
UE实时渲染

渲染前准备
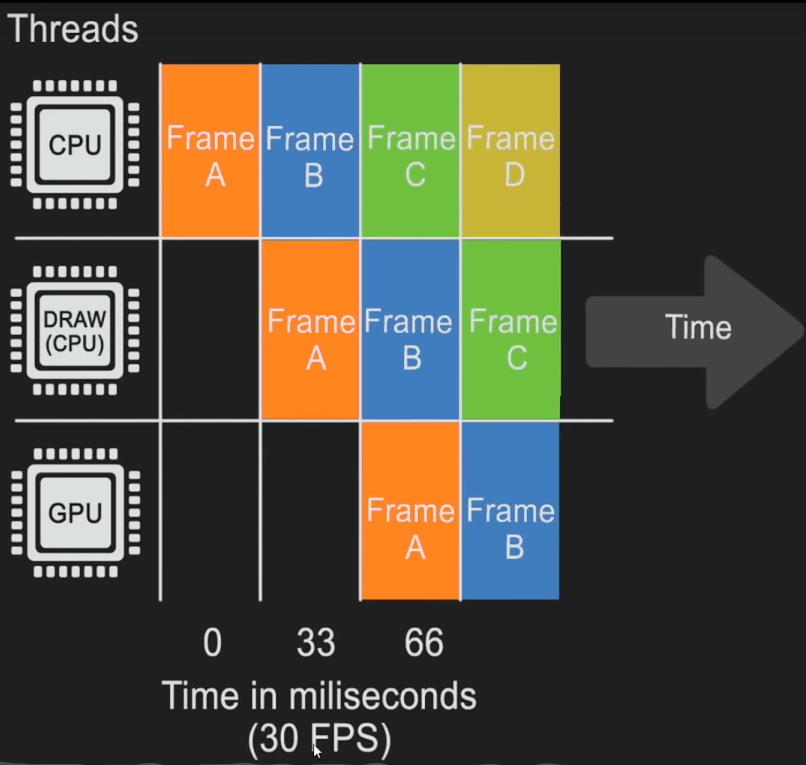
第0帧-0毫秒–游戏线程(CPU)
在开始渲染前,我们需要知道参与渲染的物体在什么位置
游戏线程执行所有逻辑计算和物体的变换
- 动画
- 模型或物体的位置物理
- Al
- 生成或销毁,隐藏或显示
- 以及其他任何与物体位置变化相关的逻辑
第1帧-33 ms-渲染线程(大部分在CPU)
至此,我们已经知道了各个物体处于什么位置
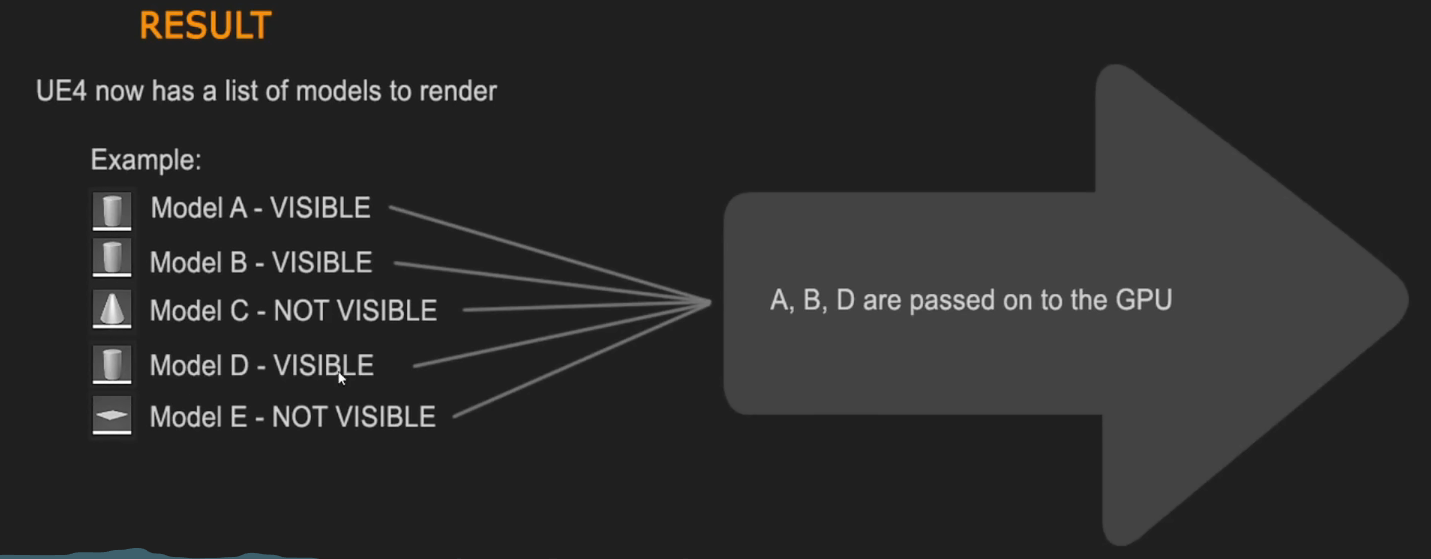
我们还需要知道哪些物体应该被渲染在画面中 → 只渲染可见的内容
部分也是在CPU上计算的,但也有部分是在GPU上计算
遮挡过程—建立一个可见物体的列表((逐物体而不是逐三角形)
分为以下4个步骤处理
- 距离剔除:根据物体与相机的距离决定是否剔除(默认未开启)
- 视锥剔除:根据物体是否在视锥内决定是否剔除
- 预计算可见性:将可见性结果提前计算好并储存下来
- 遮挡剔除:性能消耗最大,在最后才执行
遮挡过程性能提示 - 设置距离剔除
- 大于1万个物体会对性能有较大影响
- 大部分情况下CPU是瓶颈,有时候也可能是遮挡在大型开放世界通常作用比较小
- 所有的物体都会被遮挡
- 大的物体很难被遮挡,因此在GPU渲染上可能需要消耗更多时间
几何体渲染
第2帧-66 ms(GPU)
Prepass/Early z
GPU现在已经知道了需要渲染的物体的列表及其位置信息,但是如果直接渲染,会有一些像素重复绘制,造成非常大的浪费,因此我们需要找哪些模型应该先被渲染
GPU驱动会在执行像素着色器前会检查该点深度,提前跳过不符合条件的像素。
[[3 进阶应用#3.5 Early-z和Z-prepass]]
Drawcall
Drawcall是指渲染时在特定pass中采用的单一处理过程,通常可以理解为绘制拥有相同属性的一组多边形。
切换材质影响性能开销,在GPU渲染时,引擎会根据材质对物体进行排序,相同材质的会在一个批次里绘制
Drawcall 对性能有非常大的影响,GPU绘制完成后,需要从渲染线程拿新的指令,这里会有比较大性能开销,Drawcall数量对性能的影响比三角形数量要大许多。
Drawcall相关的性能提示
- Drawcall数量相比多边形数量对性能的影响更大
- 引擎有一些Drawcall的基础开销
- 为了降低Drawcall,我们可以将模型进行合并,但也有副作用
- 遮挡检测性能更差
- 计算碰撞性能更差
- 占用更多内存
- 一个较为常用的技术称为Modular Meshes
- 也可以使用Instancing降低Drawcall
- Level Of Detail (LOD)和HLOD
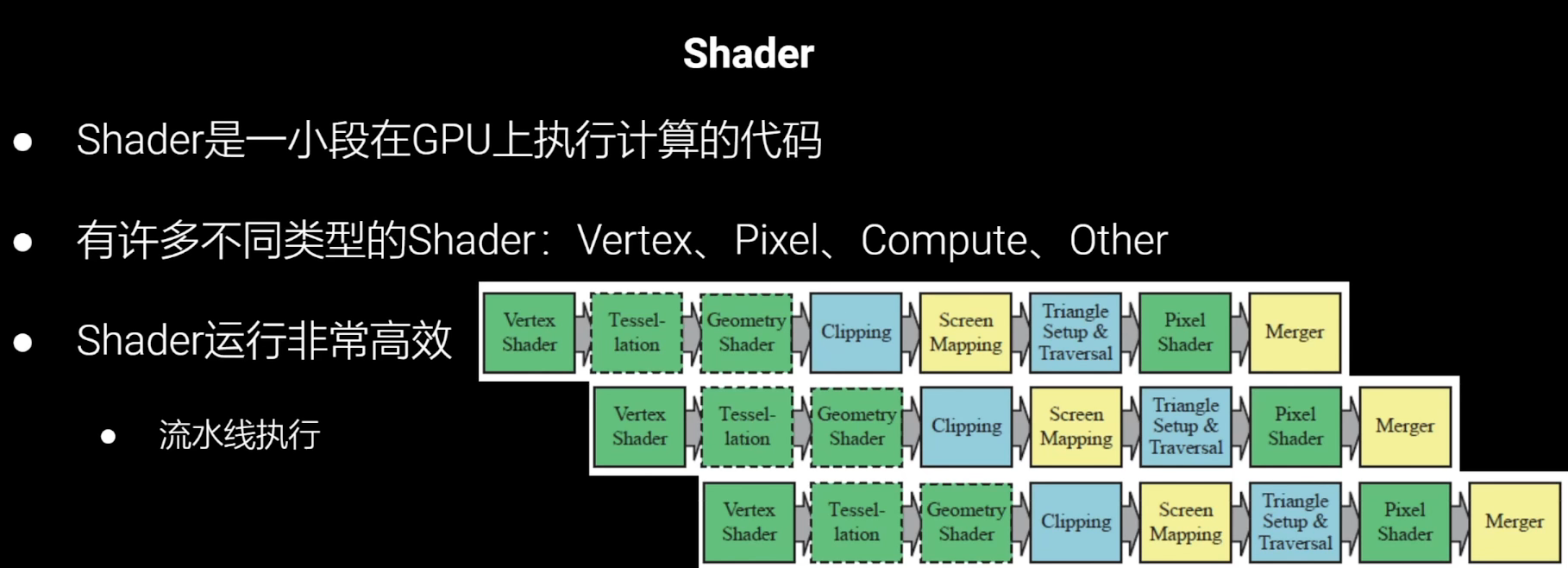
Shader
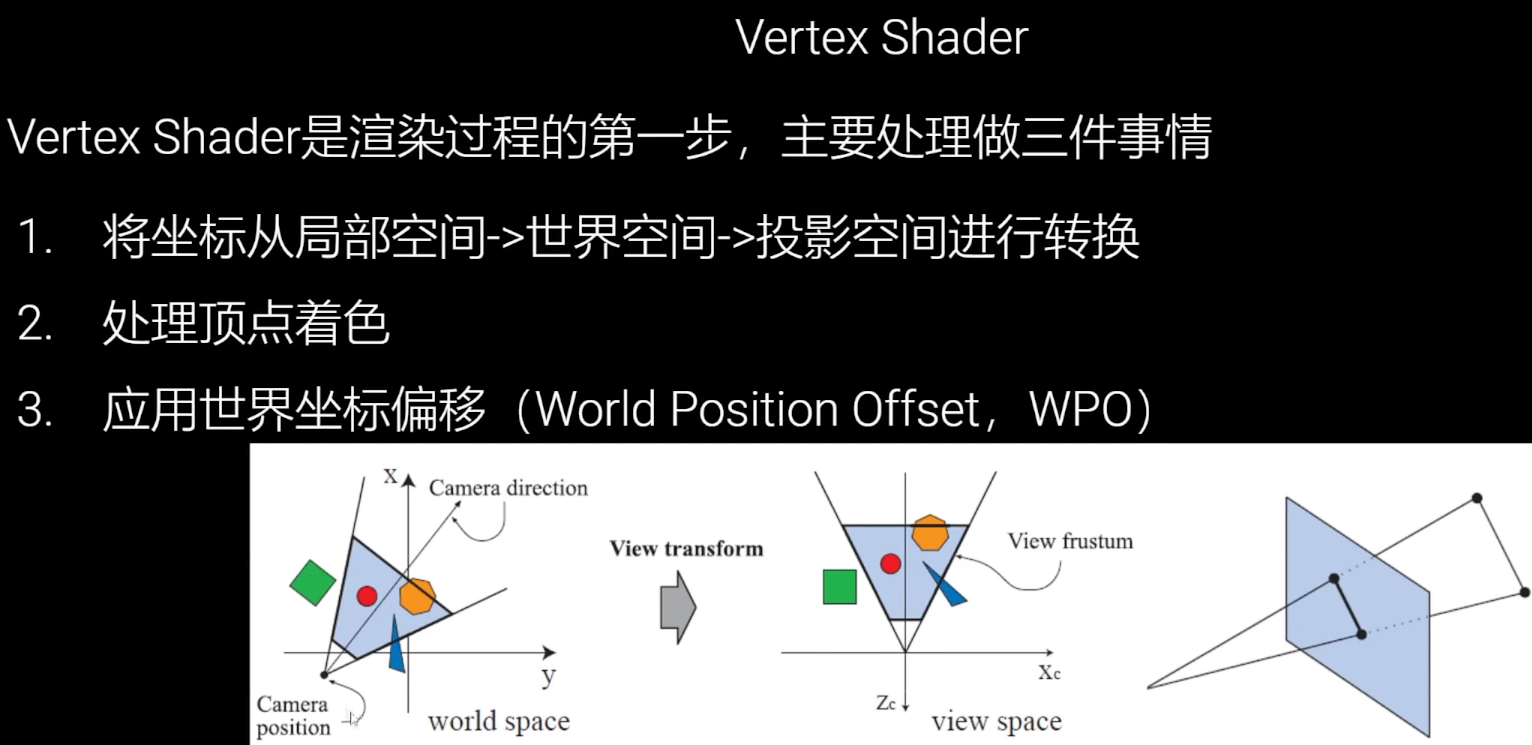
WPO: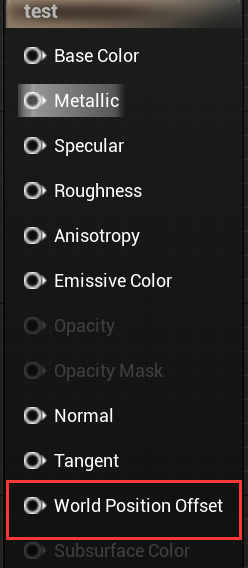
用于渲染水体表面、草的飘动、顶点动画
Shader 系统经过了高度优化,因此它是整个渲染过程的核心
- CPU无法处理如此海量的数据
- Vertex Shaders并不直接修改模型,只是视觉上的效果
- CPU无法察觉到VS对模型顶点数据的修改,因此物理和碰撞不会受任何影响
性能提示
- 动画越复杂性能越慢
- 顶点越多性能越慢
- 高精度的模型最好使用简单的Vertex shader
- 对远距离的物体禁用顶点动画
Nanite
Nanite是虚幻引擎5全新推出的虚拟几何体系统。它采用全新的内部网格体格式和渲染技术来渲染像素级别的细节以及海量的物体对象。它足够智能,可以仅处理能观察到的细节。Nanite采用高度压缩的数据格式,并且支持高细节流送和自动LOD.
- 几何体形状的复杂度提高了数个数量级; 三角形和对象的实时渲染数量达到了
- 前所未有的高度。
- 帧预算不再会因为多边形数量、绘制调用和内存使用情况而受限。
- 可以直接导入电影级品质的美术资源,例如ZBrush模型和摄影测量扫描数据通过高模实现细节,而非通过烘培法线贴图来实现。
- 自动处理LOD,不再需要手动设置
- 品质损失极少或没有损失,特别是在LOD发生过渡时
一般来说,能启用时应该尽量启用Nanite。虚幻引擎5中NaniteMesh渲染经过了高度优化,通常可以更快渲染,占用的内存和磁盘空间也更少。
具体而言,网格体如果满足以下条件,将很适合使用Nanite:
- 包含很多三角形,或屏幕上三角形非常小
- 场景中有很多实例
- 作为其他Nanite几何体的主要遮挡物

光栅化和G-Buffer
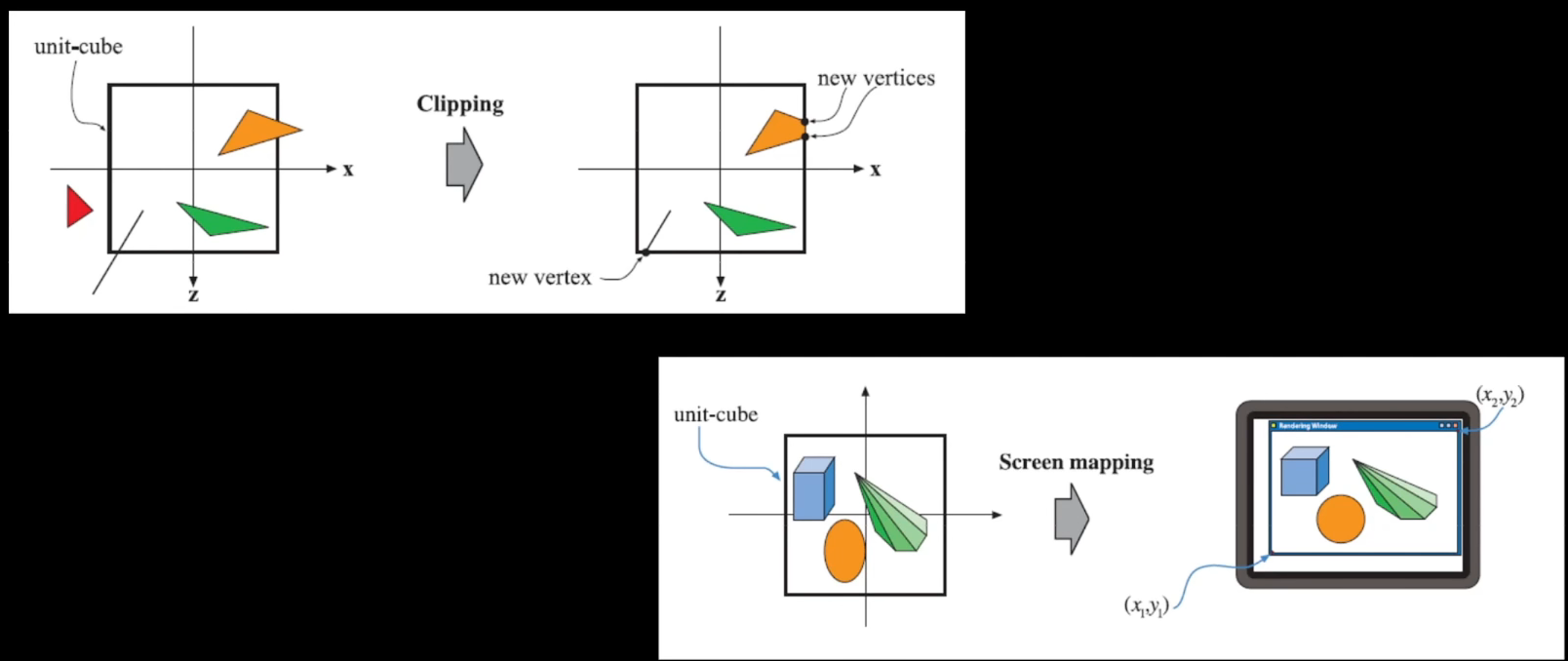
提供了变换数据、投影顶点以及必要的着色数据后,下一步是找到所有在这些三角形内部需要渲染的像素点,这个过程我们成为光栅化。
光栅化按照Drawcall的顺序逐次调用。
在远处观察一个有10万面的模型,即使最终只占了画面中的一个像素,GPU仍然会处理这10万面的数据。
Overshading: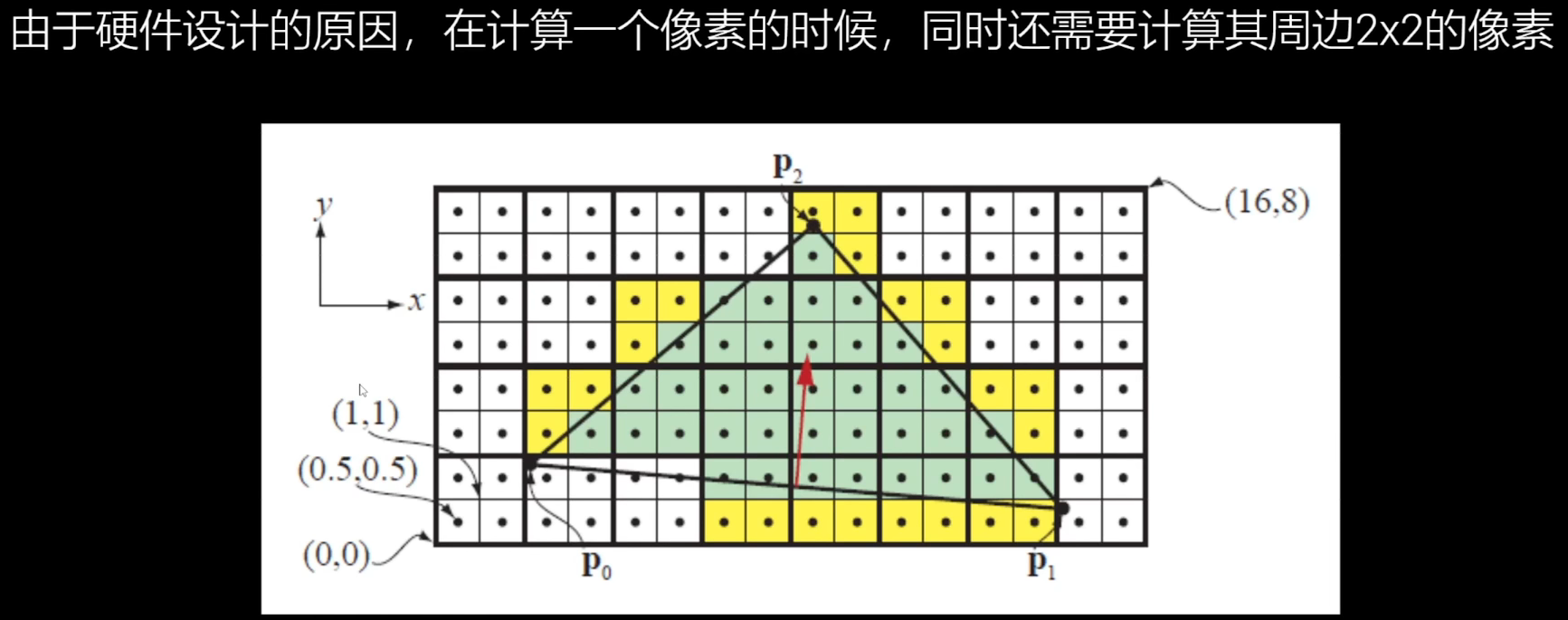
光栅化和Overshading性能提示
- 多边形越密集,渲染的开销越大
- 从更远处观察物体,多边形的密度会增加,因此可以使用LOD的方法或远距离剔除减少这部分的开销
- PixelShader越复杂,Overshading的开销也越大
- 非常细长的三角形也会造成比较严重的Overshading
G-buffer

G-Buffer会占用很多内存和带宽,因此对G-buffer的数量是有限制的。如果需要扩展G-Buffer需要考虑到这一点。
纹理
- 纹理在导入时会被压缩,可以大大减少GPU显存占用
- 不同的压缩方式,Windows上通常使用BC算法
- 法向贴图使用了特殊的压缩方式,只保留了RG通道
- Shader中对采样纹理的数量有限制
- 纹理的分辨率主要影响的是内存和带宽,而不是着色
- 使用mipmap减少摩尔纹和渲染速度
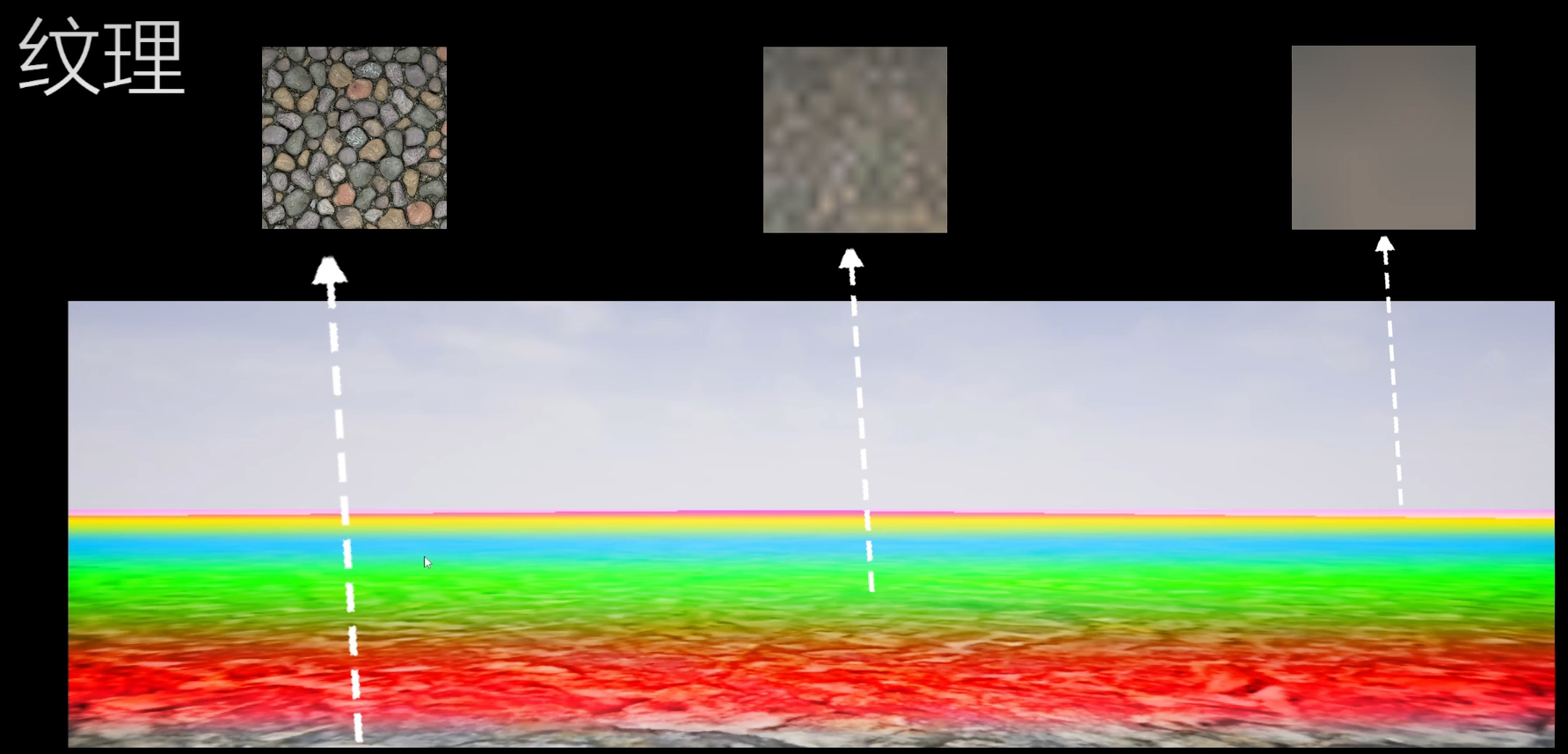
- 纹理的尺寸需要为2的幂次方,例如:1x1,2x2,4x4,8x8,16x16,32x32,16x64,4x128
- 边长不是2的幂次贴图无法生成Mipmap和过进行纹理流送
- UI贴图以不需要Mipmap
像素着色器和材质
像素着色器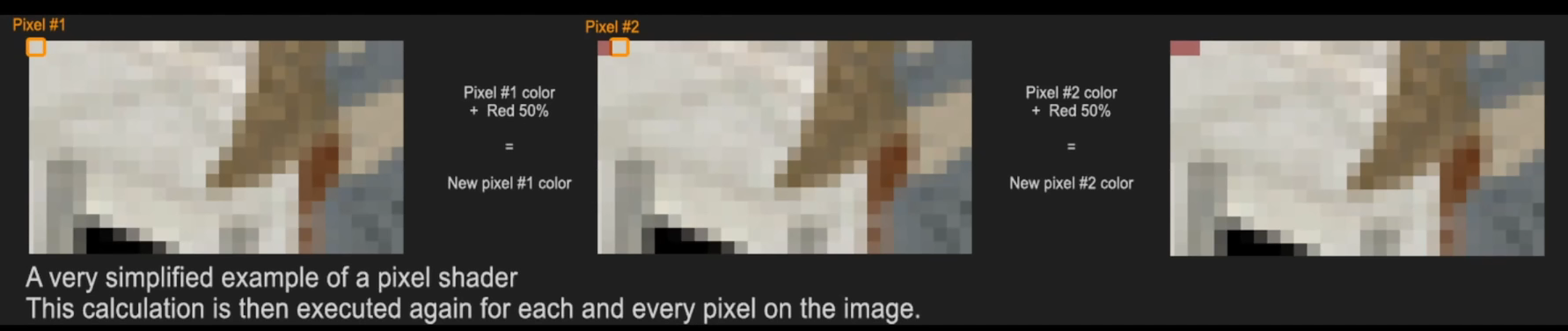
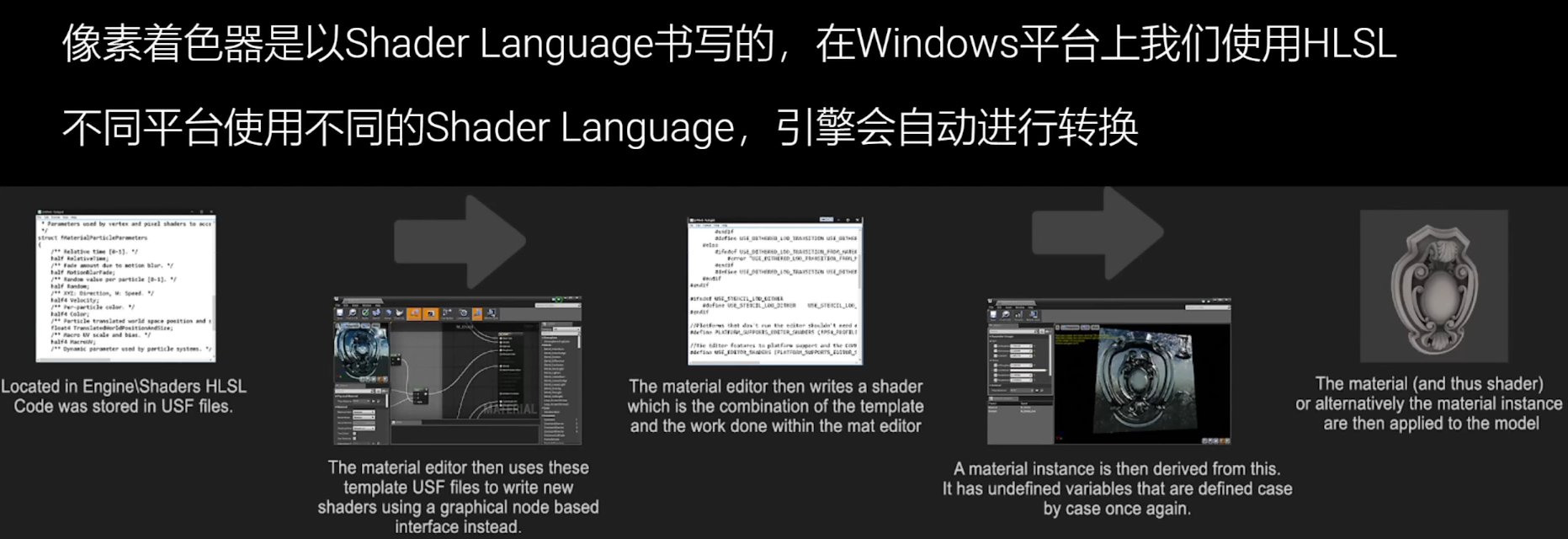
- 像素着色器(Pixel shader)与顶点着色器(Vertex shader)类似
- 在GPU上执行的程序,可以同时执行大量的简单计算,用于修改像素的颜色,对于渲染管线极为重要
- 像素着色器是材质系统的底层实现
- 同时也实现了光照、雾、后期等任何与效果相关的处理
材质
- 材质管线很大一部分都基于PBR
- PBR使用Specular/Metallic/Roughness来描述一种材质的属性
- PBR是一种统一着色模型,可以通过修改参数表现很多不同的材质
- 几乎所有的模型都是使用PBR模型进行渲染的
- 1.可以达到最快的效率
- 2.可预测性
- 3.基于G-Buffer的合成工作流限制
材质性能提示
- 每个材质的纹理采样器有最大数量限制 (16个),DX11可以使用共享采样器 (最多可以使用128张纹理)
- 纹理尺寸过大会导致短暂的卡顿,但不会降低帧率
- 像素着色器会对性能有非常大的影响,可以优化材质编辑器中的指令数(100~200)
- 屏幕输出的分辨率越大,复杂材质对性能的影响也越大
反射

反射捕获

反射捕获球:
屏幕空间反射

平面反射

反射性能提示
- 如果未经过Cook,反射捕获会在打开关卡时进行,导致加载变慢
- 反射捕获区域如果有很多重叠,会导致多次着色从而性能变差
- 反射捕获的分辨率可以在系统设置中调节
- 天空光为整个关卡提供了低成本的反射捕获
- 必要时才使用平面反射的实时捕获和SSR
光照
静态光源(Static Light)
是指在运行时不能以任何方式改变或移动的光源。它们仅在光照贴图中进行计算,一旦处理完成后,不会再有进一步的性能影响。可移动对象不能和静态光源进行交互,所以静态光源的用处是非常有限的。
可移动光源(Movable Lights)
产生完全动态的光照和阴影,可以改变光源位置、旋转度、颜色、亮度、衰减、半径等属性,几乎光源的任何属性都可以修改。
它们产生的光照不会烘焙到光照贴图中,也不会产生间接光照效果。
固定光源(Stationary Lights)
保持固定位置不变的光源,但可以在其他方面进行变更,例如亮度和颜色。 这是它们与静态光源的主要不同之处,静态光源无法在游戏时以任何方式进行变更。然而,应该注意的是,在运行时对亮度进行修改仅会影响直接光照。间接(反射)光照由于是通过Lightmass进行预计算的,所以不会改变。
静态光照和阴影
- 与反射一样,光照和阴影在实时计算也很困难
- 部分光照、阴影的计算会在预计算阶段完成,在runtime与实时光照结合
- 虚幻引擎中有数十种不同的光照和阴影方案


Volumetric LightMap 体积光照贴图
空间中一系列的点以球谐函数的形式保存当前位置的光照信息
质量
- 可以处理辐射和全局光照
- 真实的阴影效果包括软阴影
- 质量取决于Lightmap的分辨率和UV分布
- 由于UV布局的关系,光照还可能显示出接缝
- Lightmap分辨率有上限,巨大的模型可能效果不佳
- 一旦烘焙完成,在运行时静态的光源和物体无法移动,阴影也是静态的,每次移动静态物体都要重新Build
性能
- 在编辑器下预先计算,并将信息储存在Lightmap中
- 计算非常高效,但占用更多内存
- 需要一定的时间去预计算
- 每次修改光照和静态物体,需要重新构建光照
- 模型需要Lightmap UV,因此需要额外的步骤去处理
Lightmass
Lightmass 基础知识 | 虚幻引擎文档 (unrealengine.com)
- Lightmass是一个独立程序,由引擎编辑器在烘焙时调用
- 支持网络分布式渲染
- 渲染质量可以通过一些选项设置
- 记住功能:构建lightmap
GPULightmass
大大减少了计算、构建和生成复杂场景光照数据所需的时间,其速度可与基于CPU的Lightmass使用Swarm进行分布式构建时的速度相媲美。此外,GPULM提供具有交互性的新工作流,可以实时编辑场景、重新计算和重新构建光照。基于CPU的Lightmass系统无法使用此工作流。
静态光照的性能提示
- 静态光照总是以完全相同的速度渲染
- 无论有多少静态光源,烘焙之后的渲染速度是一样的
- Lightmap分辨率会影响内存,但不影响帧率
- 烘焙速度会受以下几点影响
- Lightmap分辨率
- 模型、光源数量烘焙选项
- 光照影响范围
动态光照和阴影
阴影
常规动态阴影
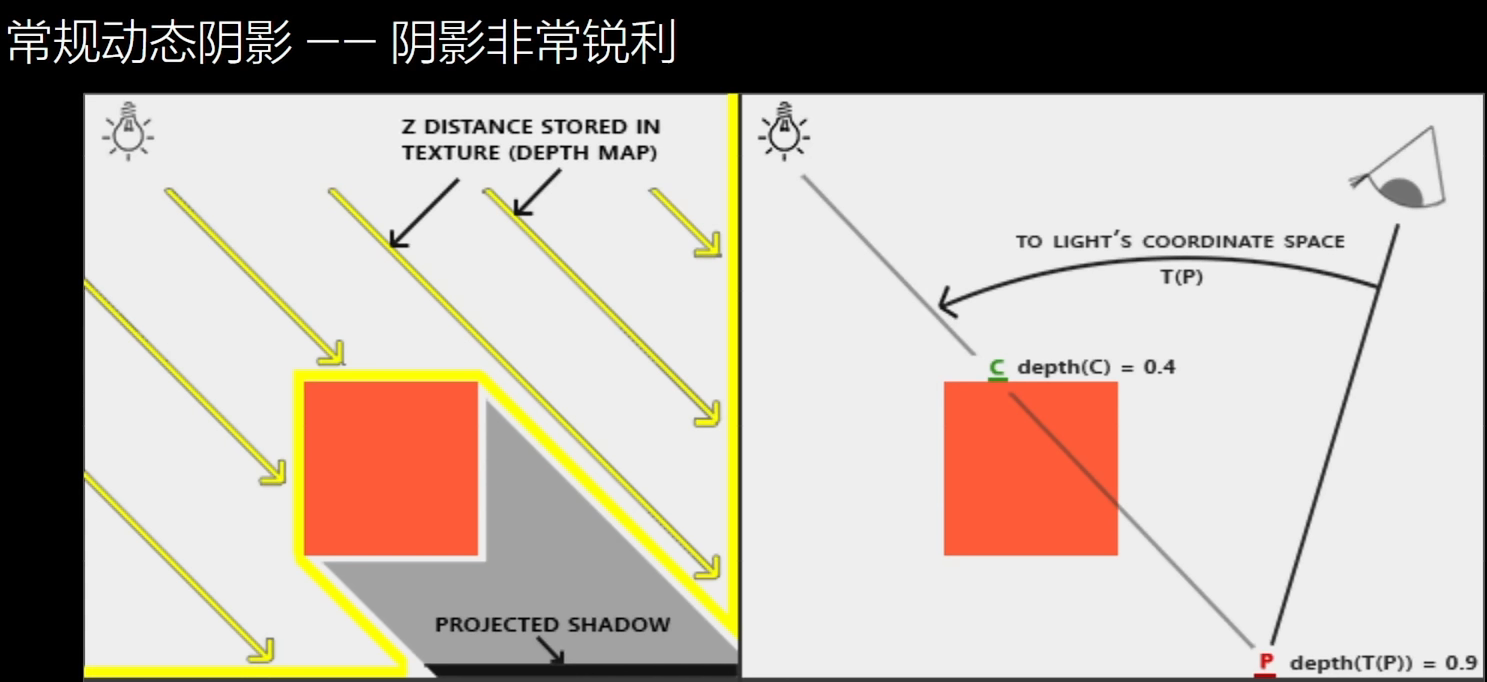
- shadowmap:以光的视角,将距离存入buffer
- 渲染P,将P转换到光源空间,计算光源到P的距离,但是距离光源最近的是点C,所以P被遮挡在阴影中。

Shadow Acne:由于阴影贴图分辨率不够造成,可以增加一个bias修正
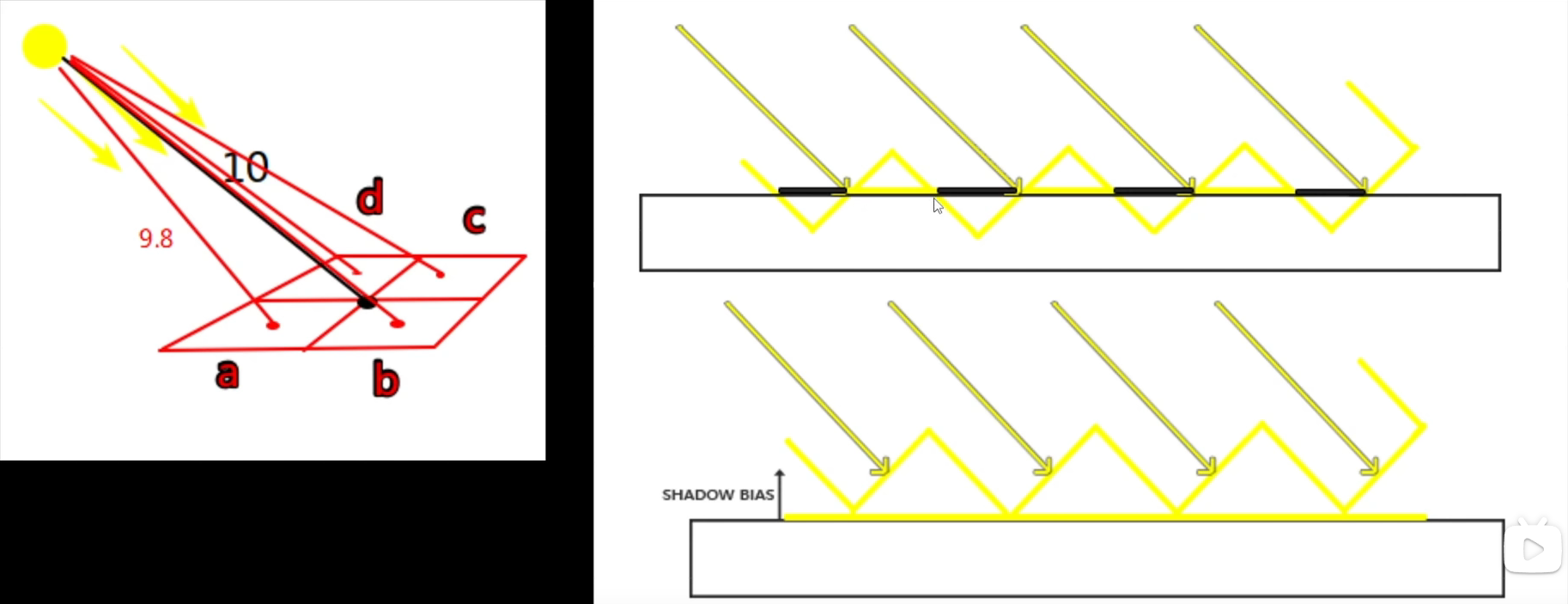
理解:abcd四个点由于分辨率不够只占了一个像素,距离光源最近点的距离被认为是10。a至光源9.8<10,c距离光源10.2>10,这就造成了,a在阴影值c不在阴影。交替产生,导致阴影失真。
级联阴影
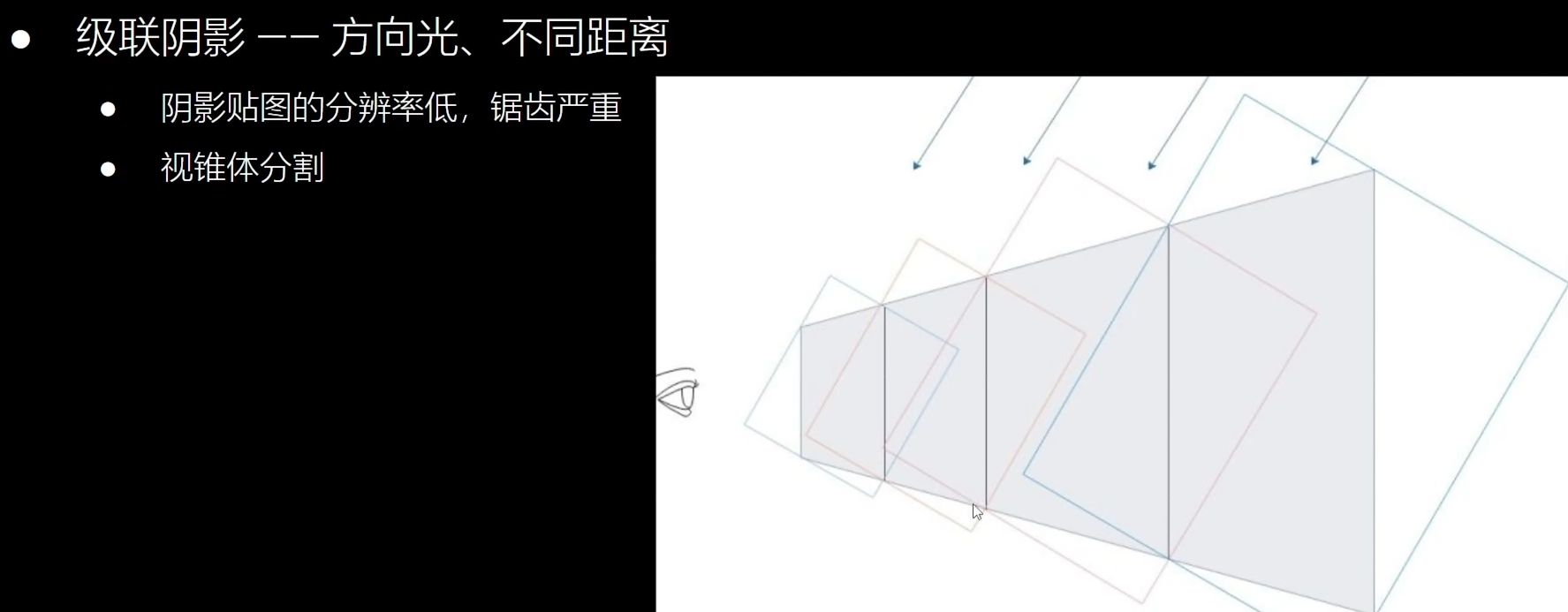
使用多张shadowmap,离相机近用高质量贴图,距离远用粗造的贴图。
逐对象阴影


由于光源固定,我们可以渲染每个物体的贴图,保证了分辨率
距离场阴影

- 由于需要直接光照,光源需是固定或可移动光源
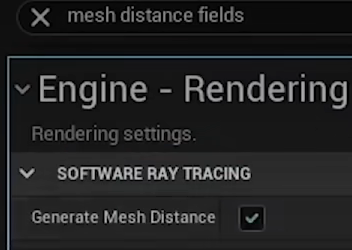
- 只对静态网格体有效,需离线生成Mesh Distance Field
- ue5中阴影生产顺序:CSM> DFS > Traditional Shadow
- 运行实时生成Global Distance Field
- Ray Marching
距离场:定义为任一点到场景中其他点最近的距离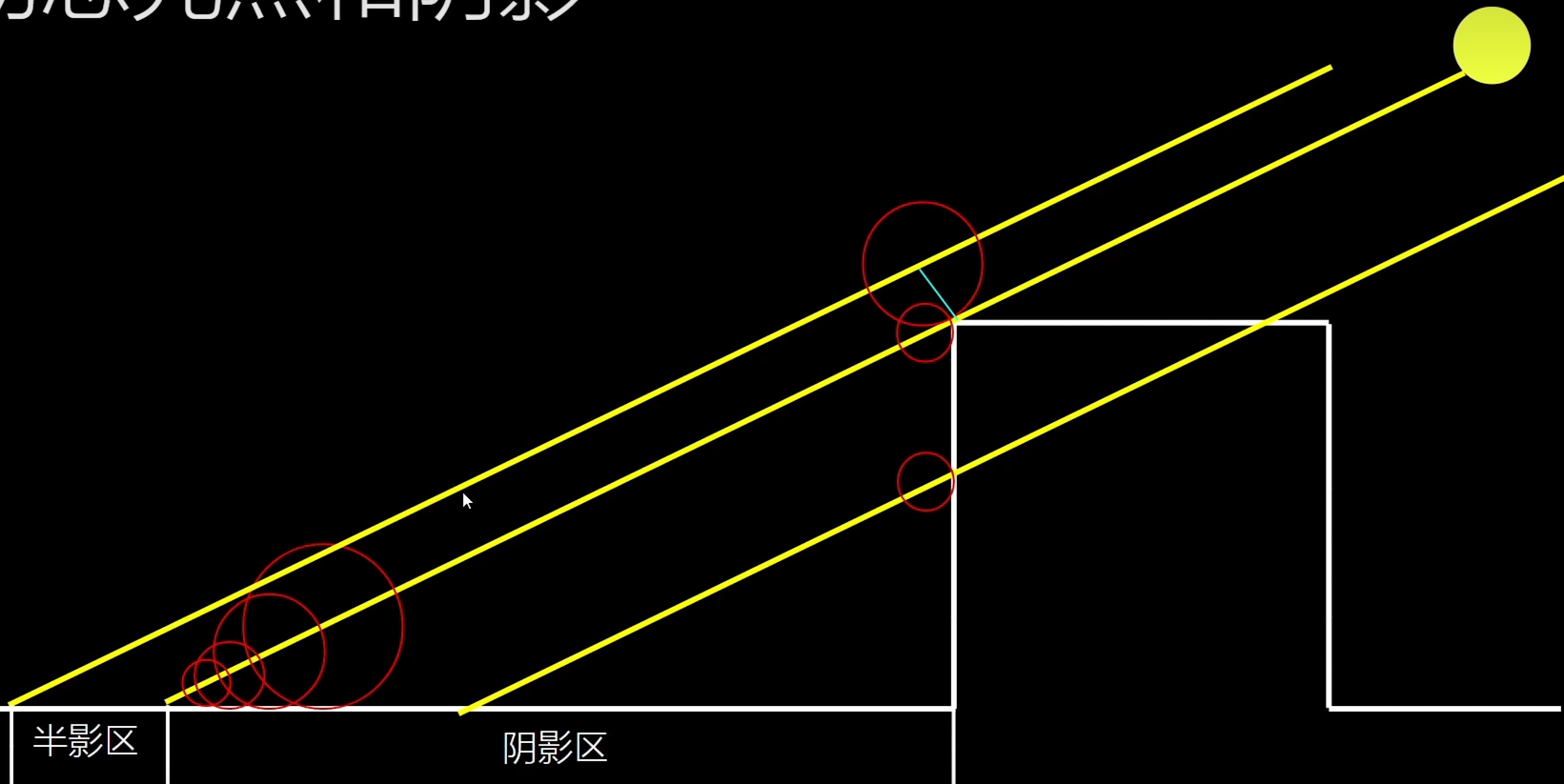
根据右边与高地距离的关系 ,确定阴影区。
第一条线:垂直,不是阴影
第二条线:相交,半影区界限
第三条线:相切,是阴影
其他类型
Contact Shadow:对于小的物体有较好的细节
Capsule Shadow:用简化的模型来渲染阴影
性能
- 渲染阴影的性能损耗大,通常需要降低渲染质量来补偿
- 动态光照不会对大部分的内容产生辐射或全局光照
- 照不会生成”真正的”软阴影
- 动态光照在场景中看起来更“真实”(闪烁等,光线非常锐利)
动态光照
- 使用像素着色器计算
- 点光源用一个球形模型来渲染,在球投影内像素会进行光照渲染
- 方向光对全屏像素渲染




动态光照性能提示
- 动态光照性能损耗很少,阴影损耗较高
- 像素越多性能越慢
- 光源离相机越近,受影响的像素越多,性能也就越慢
- 点光源半径需要尽可能小,避免重叠(重叠部分会重复计算)
Lumen和VSM
Lumen是虚幻引擎5全新的全动态全局光照和反射系统,而在ue4中全局光照是靠直接光照实现的,很难计算间接光找,ue4的间接光照都是粗略估算或是基于烘焙的全局光照。
Lumen使用了多种光线追踪方法来处理全局光照和反射
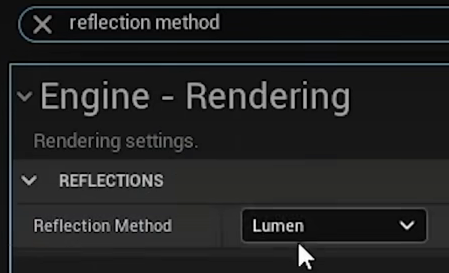
开启方式: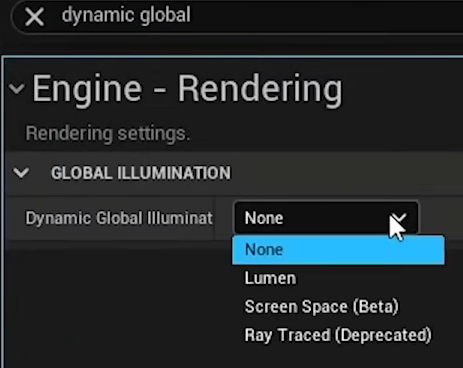
Lumen新特性:
Color bleeding:被照物体颜色影响周围表面颜色
Soft indirect shadow:
间接阴影可以使得没有受到直接光照的物体产生阴影,传统做法是使用AO贴图和屏幕空间AO算法粗略估算。UE5中,Lumen完全取代了ue4中的SSAO,消除了实时生成AO贴图的需求,并提供了精确且柔和的阴影。
Multi-bounce indirect illumination:
Lumen通过追踪前一帧的光照来计算当前帧的光照,光照结果是当前帧光照和前几帧光照混合的结果。
Emissive material
Skylight emissive
..略
Lumen实现方式:屏幕光线追踪+硬件光线追踪,生成有向距离场来加速追踪。通过采用表面缓存的方式来加速计算光照结果。启用Lumen反射会完全取代屏幕空间反射和光线追踪反射。
半透明
- 延迟渲染管线难以处理半透明材质
- 半透明渲染在渲染流程的后半段,使用前向渲染管线渲染半透明物体
后处理

性能调试

 微信
微信 支付宝
支付宝




