可调用对象
1 | //选择范围中的每个string,并将其bind到empty的第一个隐式实参上 |
和function类似的地方是,当我们使用bind时,必须将函数中用于表示执行对象的隐式形参转换成显式的。和mem_fn类似的地方是,bind生成的可调用对象的第一个实参既可以是string的指针,也可以是string的引用:
1 | auto f = bind(&string:empty,_1); |
嵌套类
P746
嵌套类(嵌套类型):定义在类的内部的类
常用于定义作为实现部分的类。
嵌套类是一个独立的类,与外层类基本没什么关系。特别是,外层类的对象和嵌套类的对象是相互独立的。在嵌套类的对象中不包含任何外层类定义的成员;类似的,在外层类的对象中也不包含任何嵌套类定义的成员。
局部类
定义在函数内部的类
局部类定义的类型只在定义它的作用域内可见。和嵌套类不同,局部类的成员受到严格限制。
[!NOTE]
局部类的所有成员(包括函数在内)都必须完整定义在类的内部。因此,局部类的作用与嵌套类相比相差很远。
在实际编程的过程中,因为局部类的成员必须完整定义在类的内部,所以成员函数的复杂性不可能太高。局部类的成员函数一般只有几行代码,否则我们就很难读懂它了。
类似的,在局部类中也不允许声明静态数据成员,因为我们没法定义这样的成员。
局部类不能使用函数作用域中的变量:
局部类只能访问外层作用域定义的类型名、静态变量、枚举成员。
1 | int a, val; |
嵌套的局部类
可以在局部类的内部再嵌套一个类。此时,嵌套类的定义可以出现在局部类之外。不过,嵌套类必须定义在与局部类相同的作用域中。
1 | void foo() |
union联合类
联合(union)是一种特殊的类。
一个union可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。 当我们给union的某个成员赋值之后,该union的其他成员就变成未定义的状态了。分配给一个union对象的存储空间至少要能容纳它的最大的数据成员。
union不能含有引用类型的成员。
在C++11新标准中,含有构造函数或析构函数的类类型也可以作为union的成员类型。union可以为其成员指定public、protected和private等保护标记。默认情况下,union的成员都是公有的,这一点与struct相同。
union可以定义包括构造函数和析构函数在内的成员函数。但是**由于union既不能继承自其他类,也不能作为基类使用,所以在union中不能含有虚函数。
1 | // Token类型的对象只有一个成员,该成员的类型可能是下列类型中的任意一种 |
匿名union
[!NOTE] Title
匿名union不能包含protected成员或private成员,也不能定义成员函数。
匿名union是一个未命名的union,并且在右花括号和分号之间没有任何声明。一旦我们定义了一个匿名union,编译器就自动地为该union创建一个未命名的对象:
1 | //匿名union: 自动创建一个未命名的对象,我们可以直接访问它的成员 |
使用类管理union成员
对于union来说,要想构造或销毁类类型的成员必须执行非常复杂的操作,因此我们通常把含有类类型成员的union内嵌在另一个类当中。这个类可以管理并控制与union的类类型成员有关的状态转换。
举个例子,我们为union添加一个string成员,并将我们的union定义成匿名union,最后将它作为Token类的一个成员。此时,Token类将可以管理union的成员。
为了追踪union中到底存储了什么类型的值,我们通常会定义一个独立的对象,该对象称为union的**判别式(discriminant)**。我们可以使用判别式辨认union存储的值。
为了保持union与其判别式同步,我们将判别式也作为Token的成员。我们的类将定义个枚举类型的成员来追踪其union成员的状态。
在我们的类中定义的函数包括默认构造函数、拷贝控制成员以及一组赋值运算符,这些赋值运算符可以将union的某种类型的值赋给union成员:
1 | class Token |
更多细节P751
1 封装
- 封装是将属性和方法组合在一个类(Class)中的过程。
- 封装的主要目的是隐藏类的内部实现细节,仅暴露必要的接口给外部。
- 通过封装,我们可以控制类成员的访问级别(例如:public、protected 和 private),限制对类内部数据的直接访问,确保数据的完整性和安全性。
成员访问控制
三种访问说明符,控制外部访问成员的权限
| 说明符 | 含义 |
|---|---|
| private | 类成员只能由类的成员函数和友元(类或函数)使用。 |
| protected | 类成员可由类的成员函数和友元(类或函数)、派生类使用。 |
| public | 类成员可由任意函数使用。 |
[!NOTE] 建议:基类的成员访问控制:
public:基类的接口成员
protected:供派生类访问的成员函数
private:供基类及基类的友元访问的成员函数
class与struct
引入 struct 是为了让 C++ 向后兼容 C
- 在 C 语言中,struct 只能包含成员变量,不能包含成员函数。
- 而在 C++ 中,struct 类似于 class,既可以包含成员变量,又可以包含成员函数。
class与struct的区别
- class 的类成员默认 private,struct 默认 public。
- class 继承继承默认是 private 继承,struct 默认 public 继承
- class 可以用于定义模板参数,比如
template<class T>,struct 不能
推荐选用:
若只包含一些变量结构或 POD(plain old data) 时,选用 struct。例如数学中的向量类。
1 | struct Vec2 |
若要实现很多功能的类(非 POD),则选用 class
[!NOTE] POD
“POD” 表示 “Plain Old Data”,翻译为中文是”普通老数据”。这是一个在C++中用来描述一些简单、平凡的数据结构的术语。POD类型在C++标准中有严格的定义,包括以下几个条件:
- 只包含数据成员:POD类型不能包含任何用户自定义的构造函数、析构函数、拷贝构造函数、拷贝赋值运算符或者虚函数。
- 成员是标量类型:即成员不能是类类型或者其他的复杂类型,而只能是整数、浮点数、指针等简单的数据类型。
- 是平凡的标准布局类型:这意味着 POD 类型的布局要符合一定的规范,可以通过 C++标准库的
std::is_pod或std::is_trivial这样的类型特性来检查。POD类型通常可以通过C的
memcpy等底层操作进行内存拷贝,因为其数据布局是简单的、平凡的。这种特性使得POD类型在一些场景中很有用,比如在底层通信、数据序列化和内存映射等方面。然而,随着C++标准的发展,一些更加灵活和安全的替代方法,比如std::memcpy和std::byte等,逐渐成为更好的选择。
友元friend
类允许其他类或者函数访问它的非public成员,方法是令其他类或者函数称为它的友元。
成员函数和友元函数区别:
- 成员函数有this指针,友元函数没有
- 友元不具备传递性,a的友元是b,b的友元是c,但是c不能访问a的非public成员。
- 友元不能继承
全局函数做友元
1 | class Building |
类做友元
1 | class Building; |
成员函数做友元
1 | class Building; |
2 继承
- 继承是派生类从基类那里获得其属性和方法的过程。
- 继承允许我们创建具有共享代码的类层次结构,减少重复代码,提高代码复用性和可维护性。
- 访问修饰符(如 public、protected、private)控制了派生类对基类成员的访问权限。
- 派生类拥有基类的全部成员函数和成员变量,不论是 private、protected、public。需要注意的是:在派生类的各个成员函数中,不能访问基类的 private 成员。
1 | class 派生类名:public 基类名 |
例子如下,分析:
- 这个 Player 类不再仅仅只是 Player 类型,它也是 Entity 类型,就是说它同时是这两种类型。意思是我们可以在任何想要用 Entity 的地方使用 Player
- Player 总是 Entity 的一个超集,它拥有 Entity 的所有内容。
- 因为对于 Player 来说,在 Entity 中任何不是私有的(private)成员,Player 都可以访问到
1 | //基类,一个类被用作基类,那么它必须已定义而非仅仅声明 |
继承方式
继承方式主要作用是影响子类的成员访问控制
继承方式一共有三种:
- 公共继承(public)
- 保护继承(protected)
- 私有继承(private)
在 C++中,默认的继承方式是private。当你声明一个类而没有指定继承方式时,C++默认使用private继承。
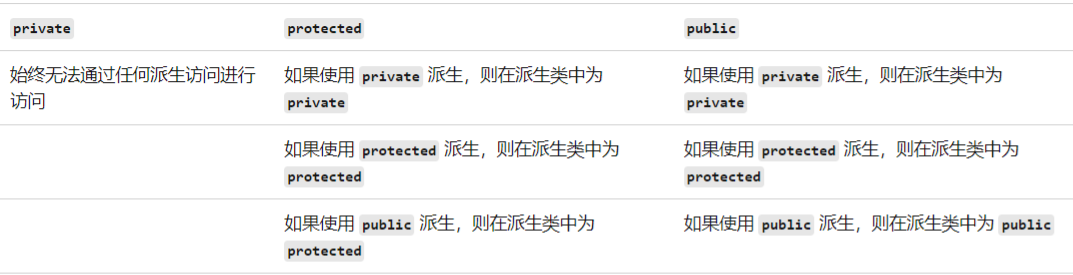
- 父类私有的变量子类皆不可访问
- 公有继承,子类中对应的public protected变量不变
- 保护继承,子类中对应的public protected变量都为protected
- 私有继承,子类对应的变量全为私有
继承与静态成员
如果基类定义了一个静态成员,则在整个继承体系中只存在该成员的唯一定义。不论从基类中派生出来多少个派生类,对于每个静态成员来说都只存在唯一的实例。
1 | class Base |
静态成员遵循通用的访问控制规则,如果基类中的成员是 private 的,则派生类无权访问它。
假设某静态成员是可访问的,则我们既能通过基类使用它也能通过派生类使用它:
1 | void Derived::f(const Derived &derived obj) |
【C++11】防止继承 final
#final
对于一个类,我们不想其他类继承它,或者不想考虑他是否适合作为一个基类,可以在类名后跟一个关键字final:
1 | class NoDerived final{/* */} //NoDerived不能作为基类 |
using改变访问权限
使用 using 关键字可以改变基类成员在派生类中的访问权限,例如将 public 改为 private、将 protected 改为 public。
注意:using 只能改变基类中 public 和 protected 成员的访问权限,不能改变 private 成员的访问权限。因为基类中 private 成员在派生类中是不可见的。
1 | class Base |
类作用域
派生类的作用域嵌套在基类的作用域之内。
名字冲突
[!NOTE]
- 派生类的成员将隐藏同名的基类成员,即使派生类成员和基类成员的参数列表不一致,基类成员仍会被隐藏掉。
- 除了重写虚函数,派生类最好不要重用其他定义在基类中的名字。
和其他作用域一样,派生类也能重用定义在其直接基类或间接基类中的名字,此时定义在内层作用域(即派生类)的名字将隐藏定义在外层作用域(即基类)的名字。
1 | struct Base |
get_mem中mem引用的解析结果是定义在Derived中的名字,下面的代码
1 | Derived d(42); |
的输出结果将是42。
通过作用域运算符来使用隐藏的成员
1 | struct Derived : Base |
函数调用的解析过程
[!Tip] 函数调用的解析过程
理解函数调用的解析过程对于理解C++的继承至关重要。
假定我们调用p->mem()(或者obj.mem()),则依次执行以下4个步骤:
- 首先确定p(或obj)的静态类型。因为我们调用的是一个成员,所以该类型必然是类类型。
- 在p(或obj)的静态类型对应的类中查找mem。如果找不到,则依次在直接基类中不断查找直至到达继承链的顶端。如果找遍了该类及其基类仍然找不到,则编译器将报错。
- 一旦找到了mem,就进行常规的类型检查(参见6.1节,第183页)以确认对于当前找到的mem,本次调用是否合法。
- 假设调用合法,则编译器将根据调用的是否是虚函数而产生不同的代码:
- 如果mem是虚函数且我们是通过引用或指针进行的调用,则编译器产生的代码将在运行时确定到底运行该虚函数的哪个版本,依据是对象的动态类型。
- 反之,如果mem不是虚函数或者我们是通过对象(而非引用或指针)进行的调用,则编译器将产生一个常规函数调用。
派生类的拷贝控制
[!warning]
当派生类定义了拷贝或移动操作时,该操作负责拷贝或移动包括基类部分成员在内的整个对象。
- 派生类构造函数在初始化阶段不但要初始化派生类自己的成员,还负责初始化派生类对象的基类部分。
- 派生类的的拷贝和移动构造函数在拷贝和移动自有成员的同时,也要拷贝和移动基类部分的成员。
- 派生类赋值运算符也必须为基类部分的成员赋值
- 析构函数只负责销毁派生类自己分配的资源,派生类对象的基类部分是自动销毁的。
派生类的拷贝或移动构造函数
1 | class Base {/*...*/}; |
[!warning]
在默认情况下,基类默认构造函数初始化派生类对象的基类部分。如果我们想拷贝(或移动)基类部分,则必须在派生类的构造函数初始值列表中显式地使用基类的拷贝(或移动)构造函数。
派生类赋值运算符
与拷贝和移动构造函数一样,派生类的赋值运算符也必须显式地为其基类部分赋值:
1 | //Base::operator=(const Base&) 不会被自动调用 |
派生类析构函数
在析构函数体执行完成后,对象的成员会被隐式销毁。类似的,对象的基类部分也是隐式销毁的。
因此,和构造函数及赋值运算符不同的是,派生类析构函数只负责销毁由派生类自己分配的资源:
1 | class D:public Base |
对象销毁的顺序正好与其创建的顺序相反: 派生类析构函数首先执行,然后是基类的析构函数,以此类推,沿着继承体系的反方向直至最后。
继承的构造函数
【C++11】派生类能够重用其直接基类定义的构造函数。
派生类只继承其直接基类的构造函数,不能继承默认、拷贝、移动构造函数,如果派生类没有定义这些构造函数,编译器将自动合成。
派生类继承基类构造函数的方式是提供一条注明了(直接)基类名的using声明语句:
1 | class Bulk quote : public Disc_quote |
和普通成员的using声明不同,构造函数的using声明不会改变该构造函数的访问级别。
容器与继承
当我们使用容器存放继承体系中的对象时,通常必须采取间接存储的方式。因为不允许在容器中保存不同类型的元素,所以我们不能把具有继承关系的多种类型的对象直接存放在容器当中。
由此,我们想在容器中存放具有继承关系的对象时,不应该在容器中直接存储对象,而应该存储(智能)指针。
1 | //Quote是基类,Bulk_quote是派生类,派生类指针可以转换为基类指针 |
多重继承
继承多个基类
1 | //派生类的派生类列表中可以包含多个基类 |
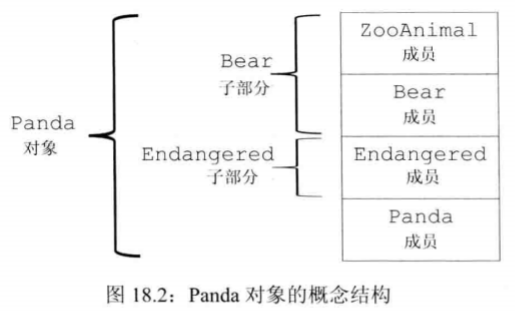
派生类构造函数初始化所有基类
1 | //显式地初始化所有基类 |
初始化顺序:
- ZooAnima是整个继承体系的最终基类,Bear是Panda的直接基类,ZooAnimal是Bear的基类,所以首先初始化ZooAnimal。
- 接下来初始化Panda的第一个直接基类Bear。
- 然后初始化Panda的第二个直接基类Endangered。
- 最后初始化Panda。
【C++11】在C++11新标准中,允许派生类从它的一个或几个基类中继承构造函数。但是如果从多个基类中继承了相同的构造函数(即形参列表完全相同),则程序将产生错误:
1 | struct Base1 |
虚继承
派生类可以通过多个直接基类多次继承同一个间接基类。比如 ZooAnimal 的子类有 Bear、Raccoon,Panda 继承于 Bear、Raccoon,这时 Panda 继承了两次 ZooAnimal。
有时候我们不想让 ZooAnimal 被重复继承,通过虚继承来实现。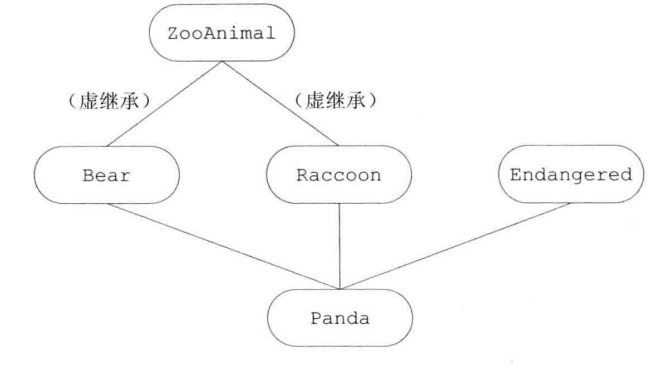
虚继承的目的是令某个类做出声明,承诺愿意共享它的基类。其中,共享的基类子对象称为虚基类(virtual base class)。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含唯一一个共享的虚基类子对象。
[!NOTE]
虚派生只影响从指定了虚基类的派生类中进一步派生出的类,它不会影响派生类本身。
1 | //指定虚基类的方式是在派生列表中添加virtual关键字 |
虚继承的对象的构造方式
含有虚基类的对象的构造顺序与一般的顺序稍有区别:首先使用提供给最低层派生类构造函数的初始值初始化该对象的虚基类子部分,接下来按照直接基类在派生列表中出现的次序依次对其进行初始化。
例如,当我们创建一个Panda对象时:
- 首先使用Panda的构造函数初始值列表中提供的初始值构造虚基类ZooAnimal部分。
- 接下来构造Bear部分。
- 然后构造Raccoon部分。
- 然后构造第三个直接基类Endangered。
- 最后构造Panda部分。
如果Panda没有显式地初始化ZooAnimal基类,则ZooAnimal的默认构造函数将被调用。如果ZooAnima1没有默认构造函数,则代码将发生错误。
析构函数的次序与构造顺序相反
3 多态
多态通俗来说就是多种形态
- 即同一个接口可以有不同的实现。
- 通过多态,我们可以编写更加通用、可扩展的代码,提高代码的灵活性。
静态多态与动态多态
多态分为两类:
静态多态: 编译阶段确定函数地址,函数重载 、 运算符重载和函数模板属于静态多态
动态多态(动态绑定): 运行时确定函数地址,虚函数、纯虚函数实现运行时多态
基类的指针或引用可以绑定到派生类的对象,反之不可以。
对象切割问题:当我们用一个派生类对象初始化或赋值一个基类对象时(注意不是指针),只有该派生类对象中继承的基类部分会被拷贝、移动或赋值,它的派生类部分将被忽略掉。
静态类型与动态类型
静态类型:编译时的类型,运行前就确定了,是变量声明时的类型或表达式生成的类型
动态类型:运行时才确定的类型,是变量或表达式表示的内存中的对象的类型
1 | Actor* p = new Pawn(); // Actor 是基类,Pawn是子类 |
指针 p 的静态类型是 Actor,在编译时已经确定了,但它的动态类型是 Pawn,运行时才知道。
举例
1 | Actor MyActor; |
[!NOTE]
基类的指针或引用的静态类型可能与动态类型不一致
虚函数virtual
- 虚函数可以让我们在子类中重写(又称覆盖,override) 父类的函数,要求形参严格匹配。
- 任何构造函数之外的非静态函数都可以是虚函数
- 关键字virtual只能出现在类内部的声明语句之前,而不能用于类外部的函数定义。
- 如果基类把一个函数声明成虚函数,则该函数在派生类中为隐式的虚函数,即在所有派生类中都是虚函数
- 多态基类必须将析构函数声明为
virtual,即虚析构函数。
1 | claee 父类名{ |
成员函数如果没有被声明为虚函数,则其解析过程发生在编译时而非运行时:
1 | //基类 |
两次输出都是 Entity,原因在于如果我们在类中正常声明函数或方法,当调用这个方法的时候,它总是会去调用属于这个类型的方法,而void printName(Entity* entity);参数类型是Entity*, 意味着它会调用 Entity 内部的 GetName 函数,它只会在 Entity 的内部寻找和调用 GetName.
但是我们希望 C++ 能意识到, 在这里我们传入的其实是一个 Player,所以请调用 Player 的 GetName。此时就需要使用虚函数了。
虚函数的例子,通常有三步。
- 第一步,定义基类,声明基类函数为
virtual的。 - 第二步,定义派生类 (继承基类),派生类实现了定义在基类的
virtual函数。 - 第三步,声明基类指针,并指向派生类,调用
virtual函数,此时虽然是基类指针,但调用的是派生类实现的基类virtual函数。
- 虚函数引入了一种要动态分配的东西,一般通过虚表(vtable) 来实现编译。虚表就是一个包含类中所有虚函数映射的列表,通过虚表我们就可以在运行时找到正确的被重写的函数。
- 简单来说,你需要知道的就是如果你想重写一个函数,你么你必须要把基类中的原函数设置为虚函数
虚函数表原理
[[01 C++八股#⭐虚函数表和动态绑定原理]]
【C++11】overide说明符
新标准允许给被重写的函数用 “override” 关键字标记,增强代码可读性。
如果子类中的函数声明与父类中的函数声明不匹配,就会报错。
1 | //基类 |
纯虚函数(接口类)
#interface #纯虚函数 #接口
- 防止派生类忘记实现虚函数,纯虚函数使得派生类必须实现基类的虚函数。
- 含有纯虚函数的类称为抽象基类,抽象基类负责定义接口,子类可以重写该接口。
- 不能创建抽象基类的对象,但可以创建子类的对象,前提是子类重写了父类的纯虚函数。
抽象类特点:
- 无法实例化对象
- 类中只要有一个纯虚函数就称为抽象类
- 子类必须重写抽象类中的纯虚函数,否则也属于抽象类
- 声明方法: 在基类中纯虚函数的方法的后面加 =0
1 | virtual void funtion() = 0; |
- 在面向对象程序设计中,创建一个只包含未实现方法然后交由子类去实际实现功能的类是非常普遍的, 这通常被称为接口。接口就是一个只包含未实现的方法并作为一个模板的类。并且由于此接口类实际上不包含方法实现,所以我们无法实例化这个类。
- C++ 中的纯虚函数本质上与其他语言(如 C#)中的接口相同。实际上,其他语言有 interface 关键字而不是叫 class,但 C++ 没有。接口只是 C++ 的类而已。
- 纯虚函数与虚函数的区别在于,纯虚函数的基类中的
virtual函数,只定义了,但不实现。实现交给派生类来做。 - 只能实例化一个实现了所有纯虚函数的类。纯虚函数必须被实现,然后我们才能创建这个类的实例。
- 纯虚函数允许我们在基类中定义一个没有实现的函数,然后强制子类去实现该函数。
例子:
1 | //基类 |
再看一个更好的例子
假设我们想编写一个打印这儿所有类名的函数。
1 | class Printable |
上例中,如果 Player 不是 Entity 的话,就要添加接口,如下
1 | class Player : public OtherClass,Printable //加逗号,添加接口Printable |
虚析构与纯虚析构
继承时,要养成的一个好习惯就是,基类析构函数中,一定加上 virtual。
当我们delete一个动态分配的对象的指针时执行析构函数,如果该指针指向继承体系中的某个类型,则有可能出现静态类型与被删除对象的动态类型不符的情况。例如:删除一个Quote* 类型的指针,此时它可能实际指向一个Bulk_quote派生类的的对象。
我们可以在基类中将析构函数定义成虚函数以确保执行正确的析构函数版本:
1 | class Quote |
[!NOTE] Title
- 如果基类的析构函数不是虚函数,则delete一个指向派生类对象的基类指针将产生未定义的行为。
- 虚析构函数将阻止编译器为这个类合成移动操作
虚析构语法:virtual ~类名(){}
纯虚析构语法:virtual ~类名() = 0;
析构调用过程:
基类中只要定义了虚析构,在编译器角度来讲,那么由此基类派生出的所有子类地析构均为对基类的虚析构的重写,当多态发生时,用父类引用,引用子类实例时,此时的虚指针保存的子类虚表的地址,该函数指针数组中的第一元素永远留给虚析构函数指针。所以当 delete 父类引用时,即第一个调用子类虚表中的子类重写的虚析构函数此为第一阶段。然后进入第二阶段:(二阶段纯为内存释放而触发的逐级析构与虚析构就没有半毛钱关系了)而当子类发生析构时,子类内存开始释放,因内存包涵关系,触发父类析构执行,层层向上递进,至到子类所包涵的所有内存释放完成。
4 this指针
- 在(非 static)成员函数内部,我们可以通过 this 指针访问类成员,this 是指向这个函数所属的对象实例的指针
- this 指针本质上是一个指针常量(
T* const)- 对于非 const 成员函数,其 this 指针类型为
T* const,即可以改变成员变量值 - 对于const 成员函数,其 this 指针类型为
const T* const,所以不能改变成员变量的值
- 对于非 const 成员函数,其 this 指针类型为
5 static静态
#static
[!NOTE] 总结
- 静态成员函数只能访问静态成员;非静态成员函数既可以访问非静态成员,也可以访问静态成员。
静态类
首先要声明:Java、C# 等高级语言支持静态类,但 C++ 不支持。 C++ 通过创建仅包含静态成员和私有构造函数(把构造函数放在 private 里)的类来模拟”静态类” (C++经常这样做,比如用抽象类模拟接口的概念),私有构造函数可以阻止类被实例化。
什么是静态类
以下不适用于 C++特性,只是为了解释静态类的概念:
- 静态类内部的成员全是静态成员,没有非静态成员。 一些高级语言中在 class 声明时使用 static 修饰来表示整个类是个静态类,C++不支持这种语法,但是可以实现为所有成员都是静态来达到静态类的效果。
- 静态类不能被实例化,因为所有成员都是静态的,定义对象实际上就是实例化里面的非静态成员,但是静态类并没有非静态成员,所以不用实例化。
- 静态类是密封 (sealed)的。所谓是密封,就是不可被继承,不能拿来做父类。静态类不包括构造函数,因为构造函数就是在实例化对象是调用的,但是静态类又不能被实例化。静态类不能指定任何接口实现,不能有任何实例成员。
- 静态类不包含构造函数,但仍可声明静态构造函数以分配初始值或设置某个静态状态。
- 静态类的成员不能有 protected 访问保护修饰符。
(面向对象的)静态成员变量
在类内成员变量的声明前加上关键字 static,该数据成员就是类内的静态数据成员。
1 | class TestClass |
静态成员变量有以下特点:
- static 成员变量都存储在全局(静态)区,在初始化时其分配内存(而不是在类的实例化过程中分配内存),在程序结束时释放。
- static 成员变量由本类的所有对象共享,不占用对象的内存。
- static 成员变量必须初始化,而且只能在类体外进行。否则,编译能通过,链接不能通过。初始化时可以赋初值,也可以不赋值。如果不赋值,那么会被默认初始化,一般是 0。
- 静态数据成员初始化与一般数据成员初始化不同。初始化时可以不加 static,但必须要有数据类型。被 private、protected、public 修饰的 static 成员变量都可以用这种方式初始化。静态数据成员初始化的格式为:
<数据类型><类名>::<静态数据成员名>=<值> - 可以通过类类型访问,也可以通过类对象访问
- sizeof 运算符不会计算静态成员变量。
1 | class CMyclass{ |
何时采用静态数据成员?
如果想在同类的多个对象之间实现数据共享,又不要用全局变量,那么就可以使用静态成员变量。 也即,静态数据成员主要用在各个对象都有相同的某项属性的时候。比如对于一个存款类,每个实例的利息都是相同的。所以,应该把利息设为存款类的静态数据成员。这有两个好处:
- 不管定义多少个存款类对象,利息数据成员都共享分配在全局数据区的内存,节省存储空间。
- 一旦利息需要改变时,只要改变一次,则所有存款类对象的利息全改变过来了。
你也许会问,用全局变量不是也可以达到这个效果吗?
同全局变量相比,使用静态数据成员有两个优势:
- 静态成员变量没有进入程序的全局命名空间,因此不存在与程序中其它全局命名冲突的可能。
- 可以实现信息隐藏。静态成员变量可以是 private 成员,而全局变量不能。
摘自网络,为什么要使用 static 变量?
(1)Static 表示普通变量时,是为了避免不同的文件中同名,将这个同名变量限制在当前 CPP 文件中使用。定了Static变量时,在这个文件中都可以使用。
(2)Static修饰类的成员变量,是为了将当前变量限制为类的变量,而不是类实例的变量。 该变量可以用来在类的外面进行初始化,而不受类构造函数的影响。比如可以用于表示一个类被创建了多少次。
(面向对象的)静态成员函数
与静态成员变量类似,我们也可以声明一个静态成员函数。
静态成员函数为类服务而不是为某一个类的具体对象服务。 静态成员函数与静态成员变量一样,都是类的内部实现,属于类定义的一部分。普通成员函数必须具体作用于某个对象,而静态成员函数不与任何对象绑定到一起。
普通的成员函数一般都隐含了一个 this 指针,this 指针指向类的对象本身,因为普通成员函数总是具体地属于类的某个具体对象的。当函数被调用时,系统会把当前对象的起始地址赋给 this 指针。通常情况下,this 是缺省的。如函数 fn() 实际上是 this->fn()。
与普通函数相比,静态成员函数属于类本身,而不作用于对象,因此它不具有 this 指针。正因为它没有指向某一个对象,所以它无法访问属于类对象的非静态成员变量和非静态成员函数,它只能调用其余的静态成员函数和静态成员变量。
1 |
|
静态成员函数的特点:
- 出现在类体外的函数定义不能指定关键字 static;
- 静态成员函数只能访问静态成员;非静态成员函数既可以访问非静态成员,也可以访问静态成员。
- 由于没有 this 指针的额外开销,静态成员函数与类的全局函数相比速度上会稍快;
- 调用静态成员函数,两种方式:
- 通过对象的成员访问操作符 (
.) 和(->) - 直接通过类来调用静态成员函数。
- 通过对象的成员访问操作符 (
为什么引入静态成员函数?什么情况下使用
在研究静态成员函数之前,我们先来考虑考虑为什么C++中会引入静态成员函数。
我们来看下面这个例子
1 | class CStaticMember |
我们定义一个 CStaticMember 类,里面包含一个私有的静态成员变量 m_nIntA,如果外部想访问或者更改 m_nIntA 的值,那么根据 C++语法的要求,我们必须提供一个成员函数来进行访问。如下我们提供一个公有的 GetIntA 函数来进行访问。
1 | class CStaticMember |
我们知道在C++中调用类的成员函数,会传递一个this指针,将类的实例化对象的首地址传递给成员函数,函数操作会根据对象首地址计算其成员变量的地址,然后进行操作。然而静态成员变量并不保存在对象的内存布局中,而是保存在数据段中,因而没有必要用到this指针。所以需要一种独立于对象之外对对象静态成员变量的访问操作。在早期C++引入静态成员函数之前,你会看到下面这样奇怪的写法:
1 | (( CStaticMember*)0)->GetIntA(); |
这样的写法就是为了避免了对象.GetIntA()的操作从而避免了对象的实例化操作,如下所示
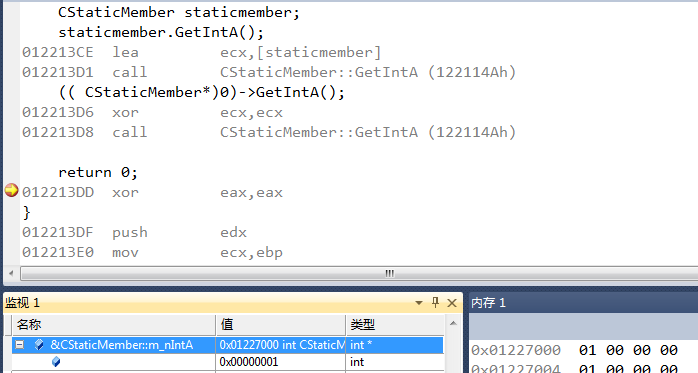
编译器生成的代码是先将 ecx 清零,然后直接调用 CStaticMember:: GetIntA 函数。这种写法的优点就在于不用对进行对象实例化操作从而节省了时间和空间。
当函数不操作类内非 static 成员变量时(即与类的实例无关的函数),既可以考虑使用静态成员函数。
(面向过程的)静态全局变量
在全局变量前,加上关键字 static,该变量就被定义成为一个静态全局变量。
1 | //Example 1 |
静态全局变量有以下特点:
- 静态变量都在全局数据区分配内存
- 未经初始化的静态全局变量会被程序初始化为 0;
- 静态全局变量在声明它的整个文件都是可见的,而在文件之外是不可见的; (内部连接)
定义全局变量就可以实现变量在文件中的共享,但定义静态全局变量还有以下好处:
- 静态全局变量不能被其它文件所用;
- 其它文件中可以定义相同名字的变量,不会发生冲突;
将上述示例代码改为如下:
1 | //Example 2 |
编译并运行 Example 2,会发现上述代码可以分别通过编译,但运行时出现错误。 这就是因为静态全局变量不能被其它文件所用,即使在其它文件中使用 extern 进行声明也不行。
我们将
1 | static int n; //定义静态全局变量 |
改为
1 | int n; //定义全局变量 |
再次编译运行程序,程序可正常运行。
因此,在一个文件中,静态全局变量和全局变量功能相同;而在两个文件中,要使用同一个变量,则只能使用全局变量而不能使用静态全局变量。
(面向过程的)静态局部变量
在局部变量前,加上关键字 static,该变量就被定义成为一个静态局部变量。
1 | //Example 3 |
通常,在函数体内定义了一个变量,每当程序运行到该语句时都会给该局部变量分配栈内存。但随着程序退出函数体,系统就会收回栈内存,局部变量也相应失效。
但有时候我们需要在两次调用之间对变量的值进行保存。通常的想法是定义一个全局变量来实现。但这样一来,变量已经不再属于函数本身了,不再仅受函数的控制,这给程序的维护带来不便。
静态局部变量正好可以解决这个问题。静态局部变量保存在全局数据区,每次的值保持到下一次调用,直到下次赋新值。即静态局部变量不会随着函数调用结束而销毁,而是在程序运行结束才会被销毁
静态局部变量有以下特点:
- 静态局部变量在全局数据区分配内存;
- 静态局部变量在程序执行到该对象的声明处时被首次初始化,即以后的函数调用不再进行初始化;
- 静态局部变量一般在声明处初始化,如果没有显式初始化,会被程序自动初始化为 0;
(面向过程的)静态函数
在函数的返回类型前加上 static 关键字, 函数即被定义为静态函数。静态函数与普通函数不同,它只能在声明它的文件当中可见,不能被其它文件使用。
1 | //Example 4 |
定义静态函数的好处:(类似于静态全局变量)
- 静态函数不能被其它文件所用;
- 其它文件中可以定义相同名字的函数,不会发生冲突;
6 构造函数
- 当创建对象的时候,构造函数被调用
- 构造函数最重要的作用就是初始化类
1 | class Entity { |
- 构造函数没有返回类型
- 构造函数不能被声明为const
- 构造函数的命名必须和类名一样
- 如果你不指定构造函数,你仍然有一个构造函数,这叫做默认构造函数(default constructor),是默认就有的。但是,我们仍然可以删除该默认构造函数:
1 | class Log{ |
- 构造函数不会再你没有实例化对象的时候运行,所以如果你只是使用类的静态方法,构造函数是不会执行的。
- 当你用 new 关键字创建对象实例的时候也会调用构造函数。
不适用默认构造函数的情况:
- 如果类包含有内置类型或者复合类型的成员,则只有当这些成员全都被赋予了类内初始值是,这个类才适合于使用默认构造函数。
- 如果类中包含一个其他【类】类型的成员且这个成员的类型没有默认构造函数,那么编译器将无法初始化该成员,此时我们必须自定义默认构造函数。
- p449其他一些情况导致编译器无法生成默认构造函数。
构造函数必有有初始值的情况:
- 如果成员是const或者是引用,必须将其初始化。
- 党成员属于某种【类】类型且该类没有定义默认构造函数时,必须将这个成员初始化。
类对象的初始化和析构顺序
构造顺序总结:虚继承基类的构造->普通继承基类的构造->子类成员变量->子类构造函数
析构顺序相反
基类初始化顺序
如果当前类继承自一个或多个基类,它们将按照声明顺序进行初始化,但是在有虚继承和一般继承存在的情况下,优先虚继承。
比如虚继承:class MyClass : public Base1, public virtual Base2,此时应当先调用Base2的构造函数,再调用Base1的构造函数。成员变量初始化顺序
类的成员变量按照它们在类定义中的声明顺序进行初始化,第一个成员先初始化,以此类推。构造函数初始值列表的前后位置不会影响实际的初始化顺序。执行构造函数
在基类和成员变量初始化完成后,再执行子类的构造函数。(注意,成员变量初始化在构造函数执行前)。
1 |
|
默认构造函数
由来
先看下面代码
代码内容很简单,定义了一个包含成员 x,y 的类 Point。在序列的地方可以使用这个类
虽然我们并没有定义 Point 类的构造函数,我们依然可以定义 Point 类的 pt 对象并使用它,其原因是编译器会自动生成一个缺省的构造函数,其效果相当于
但是,一旦添加了其他有参数的构造函数,编译器就不再生成缺省的构造函数了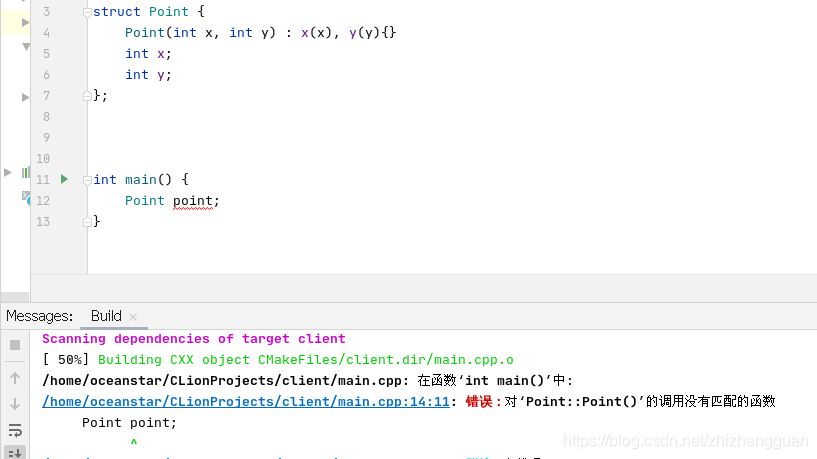
定义
默认构造函数:是无参调用的构造函数(重点是无参调用),包括两种:
- 没有参数
- 每个参数有初始值(默认实参)
调用时机
如果构造函数在未指定参数或者提供了一个空初始化器列表,则会调用默认构造函数:
1 | vector v1; |
[!NOTE] Title
如果一个构造函数为所有参数都提供了默认实参,那它实际上也定义了默认构造函数
1 | class Box |
说明
默认构造函数是一种特殊的成员函数。如果未在类中声明任何构造函数,则编译器将提供隐式的inline默认构造函数
1 |
|
如果声明了任何非默认构造函数、编译器不会提供默认构造函数:
1 | class Box { |
【C++11】=default
C++11 允许我们使用 =default 来要求编译器生成一个默认构造函数:
1 | class Sales data |
=default既可以和声明一起出现在类的内部,也可以作为定义出现在类的外部。- 和其他函数一样,如果
=default在类的内部,那么默认构造函数是 inline 的;如果他在类的外部,则该成员默认不是 inline 的。 - 我们只能对具有默认版本的成员函数使用=default(即,默认构造函数或拷贝控制成员)。
【C++11】委托构造函数
委托构造函数使用他所属类的其他构造函数执行它自己的初始化过程,或者说它把它自己的一些(或全部)职责委托给了其他构造函数。
在委托构造函数内,成员初始值列表只有一个唯一的入口,就是类名本身。
1 | class Sales_data |
转换构造函数(隐式类类型转换)
转换构造函数的作用是将一个其他类型的数据隐式转换成该类的对象。 (不能反过来将该类的对象转换为其他类型,[[#类型转换函数(类型转换运算符)]]可以实现)
当一个构造函数只有一个参数,而且该参数又不是本类的 const 引用时(即不是拷贝构造函数时),这种构造函数又被称为转换构造函数。
例如:
1 |
|
这里调用了转化构造函数,将 int 类型的 1000 通过调用转换构造函数转换成了一个临时的 Person 类型对象赋值给 p。
如果不想要这种隐式转换,可以通过将构造函数声明为 explicit 加以阻止。
注意:隐式类类型转换只能连续进行一次。
1 |
|
如上,在 test5 中,int 型的 23 就被隐式转换为一个 Entity 对象,这是因为 Entity 类中有一个 Entity(int age) 构造函数,因此可以调用这个构造函数,然后把 23 作为他的唯一参数,就可以创建一个 Entity 对象。
同时我们也能看到,对于语句Entity test3 = "lk";会报错,原因是只能进行一次隐式转换,"lk"是const char数组,这里需要先转换为std::string,再从 string 转换为 Entity 变量,两次隐式转换是不行的,所以会报错。但是写为Entity test4 = std::string("lk");就可以进行隐式转换。
最好不写 Entity test5 = 23 这样的代码,应尽量避免类类型隐式转换。因为 Entity test2(23); 更清晰。
explicit 关键字
#explicit
explict 显式
implicit 隐式
将转换构造函数声明为 explicit,禁止转换构造函数进行隐式转换。
[[#转换构造函数(隐式类类型转换)]]
只能用于直接初始化,不能用于拷贝初始化(使用 = 进行初始化)
1 |
|
聚合类
#聚合类
当一个类满足如下条件时,我们说它是聚合的:
- 所有成员都是public
- 没有定义任何构造函数
- 没有类内初始值
- 没有基类
- 没有virtual函数
1 | //聚合类例子 |
聚合类使得用户可以直接访问其成员,且具有特殊的初始化语法形式。
初始值的顺序必须与生命的顺序一致
1 | Data vall = {0, "test"}; |
字面值常量类
#字面值常量类
数据成员都是字面值类型的聚合类是字面值常量类
如果不是聚合类,符合下属要求也是字面值常量类
- 数据成员都必须是字面值类型。
- 类必须至少含有一个 constexpr 构造函数。
- 如果一个数据成员含有类内初始值,则内置类型成员的初始值必须是一条常量表达式; 或者如果成员属于某种类类型,则初始值必须使用成员自己的 constexpr 构造函数。
- 类必须使用析构函数的默认定义,该成员负责销毁类的对象
constexpr构造函数
1 | class Debug |
7 拷贝控制
综合案例P460
定义一个类时,显式或隐式地指定此类型的对象拷贝、移动、赋值和销毁,通过五钟特殊地成员函数来控制这些操作,称为拷贝控制操作:
- 拷贝/移动构造函数:定义用同类型的另一个对象初始化本对象时做什么
- 拷贝/移动赋值运算符:定义将一个对象赋予同类型的另一个对象时做什么
- 析构函数:定义当此类型销毁时做什么
[!NOTE]
如果一个类没有定义这些拷贝控制成员,编译器会自动为它定义缺失的操作,但有时这不是我们想要的,所以才要自己定义。
7.1 拷贝构造函数
如果一个构造函数的第一个参数是自身类类型的引用,且任何额外参数都有默认值,则此构造函数是拷贝构造函数。
拷贝构造函数的第一个参数必须是一个引用类型,且通常是隐式地使用
拷贝构造函数的格式:
1 | //声明: |
1 | class Foo |
默认拷贝构造函数(又称合成拷贝构造函数)通常时将每个非static成员拷贝到正在创建地对象中,也有一些特别的会阻止拷贝该类的对象。
1 | class Sales_data |
拷贝构造函数调用时机
- 用一个对象初始化新对象时
- 一个对象以值传递的方式传入函数体,需要拷贝构造函数创建一个临时对象压入到栈空间中。
- 一个对象以值传递的方式从函数返回,需要执行拷贝构造函数创建一个临时对象作为返回值。
深拷贝与浅拷贝
[!NOTE] 总结
如果属性有在堆区开辟的,一定要自己提供拷贝构造函数,防止浅拷贝带来的问题
浅拷贝:简单的赋值拷贝操作,仅复制对象的基本类型成员和指针成员的值(直接按 bit 位复制),而不复制指针所指向的内存。
这可能导致两个对象共享相同的资源,从而引发潜在的问题,如内存泄漏、意外修改共享资源等。
一般来说编译器实现的默认拷贝构造函数就是浅拷贝。
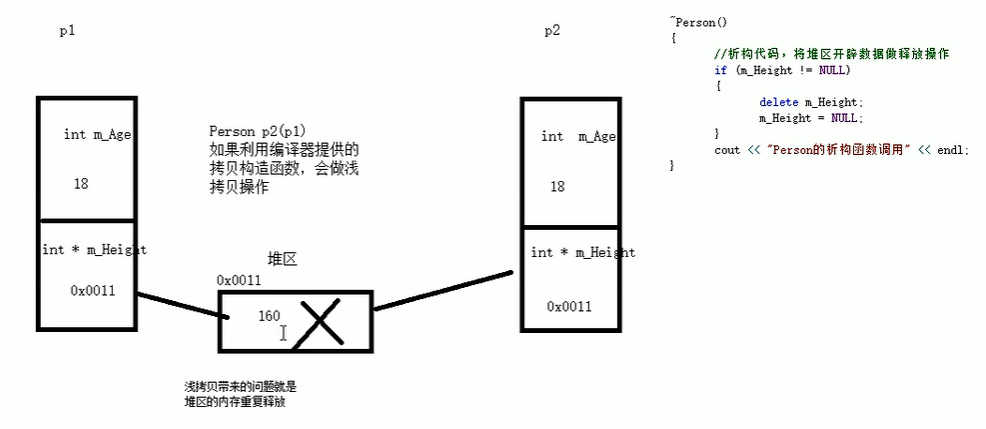
深拷贝:在堆区重新申请空间,进行拷贝操作。
进一步理解:在复制对象的同时复制底层资源的行为又被称作深拷贝(Deep copying),例如在一个对象中有一个指针,那么在复制这个对象时就不能只复制指针,也要将指针所指向的数据复制到新的堆区。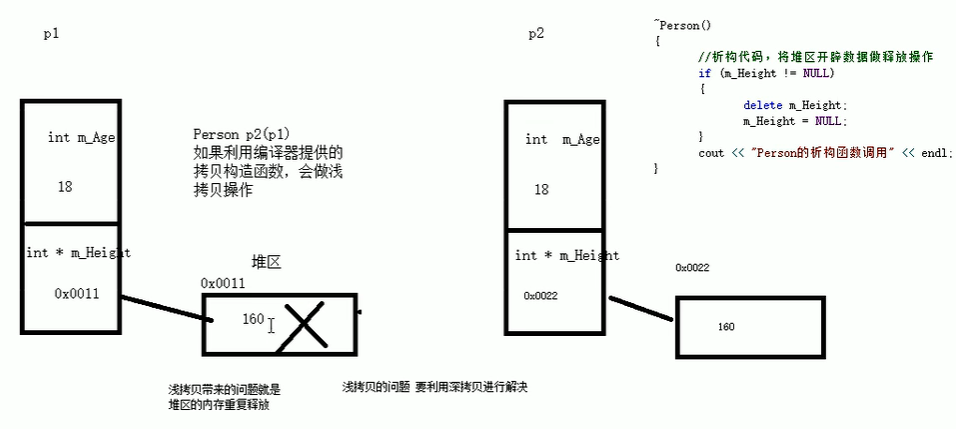
示例:
1 |
|
1 | //浅拷贝 |
对于基本类型的数据以及简单的对象,它们之间的拷贝非常简单,就是按位复制内存。例如:
1 | class Base |
对于简单的类,默认的拷贝构造函数一般就够用了,我们也没有必要再显式地定义一个功能类似的拷贝构造函数。但是当类持有其它资源时,例如动态分配的内存、指向其他数据的指针等,默认的拷贝构造函数就不能拷贝这些资源了,我们必须显式地定义拷贝构造函数,以完整地拷贝对象的所有数据。
使用浅拷贝还是深拷贝
如果一个类拥有指针类型的成员变量,那么绝大部分情况下就需要深拷贝,因为只有这样,才能将指针指向的内容再复制出一份来,让原有对象和新生对象相互独立,彼此之间不受影响。如果类的成员变量没有指针,一般浅拷贝足以。
另外一种需要深拷贝的情况就是在创建对象时进行一些预处理工作,比如统计创建过的对象的数目、记录对象创建的时间等,请看下面的例子:
1 |
|
运行结果:
obj1: count = 1, time = 1488344372
obj2: count = 2, time = 1488344375
运行程序,先输出第一行结果,等待 3 秒后再输出第二行结果。Base 类中的 m_time 和 m_count 分别记录了对象的创建时间和创建数目,它们在不同的对象中有不同的值,所以需要在初始化对象的时候提前处理一下,这样浅拷贝就不能胜任了,就必须使用深拷贝了。
7.2 拷贝赋值运算符
1 |
|
[!NOTE]
赋值运算符通常应该返回一个指向其左侧运算对象的引用
如果类未定义自己的拷贝赋值运算符,编译器就会为它合成一个默认拷贝赋值运算符。通常默认拷贝赋值运算符将右侧运算对象的每个非 static 成员赋予左侧运算对象的对应成员
1 | //下面的代码等价于Sales_data的默认拷贝赋值运算符: |
拷贝构造和拷贝赋值的区别
[!bug] Title
区分调用哪一个并不是看表达式是使用()还是=,而是看是否有新的对象实例产生。
- 产生了新对象实例,调用的是拷贝构造函数
- 没有产生新对象实例,调用的是赋值运算符
拷贝构造函数和拷贝赋值运算符的行为比较相似,都是将一个对象的值复制给另一个对象;但是其结果却有些不同,拷贝构造函数使用传入对象的值生成一个新的对象的实例,而赋值运算符是将对象的值复制给一个已经存在的实例。这种区别从两者的名字也可以很轻易的分辨出来:
拷贝构造函数也是一种构造函数,那么它的功能就是创建一个新的对象实例;赋值运算符是执行某种运算,将一个对象的值复制给另一个对象(已经存在的)。
调用的是拷贝构造函数还是赋值运算符,主要是看是否有新的对象实例产生。如果产生了新的对象实例,那调用的就是拷贝构造函数;如果没有,那就是对已有的对象赋值,调用的是赋值运算符。
1 |
|
7.3 析构函数
执行与构造函数相反的操作,释放对象使用的资源,并销毁对象的非static数据成员。
- 构造函数中,成员初始化在构造函数之前执行,按照在类中定义顺序进行初始化
- 析构函数中,首先执行析构函数,然后销毁成员,成员按初始化顺序的逆序销毁
1
2
3
4
5class Foo
{
public:
~Foo(); //析构函数没有返回值,也不接受参数,因此不能重载(唯一性)
}
[!warning] 析构函数调用时机
无论何时一个对象被销毁,就会自动调用其析构函数:
- 变量在离开其作用域时被销毁。
- 当一个对象被销毁时,其成员被销毁。
- 容器(无论是标准库容器还是数组)被销毁时,其元素被销毁。
- 对于动态分配的对象,当对指向它的指针应用delete运算符时被销毁
- 对于临时对象,当创建它的完整表达式结束时被销毁。
当指向一个对象的引用或指针离开作用域时,析构函数不会执行。
类中未定义时,编译器会合成一个默认析构函数,通常合成析构函数函数体为空,某些类的默认析构函数被用来阻止该类型的对象被销毁。
1 | //下面代码等价于Sales_data的默认析构函数 |
析构函数销毁的是什么?
C++primer p446结尾说到:
认识到析构函数体自身并不直接销毁 成员 是非常重要的。 成员是在析构函数体之后隐含的 析构阶段中被销毁的。在整个对象销毁过程中,析构函数体是作为成员销毁步骤之外的另一部分而进行的
我对这段话的理解如下:
析构函数体只会销毁对象申请的动态内存资源(new 的资源),而不会销毁成员变量所占的资源。
“隐含的析构阶段”即 C++在执行完析构函数体后,会自动执行以下三步进行成员的销毁:
- X 的析构函数调用 X 里所有直接的非 static 成员的析构函数
- X 的析构函数会去调用 X 的所有直接父类的析构函数
- 如果 X 是该对象本身的类型,还会再去调用 X 的所有虚基类的析构函数
7.4 三/五法则
当定义一个类时,我们显式或隐式地定义了此类型的对象在拷贝、赋值和销毁时做什么。一个类通过定义三种特殊成员成员函数来控制拷贝操作:拷贝构造函数、拷贝赋值运算符、析构函数(C++11新标准加入了移动构造函数和移动赋值运算符)。
三法则
[!NOTE] 三法则
- 如果一个类需要自定义析构函数,那么它一定也需要自定义拷贝赋值运算符和拷贝构造函数
- 如果一个类需要一个拷贝构造函数,那么肯定也需要一个拷贝赋值运算符,反之成立。
- 如果一个函数需要拷贝构造运算符或者拷贝赋值运算符,不必然意味着需要析构函数
[!NOTE] 特例
基类的析构函数不遵循该原则,如果基类将析构函数设定为虚函数,此时该析构函数内容为空,我们无法由此判断该基类还需要赋值运算符或拷贝构造函数
如何理解三法则,通常,若一个类需要析构函数,则代表其合成的析构函数不足以释放类所拥有的资源,其中最典型的就是指针成员。所以,我们需要自己写析构函数来释放给指针所分配的内存来防止内存泄露。
那么为什么说“一定需要拷贝构造函数和赋值操作符”呢?
原因还是这样:类中出现了指针类型的成员。有指针类型的成员,我们必须防止浅拷贝问题,所以,一定需要拷贝构造函数和赋值操作符,这两个函数是防止浅拷贝问题所必须的。
五法则
在较新的 C++11 标准中,为了支持移动语义,又增加了移动构造函数和移动赋值运算符,这样共有五个特殊的成员函数,所以又称为“C++五法则”;
也就是说,“三法则”是针对较旧的 C++89 标准说的,“五法则”是针对较新的 C++11 标准说的;为了统一称呼,后来人们干把它叫做“C++ 三/五法则”;
7.6 阻止拷贝
有些类不需要拷贝构造函数和拷贝赋值运算符,比如iostream类阻止了拷贝,以避免多个对象写入或读取相同的IO缓冲。
【C++11】 =delete 删除函数
#delete
1 | struct NoCopy |
=delete通知编译器(以及我们代码的读者),我们不希望定义这些成员。
[!NOTE] 与=default的不同点
- =delete必须出现在函数第一次声明的时候
- 可以对普通函数指定=delete(=defalut只能用于具有合成版本的成员函数)
- 不可删除析构函数
声明为私有
C++11之前,类是通过将其拷贝构造函数和拷贝赋值运算符声明为private的来阻止拷贝:
1 | class PrivateCopy |
7.7 拷贝控制和资源管理
P452
通常,管理类外资源的类必须定义拷贝控制成员。这种类需要通过析构函数来释放对象所分配的资源。一旦一个类需要析构函数,那么它几乎肯定也需要一个拷贝构造函数和一个拷贝赋值运算符。
为了定义这些成员,我们首先必须确定此类型对象的拷贝语义。一般来说,有两种选择:可以定义拷贝操作,使类的行为看起来像一个值或者像一个指针。
类的行为像一个值,意味着它应该也有自己的状态。 当我们拷贝一个像值的对象时,副本和原对象是完全独立的。改变副本不会对原对象有任何影响,反之亦然。例如标准库容器和string类的行为像一个值。
行为像指针的类则共享状态。 当我们拷贝一个这种类的对象时,副本和原对象使用相同的底层数据。改变副本也会改变原对象,反之亦然。例如shared ptr类提供类似指针的行为。
通常,类直接拷贝内置类型(不包括指针)成员:这些成员本身就是值,因此通常应该让它们的行为像值一样。我们如何拷贝指针成员决定了像HasPtr这样的类是具有类值行为还是类指针行为。
行为像值的类
为了提供类值的行为,对于类管理的资源,每个对象都应该拥有一份自己的拷贝。这意味着对于ps指向的string,每个HasPtr对象都必须有自己的拷贝。为了实现类值行为,HasPtr需要
- 定义一个拷贝构造函数,完成string的拷贝,而不是拷贝指针
- 定义一个析构函数来释放string
- 定义一个拷贝赋值运算符来释放对象当前的string,并从右侧运算对象拷贝string
类值版本的HasPtr如下所示
1 | class Hasptr |
我们的类足够简单,在类内就已定义了除赋值运算符之外的所有成员函数。第一个构造函数接受一个(可选的)string参数。这个构造函数动态分配它自己的string副本,并将指向string的指针保存在ps中。拷贝构造函数也分配它自己的string副本。析构函数对指针成员ps执行delete,释放构造函数中分配的内存。
赋值运算符通常组合了析构函数和构造函数的操作。类似析构函数,赋值操作会销毁左侧运算对象的资源。类似拷贝构造函数,赋值操作会从右侧运算对象拷贝数据。但是,非常重要的一点是,这些操作是以正确的顺序执行的,即使将一个对象赋予它自身,也保证正确。而且,如果可能,我们编写的赋值运算符还应该是异常安全的一当异常发生时能将左侧运算对象置于一个有意义的状态。
行为像指针的类
对于行为类似指针的类,我们需要为其定义拷贝构造函数和拷贝赋值运算符,来拷贝指针成员本身而不是它指向的string。我们的类仍然需要自己的析构函数来释放接受string参数的构造函数分配的内存。但是,在本例中,析构函数不能单方面地释放关联的string。只有当最后一个指向string的HasPtr销毁时,它才可以释放string。
令一个类展现类似指针的行为的最好方法是使用shared_ptr来管理类中的资源。拷贝(或赋值)一个shared_ptr会拷贝(赋值)shared_ptr所指向的指针。shared_ptr类自己记录有多少用户共享它所指向的对象。当没有用户使用对象时,shared_ptr类负责释放资源。
但是,有时我们希望直接管理资源。在这种情况下,使用引用计数(reference count)就很有用了。为了说明引用计数如何工作,我们将重新定义HasPtr,令其行为像指针一样,但我们不使用shared_ptr,而是设计自己的引用计数。
引用计数的工作方式如下:
- 除了初始化对象外,每个构造函数(拷贝构造函数除外)还要创建一个引用计数,用来记录有多少对象与正在创建的对象共享状态。当我们创建一个对象时,只有一个对象共享状态,因此将计数器初始化为1。
- 拷贝构造函数不分配新的计数器,而是拷贝给定对象的数据成员,包括计数器。拷贝构造函数递增共享的计数器,指出给定对象的状态又被一个新用户所共享。
- 析构函数递减计数器,指出共享状态的用户少了一个。如果计数器变为0,则析构函数释放状态。
- 拷贝赋值运算符递增右侧运算对象的计数器,递减左侧运算对象的计数器。如果左侧运算对象的计数器变为0,意味着它的共享状态没有用户了,拷贝赋值运算符就必须销毁状态。
- 将计数器保存在动态内存中。当创建一个对象时,我们也分配一个新的计数器。当拷贝或赋值对象时,我们拷贝指向计数器的指针。使用这种方法,副本和原对象都会指向相同的计数器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46class Hasptr
{
public:
//构造函数分配新的string和新的计数器,将计数器置为1
Hasptr(const std:string &s = std::string()):
ps(new std::string(s)),i(0),use(new std::size t(1)){}
//拷贝构造函数拷贝所有三个数据成员,并递增计数器
Hasptr(const Hasptr &p) : ps(p.ps),i(p.i),use(p.use)
{ ++*use };
Hasptr&operator=(const Hasptr&);
~Hasptr();
private:
std::string *ps;
int i;
std::size_t *use;//用来记录有多少个对象共享*ps的成员
};
Hasptr::~HasPtr()
{
//如果引用计数变为0
if(--*use==0)
{
delete ps; //释放string内存
delete use; //释放计数器内存
}
}
Hasptr& Hasptr::operator=(const Hasptr &rhs)
{
++*rhs.use;//递增右侧运算对象的引用计数
//然后递减本对象的引用计数
if (--*use == 0){
delete ps; //如果没有其他用户
delete use; //释放本对象分配的成员
}
ps = rhs.ps;
//将数据从rhs拷贝到本对象
i = rhs.i;
use = rhs.use;
return *this;
//返回本对象
}
自定义类中的swap函数
交换两个类值对象得代码可能是这样得:
1 | Hasptr temp = v1; //创建v1的值的一个临时副本 |
拷贝了三次,我们不希望有这些多余的内存操作,可以通过交换指针实现
1 | string *temp = v1.ps; //为v1.ps中的指针创建一个副本 |
这样我们就能编写优化后的swap函数
1 | class Hasptr |
定义swap的类通常用swap来定义它们的赋值运算符。这些运算符使用了一种名为拷贝并交换(copy and swap) 的技术。这种技术将左侧运算对象与右侧运算对象的一个副本进行交换:
1 | //注意rhs是按值传递的,意味着HasPtr的拷贝构造函数将右侧运算对象中的string拷贝到rhs |
在这个版本的赋值运算符中,参数并不是一个引用,我们将右侧运算对象以传值方式传递给了赋值运算符。因此,rhs是右侧运算对象的一个副本。参数传递时拷贝HasPtr的操作会分配该对象的string的一个新副本。
在赋值运算符的函数体中,我们调用swap来交换rhs和* this中的数据成员。这个调用将左侧运算对象中原来保存的指针存入rhs中,并将rhs中原来的指针存入* this中。因此,在swap调用之后,* this中的指针成员将指向新分配的string一右侧运算对象中string的一个副本。
当赋值运算符结束时,rhs被销毁,HasPtr的析构函数将执行。此析构函数delete rhs现在指向的内存,即,释放掉左侧运算对象中原来的内存。
这个技术的有趣之处是它自动处理了自赋值情况且天然就是异常安全的。它通过在改变左侧运算对象之前拷贝右侧运算对象保证了自赋值的正确。
7.8 【C++11】对象移动(移动语义)
重新分配内存的过程中,从旧内存拷贝到新内存是不必要的,更好的方式是移动元素,开销更低。(旧C++标准只能通过拷贝)
[!NOTE]
- 标准库容器、string和shared_ptr类既支持移动也支持拷贝。
- IO类和unique_ptr类可以移动但不能拷贝(因为包含不能被共享的资源(如指针或IO缓冲))。
std:: move 函数
#movestd::move 显式地将一个左值对象转换为右值引用,该对象称为”移后源对象“。
可以使用
static_cast显式地将一个左值对象转换为右值引用,不安全,还是用std::move比较好
1 | int &&rr = std::move(i); //正确 |
调用 std::move 就意味着承诺:除了对 i 赋值或销毁它外,我们将不再使用它。如果后续使用了该值,会产生未定义行为。
标准库是这样定义 move 的:
1 | //remove_reference是在16.2.3节(第605页)中介绍的 |
移动构造函数和移动赋值运算符
1 | //移动构造函数,引用参数使用了右值引用符号&& |
默认移动函数
只有当一个类没有定义任何自己版本的拷贝控制成员,且它的所有数据成员都能移动构造或移动赋值时,编译器才会为它合成移动构造函数或移动赋值运算符。
1 | //编译器会为X和hasX合成移动操作 |
移动迭代器
一般的迭代器的解引用返回指向一个元素的左值,但移动迭代器的解引用生成一个右值引用。make_move_iterator函数将一个普通迭代器转换为一个移动迭代器,此函数接受一个迭代器参数,返回一个移动迭代器(可以使用和普通迭代器同样的操作)。
1 | void StrVec::reallocate() |
引用限定符
在参数列表后放置一个引用限定符,可以是&或&&,分别指出this可以指向一个左值或右值。
只能用于非static成员函数,且必须同时出现在函数的声明和定义中。
对于&限定的函数,我们只能将它用于左值:对于&&限定的函数,只能用于右值:
1 | Foo &retFoo(); //返回一个引用;retFoo调用是一个左值 |
一个函数可以同时用const和引用限定。在此情况下,引用限定符必须跟随在const限定符之后:
1 | class Foo |
[!NOTE] Title
如果一个成员函数有引用限定符,则具有相同参数列表的所有版本都必须有引用限定符
七、IO 库
1 IO 类
cin>> 读进去
cout <<写出去
endl是一个被称为操纵符的特殊值,写入endl的效果是结束当前行,并将与设备关联的缓冲区(buffer)中的内容刷到设备中。




- 以上操作都是操纵char数据的,为了支持宽字符wchar_t的语言,只需要在操作符前面加上w就可,如wcout、wistream
- ifstream和istringstream都继承自istream,因此他们也可以执行cin、cout、>>、getline等操作。
- 不能拷贝或对IO对象赋值
[!NOTE] Title
本节剩下部分所介绍的标准库流特性都可以无差别地应用于普通流、文件流和string流以及char或宽字符流版本。
2 管理输出缓冲
每个输出流都管理一个缓冲区,用来保存程序读写的数据。
导致缓冲刷新(即,数据真正写到输出设备或文件)的原因有很多:
- 程序正常结束,作为main函数的return操作的一部分,缓冲刷新被执行。
- 缓冲区满时,需要刷新缓冲,而后新的数据才能继续写入缓冲区。
- 我们可以使用操纵符(如endl)来显式刷新缓冲区。
- 在每个输出操作之后,我们可以用操纵符unitbuf设置流的内部状态,来清空缓冲区。默认情况下,对cerr是设置unitbuf的,因此写到cerr的内容都是立即刷新的。
- 一个输出流可能被关联到另一个流。 在这种情况下,当读写被关联的流时,关联到的流的缓冲区会被刷新。例如,默认情况下,cin和cerr都关联到cout。因此,读cin或写cerr都会导致cout的缓冲区被刷新。
1
2
3
4
5
6cout<<"hi!"<<endl; //输出hi和一个换行,然后刷新缓冲区
cout<<"hi!"<<flush: //输出hi,然后刷新缓冲区,不附加任何额外字符
cout<<"hi!"<<ends; //输出hi和一个空字符,然后刷新缓冲区
int i;
cin>>i; //cin和cout关联,因此该句将cout的缓冲区刷新
[!warning] 警告
程序崩溃,输出缓冲区不会被刷新
3 文件 IO
文件类型分为两种:
- 文本文件 - 文件以文本的ASCII码形式存储在计算机中
- 二进制文件 - 文件以文本的二进制形式存储在计算机中,用户一般不能直接读懂它们
头文件 < fstream > 定义了三个类型来支持文件IO:
ifstream 读文件ofstream 写文件fstream 读写文件
- 当一个fstream对象被销毁时(比如离开作用域时),close会自动被调用,文件自动关闭。

- 每个文件流类型都定义了一个默认的文件模式,ifstream是in,ofstream是out,fstream是in和out。后面的例子我显式的写了出来
- 文件模式可以组合使用,利用 “|” 操作符。
例如:用二进制方式写文件 ofstream :: binary | ofstream :: out1
ofstream ofs("test.txt", ofstream::binary | ofstream::out);
- 以out模式打开文件,文件的内容会被丢弃,若想保留ofstream打开的文件中已有的数据,唯一办法是显式指定app或in模式
[!NOTE] 【C++11】文件名
C++11中,文件名既可以是库类型string对象,也可以是指向C风格字符串的指针
写文件ofstream
写文件步骤如下:
- 包含头文件
`#include - 创建流对象
ofstream ofs; - 打开文件
ofs.open("文件名",打开方式); - 写数据
ofs << "写入的数据"; - 关闭文件
ofs.close();
1 |
|
读文件ifstream
步骤相似,有三种读取数据的方法
1 |
|
4 string 流
sstream头文件定义了三个类型来支持内存IO,这些类型可以向string写入数据,
从string读取数据,就像string是一个IO流一样。
istringstream从string读取数据ostringstream向string写入数据stringstream既可从string读数据也可向string写数据。

当我们想对整行文本进行处理,同时对行内每个单词进行处理时可以使用istringstream
1 | //文件内列举了姓名和他拥有的电话号码 |
5 格式控制
除了条件状态外,每个iostream对象还维护一个格式状态来控制IO如何格式化的细节。
格式状态控制格式化的某些方面,如整型值是几进制、浮点值的精度、一个输出元素的宽度等。
标注库定义了一组操纵符来修改流的格式状态。

- 一个操纵符是一个函数或者是一个对象,会影响流的状态,并能用作输入或输出运算符的运算对象。
- 类似输入和输出运算符,操纵符也返回它所处理的流对象,因此我们可以在一条语句中组合操纵符和数据。
操作符用于两大类输出控制:控制数值的输出形式以及控制补白的数量和位置。
大多数改变格式状态的操纵符都是设置/复原成对的,当操纵符改变流的格式状态时,通常改变后的状态对所有后续IO都生效。
例:
1 | //boolalpha控制布尔值的格式 |
1 | //指定整型值的进制 |
八、动态内存
到目前为止,我们编写的程序中所使用的对象都有着严格定义的生存期。
全局对象:在程序启动时分配,在程序结束时销毁。
局部自动对象:当我们进入其定义所在的程序块时被创建,在离开块时销毁。
局部static对象:在第一次使用前分配,在程序结束时销毁。
[!NOTE] 自动对象
只有当定义它的函数被调用时才存在的对象称为自动对象。
除了自动和static对象外,C++还支持动态分配对象。动态分配的对象的生存期与它们在哪里创建是无关的,只有当显式地被释放时,这些对象才会销毁。
动态对象的正确释放被证明是编程中极其容易出错的地方。为了更安全地使用动态对象,标准库定义了两个智能指针类型来管理动态分配的对象。当一个对象应该被释放时,指向它的智能指针可以确保自动地释放它。
我们的程序到目前为止只使用过静态内存或栈内存。
静态内存:保存局部static对象、类static数据成员以及定义在任何函数之外的变量。
栈内存:保存定义在函数内的非static对象。
分配在静态或栈内存中的对象由编译器自动创建和销毁。对于栈对象,仅在其定义的程序块运行时才存在:static对象在使用之前分配,在程序结束时销毁。
除了静态内存和栈内存,每个程序还拥有一个内存池。
这部分内存被称作自由空间(free store)或堆(heap):程序用堆来存储动态分配(dynamically allocate)的对象,即那些在程序运行时分配的对象。动态对象的生存期由程序来控制,也就是说,当动态对象不再使用时,我们的代码必须显式地销毁它们。
new:在动态内存中为对象分配空间并返回一个指向该对象的指针
delete:接受一个动态对象的指针,销毁该对象,并释放与之关联的内存
[!bug] 手动释放内存很不安全
忘记释放内存:内存泄漏
尚有指针引用内存的情况下释放了内存:产生引用非法内存的指针
手动管理内存
new动态分配和初始化对象
在自由空间分配的内存是无名的,所以new无法为其分配的对象命名,而是返回一个指向该对象的指针。
默认情况下,动态分配的对象是默认初始化的,这意味着内置类型或组合类型的对象的值是未定义的,类类型用默认构造函数初始化
1 | // 默认初始化 |
动态分配 const 对象
合法
1 | const int *pci = new const int(1024); //分配并初始化一个const int |
内存耗尽
内存不能分配所要求的内存空间,会抛出bad_alloc的异常,可以使用定位new(pacement new) 的方式阻止抛出异常。
1 | //如果分配失败,new返回一个空指针 |
delete释放动态内存
delete销毁给定的指针指向的对象,释放对应的内存。
1 | delete p; //p必须指向一个动态分配的对象或是一个空指针 |
释放一块非new分配的内存,或将相同的指针值释放多次,其行为是未定义的。
自定义内存分配细节
某些应用程序对内存分配有特殊的需求,因此我们无法将标准内存管理机制直接应用于这些程序。它们常常需要自定义内存分配的细节,比如使用关键字 new 将对象放置在特定的内存空间中。为了实现这一目的,应用程序需要重载 new 运算符和 delete 运算符以控制内存分配的过程。
重载new和delete
重载 new 和 delete 运算符与重载其他运算符的过程区别很大。
首先要了解这两个表达式的工作机理。
1 | string *sp = new string("a value"); //初始化单个string对象 |
使用 new 操作符来分配对象内存时会经历三个步骤:
- 调用
operator new或operator new[]函数分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。 - 编译器运行相应的构造函数以构造对象,并为其传入初始值。
- 对象被分配空间并构造完成后,返回一个指向该对象的指针。
使用 delete 操作符来释放对象内存时会经历两个步骤:
- 调用对象的析构函数。
- 编译器调用
operator delete或operator delete[]函数释放内存空间。
[!warning] 基本数据类型的 new 和delete
对于基本数据类型对象使用 new 和 delete 操作符,不会调用构造和析构函数
如果应用程序希望控制内存分配的过程,则它们需要定义自己的 operator new 函数和 operator delete 函数。
可以将函数定义在全局作用域或定义为成员函数。 如果被分配(释放)的对象是类类型,则编译器首先在类及其基类的作用域中查找。此时如果该类含有 operator new 成员或 operator delete 成员,则相应的表达式将调用这些成员。否则,编译器在全局作用域查找匹配的函数。此时如果编译器找到了用户自定义的版本,则使用该版本执行 new 表达式或 delete 表达式; 如果没找到,则使用标准库定义的版本。我们还可以通过 ::new 和 ::delete 直接调用全局作用域中的重载函数。
标准库定义了 operator new 函数和 operator delete 函数的 8 个重载版本。其中前 4 个版本可能抛出 bad_alloc异常,后 4 个版本则不会抛出异常:

定位 new 表达式
P729
placement new
定位 new 允许我们在一个预先分配的内存地址上构造对象
形式如下:
1 | new (place_address) type |
place_address 为一个指针,代表一块内存的地址。
当仅通过一个地址值调用时,定位 new 使用调用特殊的 operator new,也就是下面这个版本:
1 | void * operator new (size_t,void *) //不允许重定义这个版本的operator new |
这个 operator new 不分配任何的内存,它只是简单地返回指针实参,然后 new 表达式负责在 place_address 指定的地址进行对象的初始化工作。
例如:我们没有为 entity 对象开辟新内存,而是使用已分配的内存。
1 | int* b = new int[50]; |
【C++11】智能指针
#智能指针
类似vector,智能指针也是模板。
智能指针(smart pointer):自动释放所指向的对象,避免程序员忘记释放申请的空间
shared_ptr:允许多个 shared_ptr 指针指向同一个对象,增加引用计数,一旦最后一个 shared_ptr 被销毁,对象就会被释放。
unique_ptr:一对一,独占一个对象,当unique_ptr被销毁时,它所指向的对象也被销毁。
weak_ptr:一种弱引用。指向一个shared_ptr管理的对象,不控制所指向对象的生存期,不会改变shared_ptr的引用计数。一旦最后一个shared_ptr被销毁,对象就会被释放,即使有weak_ptr指向该对象。
[!warning] 注意:智能指针也不能乱用
优先使用
unique_ptr,因为它有一个较低的开销,但如果你需要在对象之间共享,不能使用unique_ptr的时候,就使用shared_ptr智能指针可以提供对动态分配的内存安全而又方便的管理,但这建立在正确使用的前提下。
为了正确使用智能指针,我们必须坚持一些基本规范:
- 不使用相同的内置指针值初始化(或reset)多个智能指针。
- 不delete get()返回的指针。
- 不使用get()初始化或reset另一个智能指针。
- 如果你使用get()返回的指针,记住当最后一个对应的智能指针销毁后,你的指针就变为无效了。
- 如果你使用智能指针管理的资源不是new分配的内存,记住传递给它一个删除器(deleter)。
操作
通用操作

shared_ptr独有操作

定义和改变shared_ptr的方法

[!NOTE] 删除器(deleter)
上图中参数d更换为一个自定义的释放智能指针的函数,这个函数就是删除器
unique_ptr独的操作

weak_ptr独有操作

shared_ptr类
1 | //默认初始化,空指针 |
make_shared函数
最安全的分配和使用动态内存的方法
1 | //指向一个值为42的int的shared ptr |
shared_ptr的拷贝和赋值
当进行拷贝或赋值操作时,每个share_ptr都会记录有多少个其他shared_ptr指向相同的对象:
1 | auto p = make_shared<int>(42): //p指向的对象只有p一个引用者 |
每个shared_ptr指向的对象都有一个关联的计数器,通常称其为**引用计数(reference count)**。无论何时我们拷贝一个指向该对象的shared_ptr,计数器都会递增。
计数器递增:
- 用一个shared_ptr初始化另一个shared_ptr
- 将shared_ptr作为参数传递给一个函数,函数调用实参会拷贝一次
- shared_ptr作为函数的返回值时
计数器递减:
- 给shared_ptr赋予一个新值
- shared_ptr被销毁(例如一个局部的shared ptr离开其作用域)
一旦计数器变为0,它就会自动释放自己所管理的对象:
1 | auto r=make_shared<int>(42);//r指向的int只有一个引用者 |
shared_ptr自动销毁所管理的对象
通过析构函数实现,析构函数控制对象销毁时做什么操作。
shared_ptr自动释放相关联的内存
[!warning] 容器存放动态指针
如果你将shared_ptr存放于一个容器中,而后不再需要全部元素,而只使用其中一部分,要记得用erase删除不再需要的shared_ptr元素。
shared_ptr和new结合使用
1 | //可以用new返回的指针来初始化智能指针 |
接受指针参数的智能指针构造函数是 explicit(显式)的,禁止隐式转换,只能进行直接初始化,不能拷贝初始化。
1 | shared_ptr<int> p1 = new int(1024); //错误:不能将一个内置指针隐式转换为一个智能指针,不能拷贝初始化 |
相同的原因,一个返回shared_ptr的函数不能在其返回语句中隐式转换一个普通指针:
1 | shared_ptr<int> clone(int p) |
默认情况下,一个用来初始化智能指针的普通指针必须指向动态内存,因为智能指针默认使用delete释放它所关联的对象。
我们可以将智能指针绑定到一个指向其他类型的资源的指针上,但是为了这样做,必须提供自己的操作来替代delete,使用第二个谓词。
[!bug] 警告
不要混合使用普通指针和智能指针,上述结合使用会引发错误,建议使用make_shared而不是new不要使用get初始化另一个智能指针或为智能指针赋值,get返回一个内置指针指向智能指针管理的对象
其他shared_ptr操作
reset将一个新的指针赋予一个shared_ptr:
1 | p = new int (1024); //错误:不能将一个指针赋予shared_ptr |
reset会更新引用计数,经常与unique一起使用,来控制多个shared_ptr共享的对象。
1 | if (!p.unique()) |
【C++11】enable_shared_from_this
C++11 开始支持 enable_shared_from_this,它是一个模板类,定义在头文件 <memory>,其原型为:template< class T > class enable_shared_from_this;
从名字可以看出几个关键词:enable: 允许 shared 指 shared_ptr, from_this 则是指从类自身 this 构造 shared_ptr
std::enable_shared_from_this 能让其一个对象(假设其名为 t ,且已被一个 std:: shared_ptr 对象 pt 管理)安全地生成其他额外的 std::shared_ptr 实例(假设名为 pt1, pt2, … ),它们与 pt 共享对象 t 的所有权。
例如:若一个类 T 继承自 std::enable_shared_from_this<T> ,则 T 类中有继承自父类的成员函数: shared_from_this 。当 T 类的对象 t 被一个为名为 pt 的 std:: shared_ptr 类对象管理时,调用 T:: shared_from_this 成员函数,将会返回一个新的 std:: shared_ptr 对象,它与 pt 共享 t 的所有权。
为什么要用 ?
- 需要在类对象的内部中获得一个指向当前对象的 shared_ptr 对象。
- 如果在一个程序中,对象内存的生命周期全部由智能指针来管理。在这种情况下,要在一个类的成员函数中,对外部返回 this 指针就成了一个很棘手的问题。
什么时候用?
- 当一个类被共享智能指针
share_ptr管理,且在类的成员函数里需要把当前类对象作为参数传给其他函数时,这时就需要传递一个指向自身的share_ptr。 - 当你需要在类的成员函数内部创建指向当前对象的
std:: shared_ptr,例如在回调函数或事件处理中。
如何安全地将 this 指针返回给调用者?
一般来说,我们不能直接将 this 指针返回。如果函数将 this 指针返回到外部某个变量保存,然后这个对象自身已经析构了,但外部变量并不知道,此时如果外部变量再使用这个指针,就会使得程序崩溃。
标准库中的源码
1 | template<typename _Tp> |
- enable_shared_from_this 类中的成员函数
- (constructor):构造一个 enable_shared_from_this 对象,是一个受保护的成员函数,成员属性为
protected。 - (destructor):销毁一个 enable_shared_from_this 对象,是一个受保护的成员函数,成员属性为
protected。 - operator=:返回到 this 的引用,是一个受保护成员函数,成员属性为
protected。 - shared_from_this:返回共享
*this指针所有权的 shared_ptr,是一个public属性的成员函数。 - weak_from_this (C++17):返回共享
*this所指针有权的 weak_ptr,是一个public属性的成员函数。
- (constructor):构造一个 enable_shared_from_this 对象,是一个受保护的成员函数,成员属性为
具体的代码示例
1 |
|
使用注意事项
enable_shared_from_this 的常见实现为:其内部保存着一个对 this 的弱引用(例如 std:: weak_ptr )。 std:: shared_ptr 的构造函数检测无歧义且可访问的 (C++17 起) enable_shared_from_this 基类,并且若内部存储的弱引用没有被以存在的 std:: shared_ptr 占有,则 (C++17 起) 赋值新建的 std:: shared_ptr 为内部存储的弱引用。为另一个 std:: shared_ptr 所管理的对象构造一个 std:: shared_ptr ,将不会考虑内部存储的弱引用,从而将导致未定义行为 (undefined behavior)。
只允许在先前已被 std:: shared_ptr 管理的对象上调用 shared_from_this 。否则调用行为未定义 (C++17 前) 抛出 std:: bad_weak_ptr 异常(通过 shared_ptr 从默认构造的 weak_this 的构造函数) (自 C++17 起)。
enable_shared_from_this 提供安全的替用方案,以替代 std:: shared_ptr (this) 这样的表达式(这种不安全的表达式可能会导致 this 被多个互不知晓的所有者析构)。
unique_ptr类
初始化
接受指针参数的智能指针构造函数是explicit(显示)的,禁止隐式转换,只能进行直接初始化,不能拷贝初始化。
当我们定义一个 unique_ptr 时,需要将其绑定到一个 new 返回的指针上
1 | unique_ptr<double> p1; //可以指向一个double的unique ptr |
拷贝和赋值
由于独占对象,所以unique_ptr不支持普通的拷贝或赋值
1 | unique_ptr<string> p1(new string("Stegosaurus")); |
例外:我们可以拷贝或赋值一个将要被销毁的unique_ptr
1 | //1. 从函数返回一个unique_ptr |
转移对象
通过release或reset将指针的所有权从一个(非const)unique_ptr转移给另一个unique_ptr:
1 | //将所有权从p1(指向string Stegosaurus)转移给p2 |
release返回的是unique_ptr<string>::pointer类型的指针,是一个string*类型的普通指针,需要手动释放。
1 | p2.release(); //错误 |
weak_ptr类
创建一个weak_ptr时,要哟个一个shared_ptr来初始化它:
1 | auto p = make_shared<int>(42); |
lock检查指向的对象是否存在,如果存在,lock返回一个指向共享对象的shared_ptr,这样可以保证访问对象是安全的。
1 | if(shared_ptr<int> np = wp.lock()) //如果np不为空则条件成立 |
动态数组
new和delete一次都是操作一个对象
C++提供两种一次分配一个对象数组的方法
[!warning]
大多数应用应该使用标准库容器而不是动态分配的数组。使用容器更为简单
更不容易出现内存管理错误并且可能有更好的性能。
new/delete数组
用new分配一个动态数组,后面要跟方括号,指明分配数量,必须为整型。
new返回一个指向数组元素类型的指针,而不是数组类型
1 | int *p = new int[1024]; //p指向第一个int |
[!warning]
动态数组并不是数组类型,不支持begin、end、范围for循环
初始化
1 | int *p1= new int[10]; //默认初始化,10个未初始化的int |
unique_ptr管理动态数组
标准库提供了一个可以管理new分配的动态数组的unique_ptr版本
1 | //up指向一个包含10个未初始化int的数组 |
unique_ptr 指向数组(不是对象),不能用点和箭头运算符,但可以用下标运算符访问数组元素
1 | for (size_t i=0;i !10;++i) |
shared_ptr若要管理动态数组,必须提供自定义的删除器
1 | shared ptr<int>sp(new int[10], [](int *p) {delete[] p;}) |
shared_ptrmei没有定义下标运算符,可以用get获取一个内置指针,用它来访问数组元素
1 | //shared ptr未定义下标运算符,并且不支持指针的算术运算 |
allocator类
new、delete将内存分配/释放和对象构造/销毁组合在了一起,不太灵活。
- allocator类将内存分配和对象构造分离
- allocator类也是一个模板

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18allocator<string> alloc; //可以分配string的allocator对象
auto const p = alloc.allocate(n); //为n个未初始化的string分配内存
auto q = p; //q指向最后构造的元素之后的位置
alloc.construct(q++); //*q为空字符串
alloc.construct(q++,10,'c'); //*q为cccccccccc
alloc.construct(q++,"hi"); //*q为hi!
//不能使用未构造的内存
cout<< *p <<endl; //正确:p已经分配内存,使用string的输出运算符
cout<< *g <<endl; //错误:q指向未构造的内存!
//用完之后使用destroy销毁构造的对象
while (q != p)
alloc.destroy(--q); //释放我们真正构造的string
//销毁后内存可以保存其他string,或者释放内存
alloc.deallocate(p, n);
拷贝和填充未初始化内存
九、重载运算符与函数对象

[!NOTE] Title
当一个重载运算符是成员函数时,this绑定到左侧运算对象。成员运算符函数的(显式)参数数量比运算对象的数量少一个。
- 对于一个运算符函数来说,它或者是类的成员,或者至少含有一个类类型的参数:这一约定意味着当运算符作用于内置类型的运算对象时,我们无法改变该运算符的含义。
1
2//错误:不能为int重定义内置的运算符
int operator+(int, int); - 我们只能重载已有的运算符,不能发明新的运算符号。
- 可以直接调用一个重载的运算符函数
1
2
3
4
5
6
7//调用非成员函数operator+
datal + data2; //普通的表达式
operator+(datal,data2); //等价的函数调用
//调用成员函数operator+=
data1 += data2; //基于“调用”的表达式
data1.operator+=(data2); //对成员运算符函数的等价调用,将this绑定到data1地址,将data2作为实参传入了函数。
1 输入输出运算符
输出运算符<<重载
第一个形参是(非常量)ostream对象的引用
第二个形参是一个常量的引用,该常量是我们想要打印的类类型
1 | ostream &operator<<(ostream &os,const Sales data &item) |
[!NOTE]
- 输出运算符应该负责打印对象的内容而非控制格式,输出运算符不应该打印换行符。
- 自定义IO运算符,必须将其定义为非成员函数
- IO运算符通常需要读写类的非公有数据成员,所以一般声明为友元
输入运算符>>重载
第一个形参是运算符将要读取的流的引用
第二个形参是将要读入的(非常量)对象的引用
1 | istream &operator>>(istream &is, Sales data &item) |
[!NOTE]
输入运算符必须处理输入可能失败的情况,输出运算符不需要。
当读取操作发生错误时,输入运算符应该负责从错误中恢复。
2 算术和关系运算符
通常情况下定义为非成员函数以允许对左侧或右侧的运算对象进行转换。
运算符一般不需要改变运算对象的状态,所以形参都是常量的引用
相等运算符 == 和!=
1 |
|
关系运算符
如<
3 赋值运算符=
[!NOTE]
赋值运算符必须定义为成员函数
1 | class StrVec |
复合赋值运算符+=
1 | // 作为成员的二元运算符:左侧运算对象绑定到隐式的this指针 |
[!NOTE]
赋值运算符必须定义成类的成员,复合赋值运算符通常情况下也应该这样做。
这两类运算符都应该返回左侧运算对象的引用。
4 下标运算符 []
表示容器的类通常可以通过元素在容器中的访问元素,这些类一般会定义下标运算符operator[]
[!NOTE]
- 下标运算符必须是成员函数
- 下标运算符通常重载两个版本:一个返回普通引用,另一个是类的常量成员并且返回常量引用。
举个例子,我们按照如下形式定义StrVec(参见13.5节,第465页)的下标运算符:
1 | class StrVec |
上面这两个下标运算符的用法类似于vector或者数组中的下标。因为下标运算符返回的是元素的引用,所以当StrVec是非常量时,我们可以给元素赋值:而当我们对常量对象取下标时,不能为其赋值:
1 | //假设svec是一个非const StrVec对象 |
5 递增递减运算符
[!NOTE]
建议设定为成员函数
同时定义前置和后置两个版本
- 前置运算符返回递增或递减后的原对象的引用
- 后置运算符返回对象的原值(递增或递减之前的值)
1 | class StrBlobptr |
6 成员访问运算符 * 和->
[!NOTE] Title
箭头运算符->必须是类的成员,解引用运算符 * 不一定
重载的箭头运算符必须返回类的指针或者自定义了箭头运算符的某个类的对象
1 | class StrBlobptr |
7 函数对象(仿函数)与函数调用运算符()
#函数对象 #仿函数
- 重载
函数调用运算符()的类,其对象常称为函数对象 (function object),也叫仿函数 (functor),使得类对象可以像函数那样调用。 - STL 提供的算法往往有两个版本,一种是按照我们常规默认的运算来执行,另一种允许用户自己定义一些运算或操作,通常通过回调函数或模版参数的方式来实现,此时 functor 便派上了用场,特别是作为模版参数的时候,只能传类型。
- 函数对象超出了普通函数的概念,其内部可以拥有自己的状态 (其实也就相当于函数内的 static 变量),可以通过成员变量的方式被记录下来。
- 函数对象可以作为函数的参数传递。
- 函数对象通常不定义构造和析构函数,所以在构造和析构时不会发生任何问题,避免了函数调用时的运行时问题。
- 模版函数对象使函数对象具有通用性,这也是它的优势之一。
- STL 需要我们提供的 functor 通常只有一元和二元两种。
- lambda 表达式的内部实现其实也是仿函数
[!NOTE] Title
函数调用运算符必须是成员函数。一个类可以定义多个不同版本的调用运算符,相互之间应该在参数数量或类型上有所区别。
即使 absnum 只是一个对象而非函数,我们也能“调用”该对象。调用对象实际上是在运行重载的调用运算符。在此例中,该运算符接受一个 int 值并返回其绝对值:
1 | //下面这个名为absInt的struct含有一个调用运算符,该运算符负责返回其参数的绝对值: |
函数对象常常作为泛型算法的实参,例如使用标准库for_each算法
1 | for_each(vs.begin(),vs.end(),absInt()); //第三个实参是类型absInt的一个临时对象 |
STL 内置函数对象
#greater
使用时需要包含头文件 <functional>
STL 内建了一些函数对象,分为:
- 算术类函数对象
- 关系运算类函数对象
- 逻辑运算类函数对象
算术类函数对象
1 | template<class T> T plus<T>; // 加法仿函数 |
negate 是一元运算,其他都是二元运算。
关系运算类函数对象
1 | template<class T> bool equal_to<T>; // 等于 |
逻辑运算类运算函数
1 | template<class T> bool logical_and<T>; // 逻辑与 |
用法
1 | plus<int> intAdd; //可执行int加法的函数对 |
这些函数对象通常用来替换算法中的默认运算符。
1 | //默认下排序算法使用<运算符按升序排列 |
仿函数的优缺点
优点:
1)仿函数比函数指针的执行速度快,函数指针时通过地址调用,而仿函数是对运算符 operator 进行自定义来提高调用的效率。
2)仿函数比一般函数灵活,可以同时拥有两个不同的状态实体,一般函数不具备此种功能。
3)仿函数可以作为模板参数使用,因为每个仿函数都拥有自己的类型。
缺点:
1)需要单独实现一个类。
2)定义形式比较复杂。
仿函数作用
仿函数通常有下面四个作用:
1)作为排序规则,在一些特殊情况下排序是不能直接使用运算符<或者>时,可以使用仿函数。
2)作为判别式使用,即返回值为bool类型。
3)同时拥有多种内部状态,比如返回一个值得同时并累加。
4)作为算法 for_each 的返回值使用。
8 【C++11】 std:: function 与可调用对象
可调用对象
#可调用对象
对于一个对象或一个表达式,如果可以对其使用调用运算符(),则称它为可调用的。
[!NOTE] 可调用对象
可调用对象有四种:
- 函数
- 函数指针
- 重载了函数调用运算符的类
operator(), 即函数对象(仿函数)[[#7 函数对象(仿函数)与函数调用运算符()]]- lambda 表达式 [[#【C++11】lambda表达式]]
- bind 创建的对象 [[2 STL标准库#【C++11】参数绑定 bind 函数]] ^snr6wf
和其他对象一样,可调用的对象也有类型。例如,每个 lambda 有它自己唯一的(末命名)类类型:函数及函数指针的类型则由其返回值类型和实参类型决定,等等。
然而,不同类型的可调用对象却可能共享同一种调用形式。调用形式指明了调用返回的类型以及传递给调用的实参类型。一种调用形式对应一个函数类型,例如:int (int,int) 是一个函数类型,它接受两个 int、返回一个 int。
不同类型的相同调用形式
对于几个可调用对象共享同一种调用形式的情况,有时我们会希望把它们看成具有相同的类型。例如,考虑下列不同类型的可调用对象:
1 | //普通函数 |
上面这些可调用对象分别对其参数执行了不同的算术运算,尽管它们的类型各不相同,但是共享同一种调用形式:int (int,int)
[!NOTE] 函数表
我们可能希望使用这些可调用对象构建一个简单的桌面计算器。为了实现这一目的,需要定义一个函数表用于存储指向这些可调用对象的“指针”。当程序需要执行某个特定的操作时,从表中查找该调用的函数。
在 C++中,函数表很容易通过 map 来实现。
对于此例来说,我们使用一个表示运算符符号的 string 对象作为关键字; 使用实现运算符的函数作为值。当我们需要求给定运算符的值时,先通过运算符索引 map,然后调用找到的那个元素。
假定我们的所有函数都相互独立,并且只处理关于 int 的二元运算,则 map 可以定义成如下的形式:
1 | //构建从运算符到函数指针的映射关系,其中函数接受两个 int、返回一个 int |
我们可以按照下面的形式将 add 的指针添加到 binops 中:
1 | //正确: add 是一个指向正确类型函数的指针 |
但是我们不能将 mod 或者 divide 存入 binops。问题在于 mod 是个 lambda 表达式,而每个 lambda 有它自己的类类型,该类型与存储在 binops 中的值的类型不匹配。
1 | binops.insert( {"%", mod} ); //error |
我们可以使用 function 标准库类型来解决这个问题。
std:: function 偏函数
#function
又称偏函数(partial function)
function就是可调用对象的封装器,可以把function看做一个函数对象,用于表示函数这个抽象概念。function的实例可以存储、复制和调用任何可调用对象,存储的可调用对象称为function的目标,- 若
function不含目标,则称它为空,调用空的function的目标会抛出bad_function_call异常。
常用function类型来定义函数表。
接着讨论上一节的例子。
在这里我们声明了一个 function 类型,它可以表示接受两个 int、返回一个 int 的可调用对象。因此,我们可以用这个新声明的类型表示任意一种桌面计算器用到的类型;
1 | //function<返回值类型(参数一类型,参数二类型)> |
使用这个 function 类型可以重新定义 map:
1 | //列举了可调用对象与二元运算符对应关系的表格 |
我们能把所有可调用对象都添加到这个 map 中:
1 | map<string,function<int (int, int)>> binops = |
一如往常,当我们索引 map 时将得到关联值的一个引用。如果我们索引 binops,将得到 function 对象的引用。function 类型重载了调用运算符,该运算符接受它自己的实参然后将其传递给存好的可调用对象:
1 | binops ["+"](10,5); //调用 add (10,5) |
我们依次调用了 binops 中存储的每个操作。在第一个调用中,我们获得的元素存放着一个指向 add 函数的指针, 因此调用 binops [ "+"](10,5) 实际上是使用该指针调用 add, 并传入 10 和 5。在接下来的调用中, binops["-"]返回一个存放着 std::minus<int>类型对象的 function,我们将执行该对象的调用运算符。
重载的函数与 function
我们不能(直接)将重载函数的名字存入 function 类型的对象中:
1 | int add (int i, int j){ return i +j;} |
解决上述二义性问题的一条途径是存储函数指针而非函数的名字:
1 | int (*fp) (int,int) = add; //指针所指的add是接受两个int的版本 |
同样,我们也能使用 lambda 来消除二义性:
1 | //正确: 使用 lambda 来指定我们希望使用的 add 版本 |
十一、命名空间
大型程序使用多个库,难免命名冲突,命名空间就是防止名字冲突的机制。
命名空间分割了全局命名空间,其中每个命名空间是一个作用域。通过在某个命名空间中定义库的名字,库的作者(以及用户)可以避免全局名字固有的限制。
命名空间定义
命名空间的定义包含两部分:关键字namespace和命名空间的名字
只要能出现在全局作用域中的声明就能置于命名空间内,主要包括:类、变量(及其初始化操作)、函数(及其定义)、模板和其他命名空间
1 | namespace cplusplus_primer |
全局命名空间
全局命名空间以隐式的方式声明,并且在所有程序中都存在。全局作用域中定义的名字被隐式的添加到全局命名空间中。
1 | ::member_name //表示全局命名空间中的一个成员 |
嵌套命名空间
顾名思义,在命名空间中定义命名空间
1 | namespace cplusplus_primer |
【C++11】内联命名空间
和普通的嵌套命名空间不同,内联命名空间可以被外层命名空间直接使用。也就是说,我们无需在内联命名空间的名字前添加表示该命名空间的前缀,通过外层命名空间就可以直接访问。
1 | namespace cplusplus_primer |
未命名的命名空间
未命名的命名空间中定义的变量拥有静态生命周期:它们在第一次使用前创建,并且直到程序结束才销毁。
一个未命名的命名空间可以在某个给定的文件内不连续,但是不能跨越多个文件。
每个文件定义自己的未命名的命名空间,如果两个文件都含有未命名的命名空间,则这两个空间互相无关。在这两个未命名的命名空间中可以定义相同的名字,并且这些定义表示的是不同实体。
如果一个头文件定义了未命名的命名空间,则该命名空间中定义的名字将在每个包含了该头文件的文件中对应不同实体。
[!NOTE]
和其他命名空间不同,未命名的命名空间仅在特定的文件内部有效,其作用范围不会横跨多个不同的文件。
定义在未命名的命名空间中的名字可以直接使用,毕竟我们找不到什么命名空间的名字来限定它们。同样的,我们也不能对未命名的命名空间的成员使用作用域运算符。
未命名的命名空间中定义的名字的作用域与该命名空间所在的作用域相同。如果未命名的命名空间定义在文件的最外层作用域中,则该命名空间中的名字一定要与全局作用域中的名字有所区别:
1 | int i; //i的全局声明 |
其他情况下,未命名的命名空间中的成员都属于正确的程序实体。
一个未命名的命名空间也能嵌套在其他命名空间当中。此时,未命名的命名空间中的成员可以通过外层命名空间的名字来访问:
1 | namespace local |
命名空间成员
命名空间的别名
1 | namespace primer = cplusplus_primer; //primer作为别名,更短更方便使用 |
[!NOTE]
一个命名空间可以有好几个同义词或别名,所有别名都与命名空间原来的名字等价。
using声明
前文我们通过cplusplus_primer::Query这样的方式调用成员,更简便的方法使用命名空间的成员:using声明。
一条using声明语句一次只引入命名空间的一个成员。
一条using声明语句可以出现在全局作用域、局部作用域、命名空间作用域以及类的作用域中。在类的作用域中,这样的声明语句只能指向基类成员。
1 | using std::cin; //有了using声明后续就无需使用前缀::了 |
[!warning]
头文件不应包含using声明,因为头文件的内容会拷贝到所有引用它的文件中去,会造成名字冲突。
using指示(不要使用)
和using声明不同,using指示使得某个特定命名空间中所有的名字都可见。
1 | using namespace 命名空间的名字; |
using指示可以出现在全局作用域、局部作用域和命名空间作用域中,但是不能出现在类的作用域中。
重载与命名空间
P708
十二、异常处理
C++中异常处理包括:
throw表达式
try语句块
异常类
入门:p172
深入:P684
【C++11】noexcept
#noexceptnoexcept 通知标准库我们的构造函数不抛出任何异常,必须在类头文件中的声明和定义中(如果定义在类外的话)都指定 noexcept
1 | class StrVec |
如果一个函数使用 noexcept 关键字指定为不抛出异常,而实际上在运行时抛出了异常,程序将终止。
需要注意的是,使用 noexcept 不会阻止函数抛出异常,它只是提供了一种明确的标识,并可以在一些情况下提高代码的性能和可维护性。
 微信
微信 支付宝
支付宝




